Taming generative video models for zero-shot optical flow extraction
作者: Seungwoo Kim, Khai Loong Aw, Klemen Kotar, Cristobal Eyzaguirre, Wanhee Lee, Yunong Liu, Jared Watrous, Stefan Stojanov, Juan Carlos Niebles, Jiajun Wu, Daniel L. K. Yamins
分类: cs.CV
发布日期: 2025-07-11 (更新: 2025-11-27)
备注: Project webpage: https://neuroailab.github.io/projects/kl_tracing
💡 一句话要点
提出KL-tracing,利用生成视频模型零样本提取光流,性能媲美专用模型。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 光流提取 生成视频模型 零样本学习 反事实推理 KL散度
📋 核心要点
- 现有光流提取方法依赖大量标注数据或合成数据,存在标注成本高昂和sim-to-real差距大的问题。
- 论文提出KL-tracing方法,通过在生成视频模型中注入扰动并追踪其传播,实现零样本光流提取。
- 实验表明,该方法在真实和合成数据集上均表现出色,无需微调即可与SOTA模型竞争。
📝 摘要(中文)
本文致力于解决从视频中提取光流这一核心计算机视觉问题。受大型通用模型成功的启发,我们探索了是否可以在不进行微调的情况下,仅通过提示冻结的自监督视频模型(训练目标为预测未来帧)来输出光流。先前尝试从视频生成器中读取深度或光照信息需要微调,但这种策略不适用于光流,因为标记数据稀缺,且合成数据集存在严重的sim-to-real差距。受反事实世界模型(CWM)范式的启发,该范式通过将小的示踪扰动注入到下一帧预测器中并跟踪其传播来获得逐点对应关系,我们将此想法扩展到生成视频模型,以实现零样本光流提取。我们探索了几种流行的架构,发现以这种方式成功进行零样本光流提取有赖于三个模型属性:(1)未来帧的分布预测(避免模糊或嘈杂的输出);(2)将每个时空patch独立处理的分解潜在空间;(3)可以调节任何未来像素子集的随机访问解码。这些属性在最近引入的局部随机访问序列(LRAS)架构中是独一无二的。在LRAS的基础上,我们提出KL-tracing:一种新颖的测试时推理程序,将局部扰动注入到第一帧中,单步展开模型,并计算扰动和未扰动预测分布之间的Kullback-Leibler散度。在没有任何特定于光流的微调的情况下,我们的方法在真实世界的TAP-Vid DAVIS基准和合成的TAP-Vid Kubric上与最先进的、特定于任务的模型相比具有竞争力。我们的结果表明,对可控生成视频模型进行反事实提示是高质量光流的监督或光度损失方法的有效替代方案。
🔬 方法详解
问题定义:论文旨在解决在缺乏标注数据的情况下,如何从视频中准确提取光流的问题。现有方法,如监督学习或基于光度一致性的方法,要么依赖于大量的标注数据,要么在合成数据上训练后迁移到真实场景时性能下降,存在严重的sim-to-real差距。
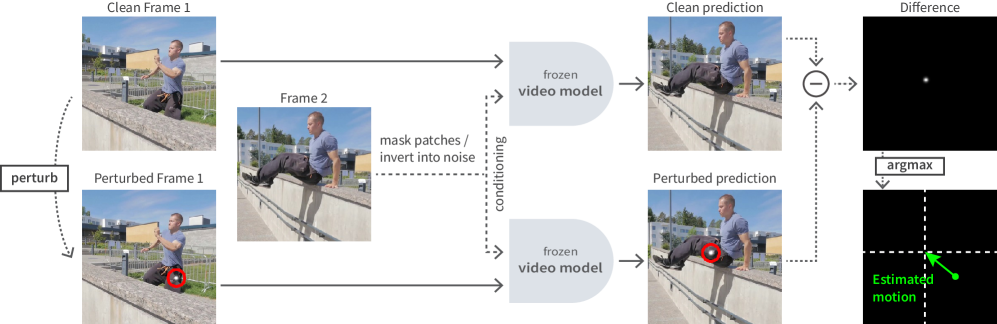
核心思路:论文的核心思路是利用预训练的生成视频模型,通过反事实推理的方式,在输入图像中引入微小扰动,观察该扰动在后续帧中的传播,从而推断出像素之间的运动关系,即光流。这种方法无需额外的光流标注数据,实现了零样本光流提取。
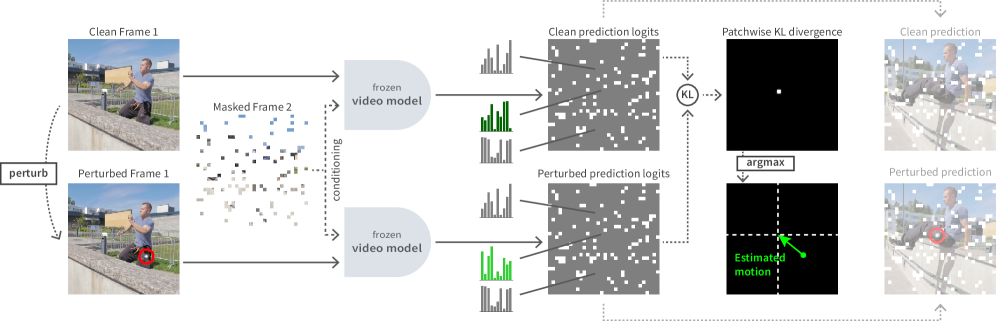
技术框架:整体流程如下:1. 选择一个预训练的生成视频模型,特别是具有分布预测、分解潜在空间和随机访问解码能力的模型,如LRAS。2. 将第一帧图像输入模型。3. 在第一帧图像中注入一个局部扰动。4. 使用模型预测下一帧,分别预测扰动和未扰动两种情况下的下一帧。5. 计算扰动和未扰动预测分布之间的Kullback-Leibler (KL) 散度。KL散度可以反映扰动在像素间的传播,从而估计光流。
关键创新:论文的关键创新在于提出了KL-tracing方法,将反事实推理的思想应用于生成视频模型,实现了零样本光流提取。与以往需要微调的方法不同,该方法直接利用预训练模型的生成能力,避免了对光流标注数据的依赖。此外,论文还强调了生成视频模型的三个关键属性:分布预测、分解潜在空间和随机访问解码,这些属性对于成功进行零样本光流提取至关重要。
关键设计:KL-tracing的关键设计在于使用KL散度来衡量扰动在像素间的传播。具体来说,假设p(x)是未扰动情况下下一帧像素x的预测分布,q(x)是扰动情况下下一帧像素x的预测分布,则KL散度定义为D_KL(q||p) = Σ q(x) log(q(x)/p(x))。KL散度越大,表示扰动对该像素的影响越大,从而可以推断出该像素与扰动像素之间的运动关系。论文选择LRAS作为基础模型,因为它具有上述三个关键属性,并且能够生成高质量的视频帧。
🖼️ 关键图片
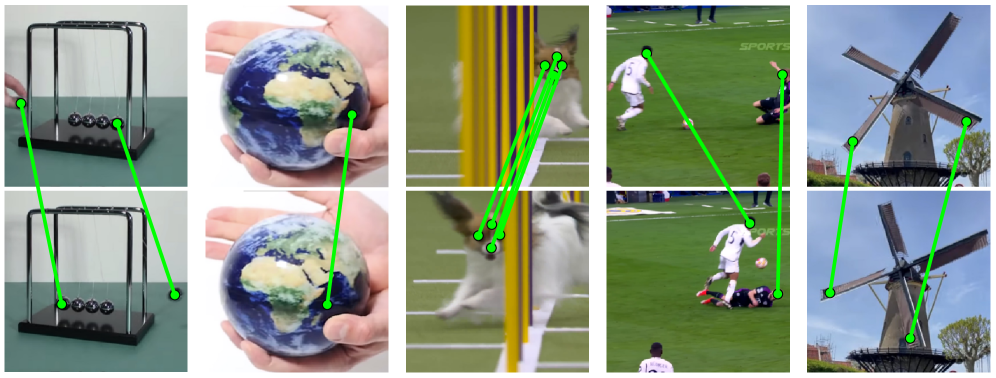
