MCA-LLaVA: Manhattan Causal Attention for Reducing Hallucination in Large Vision-Language Models
作者: Qiyan Zhao, Xiaofeng Zhang, Yiheng Li, Yun Xing, Xiaosong Yuan, Feilong Tang, Sinan Fan, Xuhang Chen, Xuyao Zhang, Dahan Wang
分类: cs.CV
发布日期: 2025-07-12 (更新: 2025-07-23)
备注: Accepted in ACM MM 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出MCA-LLaVA,缓解大视觉语言模型中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大视觉语言模型 幻觉缓解 多模态对齐 位置编码 曼哈顿距离
📋 核心要点
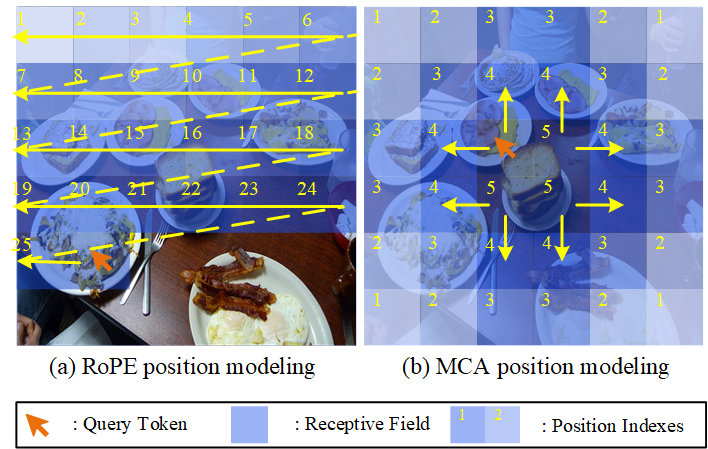
- 现有LVLM由于旋转位置编码的长期衰减,导致指令对图像不同位置的感知存在偏差,影响多模态对齐。
- 提出MCA-LLaVA,利用曼哈顿距离将位置编码扩展到二维空间,缓解图像对齐偏差,提升指令对图像的感知。
- 实验表明,MCA-LLaVA在多种幻觉和通用基准测试中表现出有效性和通用性,能够有效缓解幻觉问题。
📝 摘要(中文)
大视觉语言模型(LVLMs)中的幻觉是一个重要的挑战,多模态特征之间的不对齐是关键因素。本文揭示了LVLMs中用于位置建模的旋转位置编码(RoPE)的长期衰减对多模态对齐的负面影响。具体来说,在长期衰减下,指令token对图像token的感知是不均匀的,优先感知来自右下角区域的图像token,因为在1D序列中,这些token在位置上更接近指令token。这种有偏差的感知导致图像-指令交互不足和次优的多模态对齐。我们将这种现象称为图像对齐偏差。为了增强指令对不同空间位置的图像token的感知,我们提出了基于曼哈顿距离的MCA-LLaVA,它将长期衰减扩展到二维、多方向的空间衰减。MCA-LLaVA集成了图像token的一维序列顺序和二维空间位置进行位置建模,通过减轻图像对齐偏差来缓解幻觉。MCA-LLaVA在各种幻觉和通用基准测试中的实验结果证明了其有效性和通用性。
🔬 方法详解
问题定义:论文旨在解决大视觉语言模型(LVLMs)中存在的幻觉问题。现有方法,特别是依赖旋转位置编码(RoPE)的LVLMs,由于RoPE的长期衰减特性,导致模型在处理图像时产生“图像对齐偏差”。具体表现为,模型更倾向于关注图像右下角的区域,而忽略其他区域的信息,从而造成多模态特征不对齐,最终导致幻觉的产生。
核心思路:论文的核心思路是缓解由RoPE长期衰减引起的图像对齐偏差。通过引入基于曼哈顿距离的二维空间衰减,使模型能够更均匀地感知图像中不同位置的token。这种方法旨在增强指令token与图像token之间的交互,从而改善多模态对齐,减少幻觉。
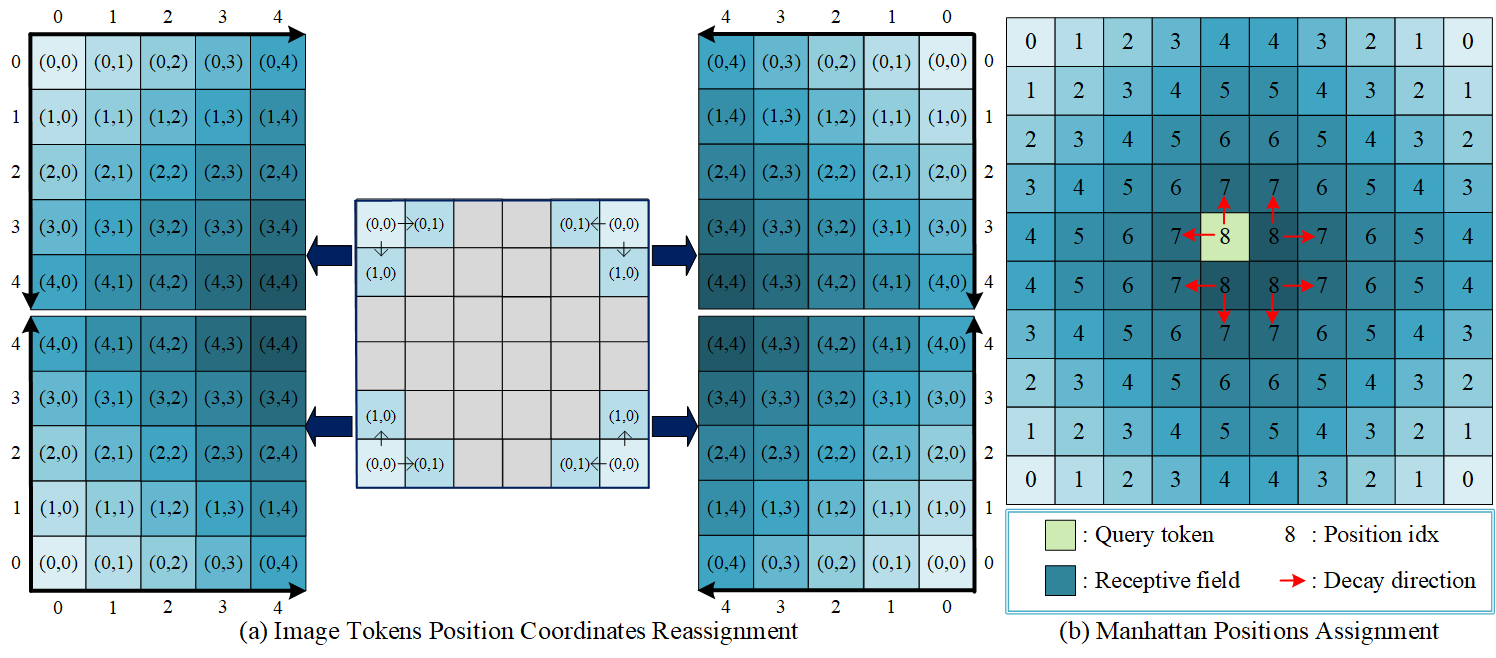
技术框架:MCA-LLaVA的核心在于改进了位置编码方式。它没有改变LVLM的整体架构,而是专注于替换原有的RoPE。MCA-LLaVA将图像token的一维序列位置信息和二维空间位置信息结合起来,用于位置建模。具体来说,它利用曼哈顿距离来计算图像token之间的空间关系,并将其融入到位置编码中。
关键创新:关键创新在于提出了基于曼哈顿距离的二维空间衰减位置编码方法。与传统的RoPE相比,MCA-LLaVA能够更好地捕捉图像token之间的空间关系,从而缓解图像对齐偏差。这种方法不仅考虑了token在序列中的位置,还考虑了它们在图像中的实际空间位置,从而实现了更准确的位置建模。
关键设计:MCA-LLaVA的关键设计在于曼哈顿距离的计算和应用。具体来说,对于图像中的每个token,MCA-LLaVA计算其与其他token之间的曼哈顿距离,并使用这些距离来调整位置编码。这种调整使得模型能够更均匀地感知图像中不同位置的token。此外,MCA-LLaVA还保留了原始RoPE中的一维序列位置信息,以确保模型能够理解token的顺序关系。论文未提供损失函数和网络结构的具体修改细节,可能沿用了LLaVA原有的设置。
