From One to More: Contextual Part Latents for 3D Generation
作者: Shaocong Dong, Lihe Ding, Xiao Chen, Yaokun Li, Yuxin Wang, Yucheng Wang, Qi Wang, Jaehyeok Kim, Chenjian Gao, Zhanpeng Huang, Zibin Wang, Tianfan Xue, Dan Xu
分类: cs.CV
发布日期: 2025-07-11 (更新: 2025-10-30)
备注: Project page: https://copart3d.github.io/
💡 一句话要点
提出CoPart框架,通过上下文部件潜在表示实现可控3D生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D生成 扩散模型 部件感知 上下文建模 可控生成
📋 核心要点
- 现有3D生成方法难以捕捉复杂多部件几何结构,导致细节退化,且缺乏对部件间关系的建模。
- CoPart框架将3D对象分解为上下文部件潜在表示,显式建模部件关系,并支持部件级别的控制。
- 通过互指导策略微调预训练扩散模型,并构建Partverse数据集进行训练,实验证明CoPart具有卓越的性能。
📝 摘要(中文)
本文提出了一种基于部件感知的扩散框架CoPart,用于连贯的多部件3D生成。现有的3D生成方法通常采用单潜在表示,难以捕捉复杂的多部件几何结构,导致细节退化;整体潜在编码忽略了部件的独立性和相互关系,这对于组合设计至关重要;全局调节机制缺乏细粒度的可控性。CoPart将3D对象分解为上下文部件潜在表示,从而降低了编码复杂性,实现了显式的部件关系建模,并支持部件级别的调节。此外,还提出了一种互指导策略,用于微调预训练的扩散模型,以实现联合部件潜在去噪,确保几何连贯性和基础模型先验。为了支持大规模训练,构建了一个名为Partverse的新型3D部件数据集,该数据集通过自动网格分割和人工验证标注从Objaverse派生而来。大量实验表明,CoPart在部件级编辑、铰接对象生成和场景组合方面具有卓越的能力和前所未有的可控性。
🔬 方法详解
问题定义:现有3D生成方法主要存在三个痛点:一是使用单一潜在表示难以捕捉复杂的多部件几何结构,导致生成细节的退化;二是整体的潜在编码忽略了部件之间的独立性和相互关系,不利于进行组合设计;三是全局的调节机制缺乏细粒度的可控性。这些问题限制了3D生成在复杂场景和可控编辑方面的应用。
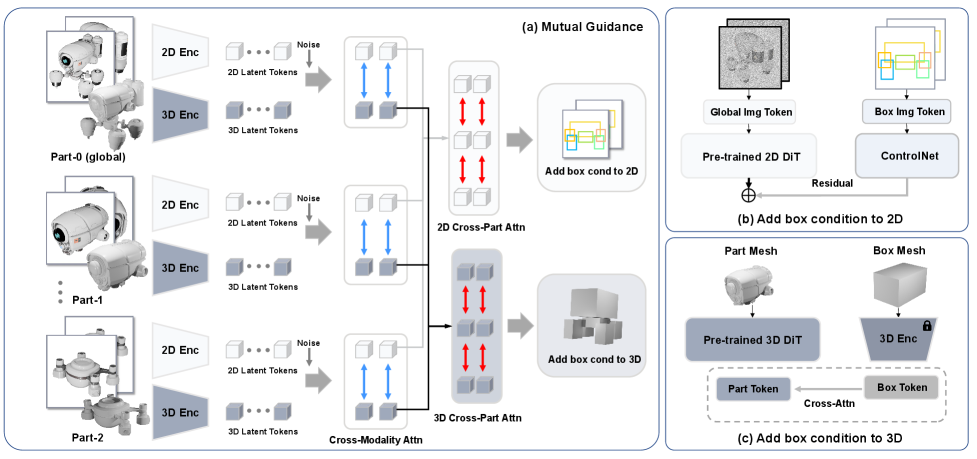
核心思路:CoPart的核心思路是将3D对象分解为多个上下文相关的部件潜在表示。通过对每个部件进行单独编码,降低了编码的复杂性,并且能够显式地建模部件之间的关系。此外,部件级别的表示也使得用户可以对每个部件进行单独的控制,从而实现细粒度的编辑和生成。
技术框架:CoPart框架主要包含以下几个模块:1) 部件分割模块,用于将3D对象分割成多个部件;2) 部件编码器,用于将每个部件编码成潜在表示;3) 上下文建模模块,用于建模部件之间的关系;4) 扩散模型,用于从潜在表示生成3D部件;5) 互指导策略,用于微调扩散模型。整体流程是,首先将3D对象分割成多个部件,然后使用部件编码器将每个部件编码成潜在表示,接着使用上下文建模模块建模部件之间的关系,最后使用扩散模型从潜在表示生成3D部件。
关键创新:CoPart的关键创新在于提出了部件感知的扩散框架,通过将3D对象分解为多个上下文相关的部件潜在表示,实现了对复杂多部件几何结构的有效建模和细粒度的控制。与现有方法相比,CoPart能够更好地捕捉部件之间的关系,并且支持部件级别的编辑和生成。
关键设计:CoPart的关键设计包括:1) 使用预训练的扩散模型作为生成器,以利用其强大的生成能力;2) 设计了一种互指导策略,用于微调扩散模型,以确保生成的部件在几何上是连贯的,并且符合基础模型的先验知识;3) 构建了一个名为Partverse的大规模3D部件数据集,用于训练CoPart框架。损失函数包括扩散模型的标准损失函数,以及用于约束部件之间关系的损失函数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,CoPart在部件级编辑、铰接对象生成和场景组合方面都取得了显著的性能提升。与现有方法相比,CoPart能够生成更逼真、更连贯的3D模型,并且支持更灵活的编辑和控制。例如,在部件级编辑任务中,CoPart能够生成与用户指定的编辑指令一致的3D模型,并且保持模型的整体结构和风格。
🎯 应用场景
CoPart框架在3D内容创作、游戏开发、虚拟现实和增强现实等领域具有广泛的应用前景。它可以用于生成具有复杂几何结构和丰富细节的3D模型,支持用户对3D模型进行细粒度的编辑和定制,并且可以用于生成各种类型的3D场景,例如室内场景、室外场景和虚拟世界。
📄 摘要(原文)
Recent advances in 3D generation have transitioned from multi-view 2D rendering approaches to 3D-native latent diffusion frameworks that exploit geometric priors in ground truth data. Despite progress, three key limitations persist: (1) Single-latent representations fail to capture complex multi-part geometries, causing detail degradation; (2) Holistic latent coding neglects part independence and interrelationships critical for compositional design; (3) Global conditioning mechanisms lack fine-grained controllability. Inspired by human 3D design workflows, we propose CoPart - a part-aware diffusion framework that decomposes 3D objects into contextual part latents for coherent multi-part generation. This paradigm offers three advantages: i) Reduces encoding complexity through part decomposition; ii) Enables explicit part relationship modeling; iii) Supports part-level conditioning. We further develop a mutual guidance strategy to fine-tune pre-trained diffusion models for joint part latent denoising, ensuring both geometric coherence and foundation model priors. To enable large-scale training, we construct Partverse - a novel 3D part dataset derived from Objaverse through automated mesh segmentation and human-verified annotations. Extensive experiments demonstrate CoPart's superior capabilities in part-level editing, articulated object generation, and scene composition with unprecedented controllability.