📊 实验亮点
实验结果表明,KL-tracing方法在TAP-Vid DAVIS和TAP-Vid Kubric数据集上取得了与最先进的特定任务模型相竞争的性能,而无需任何光流数据的微调。例如,在TAP-Vid DAVIS数据集上,该方法在某些指标上甚至超过了部分监督学习方法,证明了其在真实场景中的有效性。
🎯 应用场景
该研究成果可应用于自动驾驶、视频监控、机器人导航等领域,这些领域需要准确的光流信息来进行运动估计、场景理解和目标跟踪。零样本光流提取的能力降低了对标注数据的依赖,使得该方法更易于部署到新的场景中。未来,该方法可以进一步扩展到其他视觉任务,如深度估计和三维重建。
📄 摘要(原文)
Extracting optical flow from videos remains a core computer vision problem. Motivated by the recent success of large general-purpose models, we ask whether frozen self-supervised video models trained only to predict future frames can be prompted, without fine-tuning, to output flow. Prior attempts to read out depth or illumination from video generators required fine-tuning; that strategy is ill-suited for flow, where labeled data is scarce and synthetic datasets suffer from a sim-to-real gap. Inspired by the Counterfactual World Model (CWM) paradigm, which can obtain point-wise correspondences by injecting a small tracer perturbation into a next-frame predictor and tracking its propagation, we extend this idea to generative video models for zero-shot flow extraction. We explore several popular architectures and find that successful zero-shot flow extraction in this manner is aided by three model properties: (1) distributional prediction of future frames (avoiding blurry or noisy outputs); (2) factorized latents that treat each spatio-temporal patch independently; and (3) random-access decoding that can condition on any subset of future pixels. These properties are uniquely present in the recently introduced Local Random Access Sequence (LRAS) architecture. Building on LRAS, we propose KL-tracing: a novel test-time inference procedure that injects a localized perturbation into the first frame, rolls out the model one step, and computes the Kullback-Leibler divergence between perturbed and unperturbed predictive distributions. Without any flow-specific fine-tuning, our method is competitive with state-of-the-art, task-specific models on the real-world TAP-Vid DAVIS benchmark and the synthetic TAP-Vid Kubric. Our results show that counterfactual prompting of controllable generative video models is an effective alternative to supervised or photometric-loss methods for high-quality flow.