One Graph to Track Them All: Dynamic GNNs for Single- and Multi-View Tracking
作者: Martin Engilberge, Ivan Vrkic, Friedrich Wilke Grosche, Julien Pilet, Engin Turetken, Pascal Fua
分类: cs.CV
发布日期: 2025-07-11 (更新: 2025-12-30)
💡 一句话要点
提出基于动态图神经网络的统一多目标跟踪模型,无需预计算轨迹片段。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱八:物理动画 (Physics-based Animation)
关键词: 多目标跟踪 图神经网络 动态图 时空建模 遮挡处理
📋 核心要点
- 现有方法依赖预计算的轨迹片段,限制了信息传播和遮挡处理能力。
- 构建动态时空图,聚合多维度信息,实现序列间无缝信息传递,提升遮挡鲁棒性。
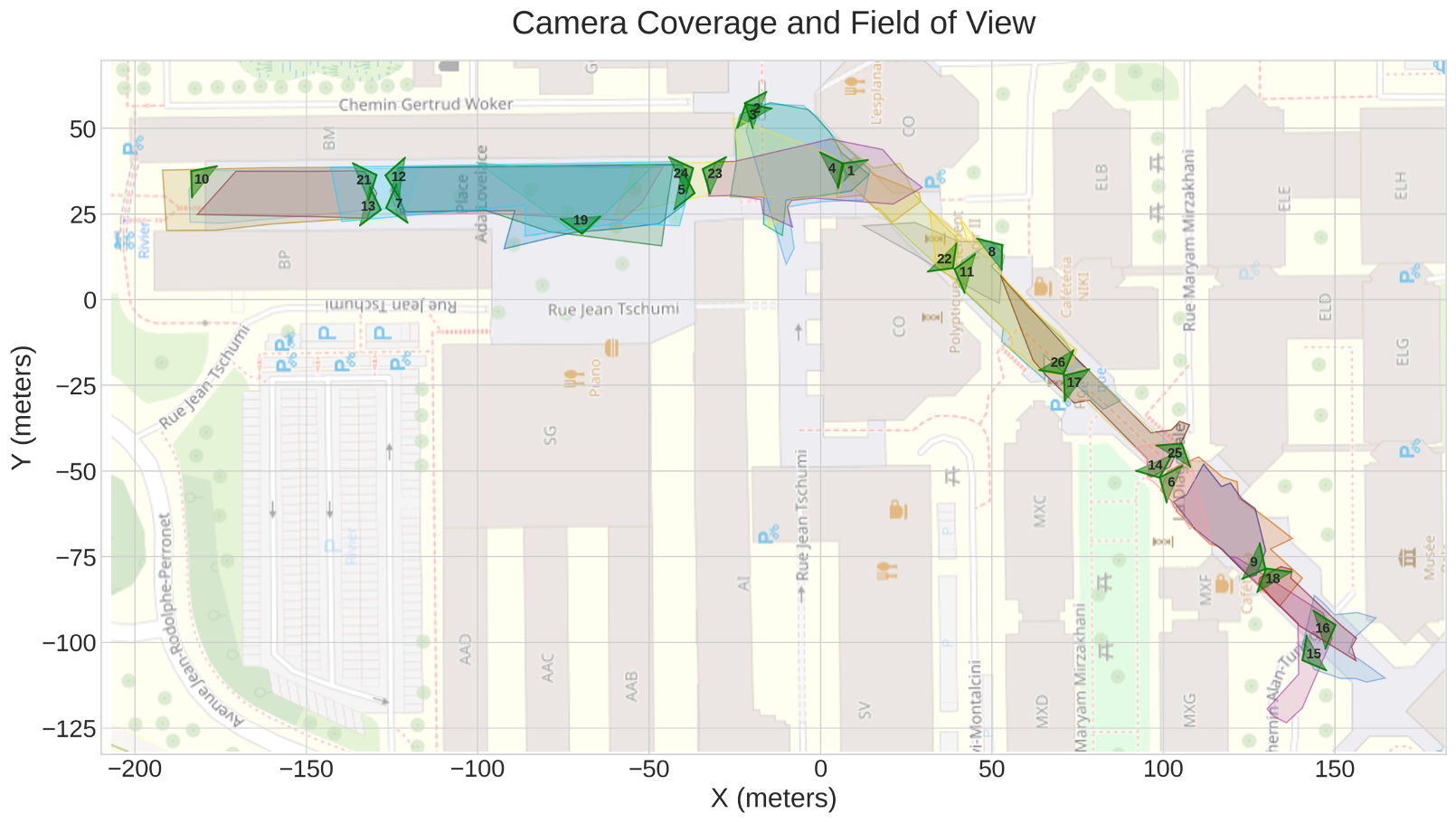
- 新数据集包含多视角、场景重建和大量遮挡,实验证明模型在多个数据集上达到SOTA。
📝 摘要(中文)
本文提出了一种统一的、完全可微的多目标跟踪模型,该模型学习将检测结果关联成轨迹,而无需依赖预先计算的轨迹片段。该模型构建了一个动态时空图,聚合了空间、上下文和时间信息,从而能够在整个序列中无缝地传播信息。为了改善遮挡处理,该图还可以编码特定场景的信息。此外,我们还引入了一个新的大规模数据集,包含25个部分重叠的视角、详细的场景重建和大量的遮挡。实验表明,该模型在公共基准和新数据集上均实现了最先进的性能,并且在各种条件下都具有灵活性。数据集和方法都将公开发布,以促进多目标跟踪的研究。
🔬 方法详解
问题定义:多目标跟踪(MOT)旨在识别视频序列中多个目标的身份并生成轨迹。现有方法通常依赖于预先计算的轨迹片段(tracklets),这限制了模型在长序列中进行信息传播的能力,并且难以有效处理遮挡情况。此外,许多方法缺乏对场景信息的有效利用,进一步降低了跟踪的准确性。
