Multimodal Visual Transformer for Sim2real Transfer in Visual Reinforcement Learning
作者: Zichun Xu, Yuntao Li, Zhaomin Wang, Lei Zhuang, Guocai Yang, Jingdong Zhao
分类: cs.CV, cs.RO
发布日期: 2025-07-12 (更新: 2025-08-11)
💡 一句话要点
提出基于多模态视觉Transformer的Sim2Real迁移学习方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉强化学习 Sim2Real迁移 多模态融合 视觉Transformer 深度信息
📋 核心要点
- 现有方法在视觉强化学习中泛化性不足,难以应对真实场景中的外观变化和三维空间信息。
- 提出一种基于视觉Transformer的多模态融合方法,结合RGB和深度信息,提升模型对场景变化的鲁棒性。
- 实验结果表明,该方法在仿真环境中表现出更好的泛化能力,并通过Sim2Real迁移验证了其在真实世界操作任务中的可行性。
📝 摘要(中文)
本文提出了一种基于视觉Transformer的多模态视觉骨干网络,用于融合RGB和深度信息,以增强视觉强化学习中的泛化能力。该方法首先使用独立的CNN分支处理不同模态的信息,然后将卷积特征输入到可扩展的视觉Transformer中,以获得视觉表征。此外,设计了一种基于掩码和非掩码token的对比无监督学习方案,以加速强化学习过程中的样本效率。仿真结果表明,我们的视觉骨干网络可以更多地关注与任务相关的区域,并在未见过的场景中表现出更好的泛化能力。对于Sim2Real迁移,开发了一种灵活的课程学习策略,以在训练过程中部署领域随机化。最后,通过零样本迁移验证了我们的模型在执行真实世界操作任务中的可行性。
🔬 方法详解
问题定义:现有的视觉强化学习方法在Sim2Real迁移中面临泛化性挑战。真实场景与仿真环境存在差异,例如光照、纹理等外观变化,以及三维空间信息的缺失,导致模型在仿真环境中学习到的策略难以直接应用于真实世界。因此,如何提高模型对场景变化的鲁棒性,是Sim2Real迁移的关键问题。
核心思路:论文的核心思路是利用深度信息来增强模型的泛化能力。深度信息对场景外观变化不敏感,并且能够提供三维空间细节。通过融合RGB和深度信息,模型可以学习到更加鲁棒的视觉表征,从而提高在未见过的场景中的泛化能力。此外,使用视觉Transformer来建模长距离依赖关系,并采用对比学习来提升样本效率。
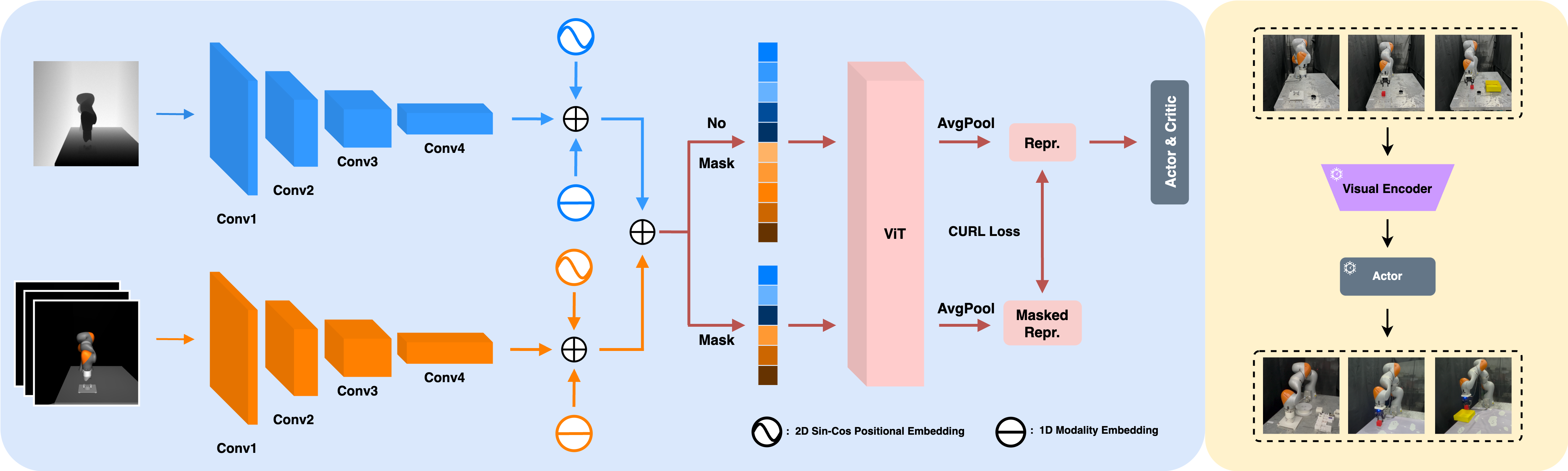
技术框架:整体框架包括三个主要模块:1) 多模态特征提取:使用独立的CNN分支分别提取RGB和深度信息的特征。2) 视觉Transformer编码:将提取的特征输入到视觉Transformer中,进行融合和编码,得到视觉表征。3) 强化学习策略优化:使用强化学习算法,例如PPO,根据视觉表征学习控制策略。此外,还包括一个对比学习模块,用于预训练视觉Transformer。
关键创新:论文的关键创新在于多模态视觉Transformer的设计和对比学习方案的应用。多模态视觉Transformer能够有效地融合RGB和深度信息,学习到更加鲁棒的视觉表征。对比学习方案通过掩码和非掩码token的学习,提高了样本效率,加速了强化学习过程。与现有方法相比,该方法能够更好地利用深度信息,提高模型的泛化能力。
关键设计:在多模态特征提取阶段,使用了预训练的ResNet作为CNN分支。在视觉Transformer中,使用了多头注意力机制和位置编码。对比学习损失函数采用了InfoNCE损失。在Sim2Real迁移中,采用了课程学习策略,逐步增加领域随机化的程度。具体参数设置包括Transformer的层数、头数、隐藏层维度,以及对比学习的温度系数等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在仿真环境中取得了显著的性能提升,相比于基线方法,在未见过的场景中表现出更好的泛化能力。通过Sim2Real迁移,该方法成功地将仿真环境中学习到的策略应用于真实世界的机器人操作任务,验证了其可行性。具体的性能数据和提升幅度在论文中有详细的展示。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶、虚拟现实等领域。例如,可以用于训练机器人在复杂环境中的抓取、放置等操作任务,提高机器人的自主性和适应性。在自动驾驶领域,可以用于提高车辆对不同天气、光照条件下的感知能力,增强驾驶安全性。在虚拟现实领域,可以用于生成更加逼真的虚拟环境,提升用户体验。
📄 摘要(原文)
Depth information is robust to scene appearance variations and inherently carries 3D spatial details. In this paper, a visual backbone based on the vision transformer is proposed to fuse RGB and depth modalities for enhancing generalization. Different modalities are first processed by separate CNN stems, and the combined convolutional features are delivered to the scalable vision transformer to obtain visual representations. Moreover, a contrastive unsupervised learning scheme is designed with masked and unmasked tokens to accelerate the sample efficiency during the reinforcement learning process. Simulation results demonstrate that our visual backbone can focus more on task-related regions and exhibit better generalization in unseen scenarios. For sim2real transfer, a flexible curriculum learning schedule is developed to deploy domain randomization over training processes. Finally, the feasibility of our model is validated to perform real-world manipulation tasks via zero-shot transfer.