Vision Foundation Models as Effective Visual Tokenizers for Autoregressive Image Generation
作者: Anlin Zheng, Xin Wen, Xuanyang Zhang, Chuofan Ma, Tiancai Wang, Gang Yu, Xiangyu Zhang, Xiaojuan Qi
分类: cs.CV, cs.AI
发布日期: 2025-07-11 (更新: 2025-10-25)
备注: 20 pages, 4 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出VFMTok,利用视觉基础模型作为图像tokenizer,提升自回归图像生成质量。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像生成 视觉基础模型 Tokenizer 自回归模型 区域自适应量化
📋 核心要点
- 现有图像tokenizer在效率和语义保持方面存在挑战,难以充分利用大规模预训练视觉模型。
- VFMTok利用冻结的视觉基础模型作为编码器,通过区域自适应量化和语义重建目标来提升tokenizer的性能。
- 实验表明,VFMTok在图像重建、生成质量和token效率方面均有显著提升,并在ImageNet上取得了优秀的gFID分数。
📝 摘要(中文)
本文提出了一种新的图像tokenizer构建方法,直接基于冻结的视觉基础模型,这是一个很大程度上未被探索的领域。具体来说,我们采用冻结的视觉基础模型作为tokenizer的编码器。为了增强其有效性,我们引入了两个关键组件:(1)一个区域自适应量化框架,用于减少预训练特征在规则2D网格上的冗余;(2)一个语义重建目标,用于将tokenizer的输出与基础模型的表示对齐,以保持语义保真度。基于这些设计,我们提出的图像tokenizer VFMTok 在图像重建和生成质量方面取得了显著的改进,同时也提高了token效率。它进一步提升了自回归(AR)生成,在ImageNet基准测试上实现了1.36的gFID,同时将模型收敛速度提高了三倍,并实现了高保真度的类条件合成,而无需无分类器指导(CFG)。代码可在https://github.com/CVMI-Lab/VFMTok 获取。
🔬 方法详解
问题定义:现有的图像tokenizers通常需要从头开始训练,或者无法充分利用大规模视觉基础模型中蕴含的丰富语义信息。此外,它们在图像重建和生成过程中,往往存在token效率不高以及语义信息损失的问题,限制了自回归图像生成模型的性能。
核心思路:本文的核心思路是利用预训练的视觉基础模型作为图像tokenizer的编码器,并在此基础上进行优化,以提高token效率和语义保持能力。通过冻结视觉基础模型,可以有效利用其强大的特征提取能力,避免从头开始训练tokenizer。
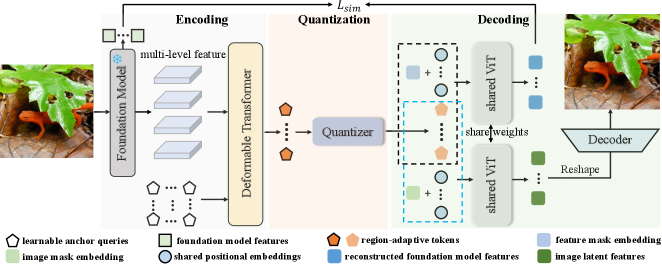
技术框架:VFMTok的整体框架包括三个主要部分:(1) 冻结的视觉基础模型作为编码器,用于提取图像特征;(2) 区域自适应量化模块,用于减少特征冗余,提高token效率;(3) 语义重建模块,通过最小化tokenizer输出与视觉基础模型表示之间的差异,保持语义一致性。整个流程是将图像输入视觉基础模型,提取特征后进行区域自适应量化,然后通过自回归模型进行图像生成或重建。
关键创新:VFMTok的关键创新在于将视觉基础模型直接用作图像tokenizer的编码器,并提出了区域自适应量化和语义重建目标。与传统的tokenizer相比,VFMTok能够更好地利用预训练模型的知识,提高token效率和语义保持能力。
关键设计:区域自适应量化模块根据图像不同区域的特征复杂度,动态调整量化步长,从而减少冗余信息。语义重建目标通过最小化tokenizer输出的重构图像与原始图像在视觉基础模型中的特征差异,来保证语义一致性。损失函数包括量化损失和语义重建损失,通过联合优化,提高tokenizer的整体性能。具体网络结构和参数设置在论文中有详细描述,此处不再赘述。
🖼️ 关键图片


📊 实验亮点
VFMTok在ImageNet数据集上取得了显著的成果,实现了1.36的gFID,相较于现有方法有大幅提升。同时,模型收敛速度提高了三倍,并且能够实现高保真度的类条件图像合成,而无需使用无分类器指导(CFG)。这些结果表明VFMTok在图像生成质量和效率方面具有显著优势。
🎯 应用场景
该研究成果可广泛应用于图像生成、图像编辑、图像压缩等领域。通过高效的图像tokenizer,可以降低图像数据的存储和传输成本,并提升图像生成模型的性能。此外,该方法还可以应用于视频生成、三维重建等领域,具有广阔的应用前景。
📄 摘要(原文)
In this work, we present a novel direction to build an image tokenizer directly on top of a frozen vision foundation model, which is a largely underexplored area. Specifically, we employ a frozen vision foundation model as the encoder of our tokenizer. To enhance its effectiveness, we introduce two key components: (1) a region-adaptive quantization framework that reduces redundancy in the pre-trained features on regular 2D grids, and (2) a semantic reconstruction objective that aligns the tokenizer's outputs with the foundation model's representations to preserve semantic fidelity. Based on these designs, our proposed image tokenizer, VFMTok, achieves substantial improvements in image reconstruction and generation quality, while also enhancing token efficiency. It further boosts autoregressive (AR) generation -- achieving a gFID of 1.36 on ImageNet benchmarks, while accelerating model convergence by three times, and enabling high-fidelity class-conditional synthesis without the need for classifier-free guidance (CFG). The code is available at https://github.com/CVMI-Lab/VFMTok.