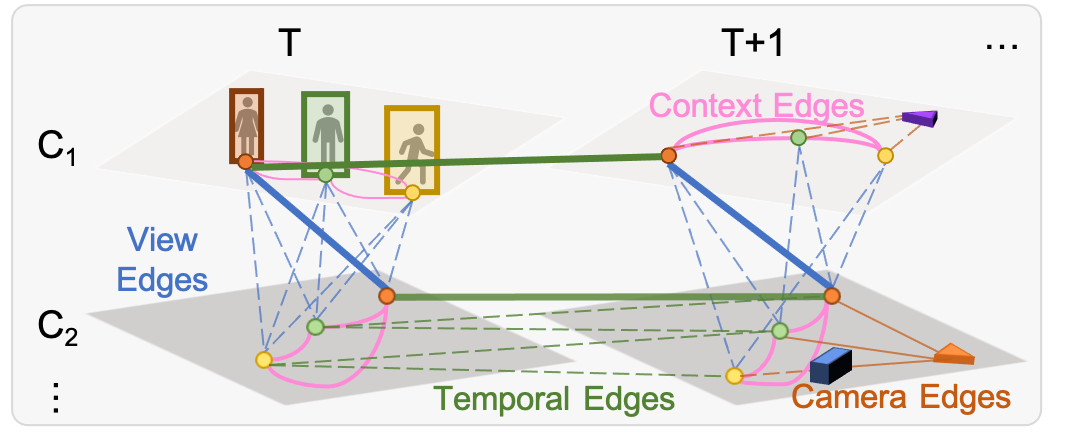
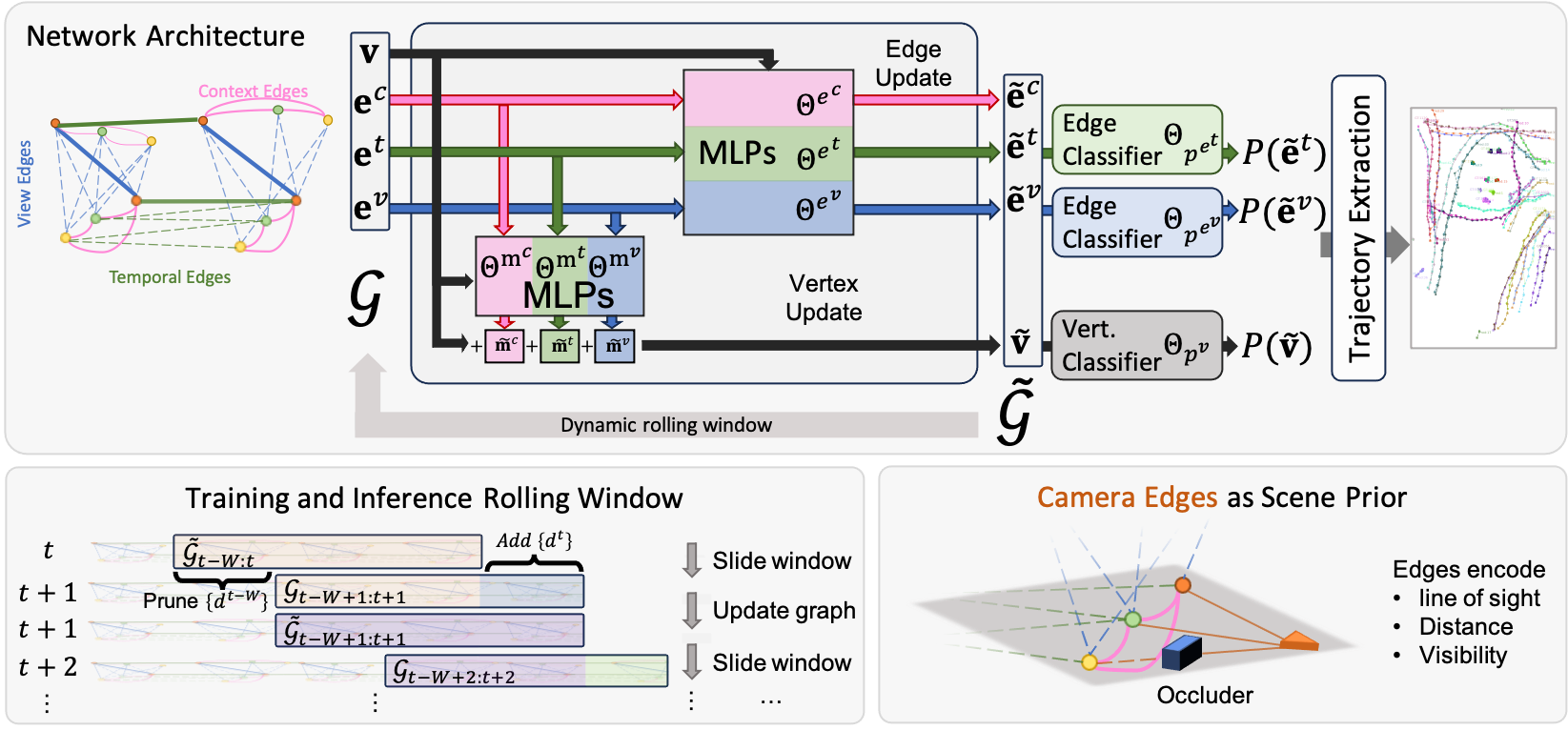
核心思路:本文的核心思路是构建一个动态的时空图神经网络(GNN),将检测结果作为节点,节点之间的边表示检测结果之间的关联关系。通过在图上进行消息传递,模型可以聚合空间、上下文和时间信息,从而实现对目标轨迹的推理。动态图结构允许模型根据序列中的信息自适应地调整连接,从而更好地处理遮挡和目标交互等复杂情况。
技术框架:该模型主要包含以下几个阶段:1) 检测:使用目标检测器提取每一帧中的目标检测结果。2) 图构建:基于检测结果构建动态时空图,节点表示检测结果,边表示检测结果之间的潜在关联。3) 图神经网络:使用GNN在图上进行消息传递,聚合节点和边的信息,学习节点和边的表示。4) 轨迹生成:基于学习到的节点和边的表示,使用匈牙利算法等方法将检测结果关联成轨迹。
关键创新:该方法的主要创新在于:1) 提出了一种动态图神经网络,能够自适应地学习检测结果之间的关联关系,从而更好地处理遮挡和目标交互等复杂情况。2) 将空间、上下文和时间信息集成到图结构中,从而实现对目标轨迹的更全面的推理。3) 提出了一个包含多视角、场景重建和大量遮挡的大规模数据集,为多目标跟踪的研究提供了新的资源。
关键设计:该模型使用GNN来学习节点和边的表示。GNN的结构可以根据具体任务进行调整,例如可以使用图卷积网络(GCN)或图注意力网络(GAT)。损失函数通常包括关联损失和轨迹完整性损失。关联损失用于鼓励模型学习正确的检测结果之间的关联关系,轨迹完整性损失用于鼓励模型生成完整的轨迹。数据集包含25个部分重叠的视角,详细的场景重建,以及大量的遮挡。
🖼️ 关键图片
📊 实验亮点
该模型在多个公共基准数据集和新提出的大规模数据集上均取得了最先进的性能。具体而言,在MOT17数据集上,该模型在多个指标上超越了现有方法。在新提出的数据集上,该模型也取得了显著的性能提升,证明了其在复杂场景下的有效性。实验结果表明,该模型能够有效地处理遮挡和目标交互等复杂情况,并且具有良好的泛化能力。
🎯 应用场景
该研究成果可广泛应用于智能监控、自动驾驶、机器人导航等领域。通过提升多目标跟踪的准确性和鲁棒性,可以为这些应用提供更可靠的环境感知能力。例如,在自动驾驶中,该技术可以帮助车辆更好地理解周围环境,从而做出更安全的决策。在智能监控中,该技术可以帮助监控系统更准确地跟踪目标,从而提高安全性和效率。
📄 摘要(原文)
This work presents a unified, fully differentiable model for multi-people tracking that learns to associate detections into trajectories without relying on pre-computed tracklets. The model builds a dynamic spatiotemporal graph that aggregates spatial, contextual, and temporal information, enabling seamless information propagation across entire sequences. To improve occlusion handling, the graph can also encode scene-specific information. We also introduce a new large-scale dataset with 25 partially overlapping views, detailed scene reconstructions, and extensive occlusions. Experiments show the model achieves state-of-the-art performance on public benchmarks and the new dataset, with flexibility across diverse conditions. Both the dataset and approach will be publicly released to advance research in multi-people tracking.