🖼️ 关键图片

📊 实验亮点
MCA-LLaVA在多个幻觉和通用基准测试中取得了显著的改进。具体性能数据和对比基线在论文中给出,证明了其在缓解幻觉方面的有效性和通用性。实验结果表明,MCA-LLaVA能够显著减少模型产生的错误或不相关的描述,提高生成内容的准确性和一致性。
🎯 应用场景
MCA-LLaVA的潜在应用领域包括图像描述生成、视觉问答、图像编辑等。通过减少LVLM中的幻觉,可以提高这些应用的可信度和实用性。该研究对于提升多模态模型的可靠性和安全性具有重要意义,尤其是在需要精确理解图像内容的场景下,例如医疗影像分析、自动驾驶等。
📄 摘要(原文)
Hallucinations pose a significant challenge in Large Vision Language Models (LVLMs), with misalignment between multimodal features identified as a key contributing factor. This paper reveals the negative impact of the long-term decay in Rotary Position Encoding (RoPE), used for positional modeling in LVLMs, on multimodal alignment. Concretely, under long-term decay, instruction tokens exhibit uneven perception of image tokens located at different positions within the two-dimensional space: prioritizing image tokens from the bottom-right region since in the one-dimensional sequence, these tokens are positionally closer to the instruction tokens. This biased perception leads to insufficient image-instruction interaction and suboptimal multimodal alignment. We refer to this phenomenon as image alignment bias. To enhance instruction's perception of image tokens at different spatial locations, we propose MCA-LLaVA, based on Manhattan distance, which extends the long-term decay to a two-dimensional, multi-directional spatial decay. MCA-LLaVA integrates the one-dimensional sequence order and two-dimensional spatial position of image tokens for positional modeling, mitigating hallucinations by alleviating image alignment bias. Experimental results of MCA-LLaVA across various hallucination and general benchmarks demonstrate its effectiveness and generality. The code can be accessed in https://github.com/ErikZ719/MCA-LLaVA.