Prompt4Trust: A Reinforcement Learning Prompt Augmentation Framework for Clinically-Aligned Confidence Calibration in Multimodal Large Language Models
作者: Anita Kriz, Elizabeth Laura Janes, Xing Shen, Tal Arbel
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-07-12 (更新: 2025-10-13)
备注: Accepted to ICCV 2025 Workshop CVAMD
🔗 代码/项目: GITHUB
💡 一句话要点
提出Prompt4Trust以解决多模态大语言模型的信心校准问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 信心校准 强化学习 医学视觉问答 临床决策支持 自动化提示工程 零-shot泛化
📋 核心要点
- 现有多模态大语言模型在医疗应用中存在对提示设计敏感和高置信度错误响应的问题,影响其可靠性。
- Prompt4Trust框架通过强化学习生成上下文感知的辅助提示,旨在提高模型生成响应的准确性和信心校准。
- 在PMC-VQA基准测试中,该方法实现了医学视觉问答的最新性能,并展示了良好的零-shot泛化能力。
📝 摘要(中文)
多模态大语言模型(MLLMs)在医疗领域应用前景广阔,但其在安全关键环境中的部署受到两个主要限制:对提示设计的敏感性和高置信度下生成错误响应的倾向。为了解决这一问题,本文提出了Prompt4Trust,这是首个针对MLLMs信心校准的强化学习框架。该框架通过训练轻量级语言模型生成上下文感知的辅助提示,指导下游任务模型生成更准确的响应。实验表明,该方法在PMC-VQA基准上实现了医学视觉问答的最新性能,并在小型下游任务模型上展示了对更大模型的零-shot泛化潜力,表明其在计算成本上具有可扩展性。
🔬 方法详解
问题定义:本文旨在解决多模态大语言模型在医疗领域应用中的信心校准问题。现有方法在高置信度下可能生成错误响应,导致临床决策的不可靠性。
核心思路:Prompt4Trust框架通过训练轻量级语言模型生成辅助提示,帮助下游任务模型生成更准确的响应,从而提高信心校准的准确性。
技术框架:该框架包括两个主要模块:一是轻量级语言模型用于生成上下文感知的辅助提示,二是下游任务模型根据这些提示生成最终响应。整个流程通过强化学习进行优化。
关键创新:Prompt4Trust是首个专注于临床决策信心校准的强化学习框架,优先考虑安全和可靠性,而非传统的校准技术。
关键设计:在训练过程中,采用特定的损失函数来优化提示生成的质量,并通过上下文信息增强提示的相关性,确保下游模型生成的响应与实际预测准确性相符。
🖼️ 关键图片

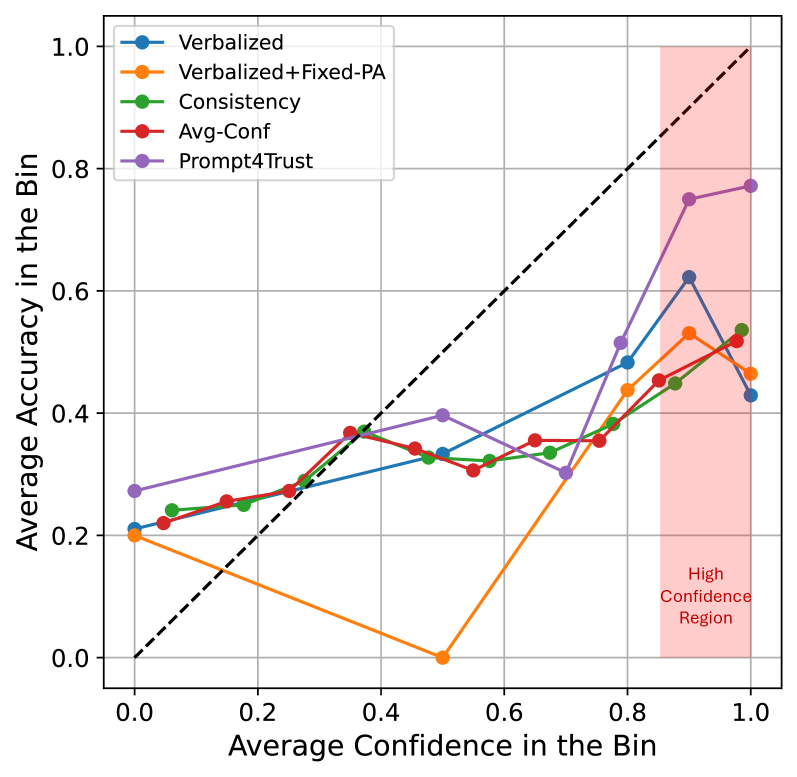

📊 实验亮点
在PMC-VQA基准测试中,Prompt4Trust框架实现了医学视觉问答的最新性能,显著提高了任务准确性。此外,该框架在小型下游任务模型上展示了良好的零-shot泛化能力,表明其在更大模型上的应用潜力。
🎯 应用场景
该研究的潜在应用领域包括医疗诊断、临床决策支持系统等。通过提高多模态大语言模型的信心校准能力,能够增强医生对模型预测的信任,从而在安全关键环境中更有效地应用人工智能技术,最终改善患者护理质量。
📄 摘要(原文)
Multimodal large language models (MLLMs) hold considerable promise for applications in healthcare. However, their deployment in safety-critical settings is hindered by two key limitations: (i) sensitivity to prompt design, and (ii) a tendency to generate incorrect responses with high confidence. As clinicians may rely on a model's stated confidence to gauge the reliability of its predictions, it is especially important that when a model expresses high confidence, it is also highly accurate. We introduce Prompt4Trust, the first reinforcement learning (RL) framework for prompt augmentation targeting confidence calibration in MLLMs. A lightweight LLM is trained to produce context-aware auxiliary prompts that guide a downstream task MLLM to generate responses in which the expressed confidence more accurately reflects predictive accuracy. Unlike conventional calibration techniques, Prompt4Trust specifically prioritizes aspects of calibration most critical for safe and trustworthy clinical decision-making. Beyond improvements driven by this clinically motivated calibration objective, our proposed method also improves task accuracy, achieving state-of-the-art medical visual question answering (VQA) performance on the PMC-VQA benchmark, which is composed of multiple-choice questions spanning diverse medical imaging modalities. Moreover, our framework trained with a small downstream task MLLM showed promising zero-shot generalization to larger MLLMs in our experiments, suggesting the potential for scalable calibration without the associated computational costs. This work demonstrates the potential of automated yet human-aligned prompt engineering for improving the the trustworthiness of MLLMs in safety critical settings. Our codebase can be found at https://github.com/xingbpshen/prompt4trust.