Single-pass Adaptive Image Tokenization for Minimum Program Search
作者: Shivam Duggal, Sanghyun Byun, William T. Freeman, Antonio Torralba, Phillip Isola
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-07-10
备注: Code at: https://github.com/ShivamDuggal4/karl Keywords: Representation Learning, Adaptive Tokenization, Compression, Algorithmic Information Theory, Kolmogorov Complexity, Upside-Down RL
💡 一句话要点
提出KARL:单次自适应图像Token化方法,用于最小程序搜索。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自适应Token化 Kolmogorov复杂度 单次前向传播 图像表示学习 最小描述长度
📋 核心要点
- 现有视觉表示学习系统通常使用固定长度表示,忽略了图像复杂度和熟悉度的差异,限制了表示效率。
- KARL通过单次预测图像所需的Token数量,并在达到近似Kolmogorov复杂度时停止,实现自适应Token化。
- 实验表明,KARL在单次运行中达到了现有自适应Token化器的性能,并揭示了其与人类直觉的一致性。
📝 摘要(中文)
本文基于算法信息理论(AIT),提出了一种单次自适应Token化器KARL,旨在寻找能够以最短程序重建图像内容的智能表示,从而实现低Kolmogorov复杂度(KC)。与大多数视觉表示学习系统采用固定长度表示不同,KARL能够单次预测图像所需的Token数量,并在达到近似KC时停止。Token数量作为最小描述长度的代理。KARL的训练过程类似于Upside-Down强化学习,学习基于期望的重建质量有条件地预测Token停止。KARL在单次运行中匹配了现有自适应Token化器的性能。本文还分析了KARL的缩放规律,考察了编码器/解码器大小、连续与离散Token化等因素的作用,并从概念上探讨了自适应图像Token化与算法信息理论之间的联系,研究了图像复杂度(KC)与结构、噪声、分布内外熟悉度等因素的关系,揭示了其与人类直觉的一致性。
🔬 方法详解
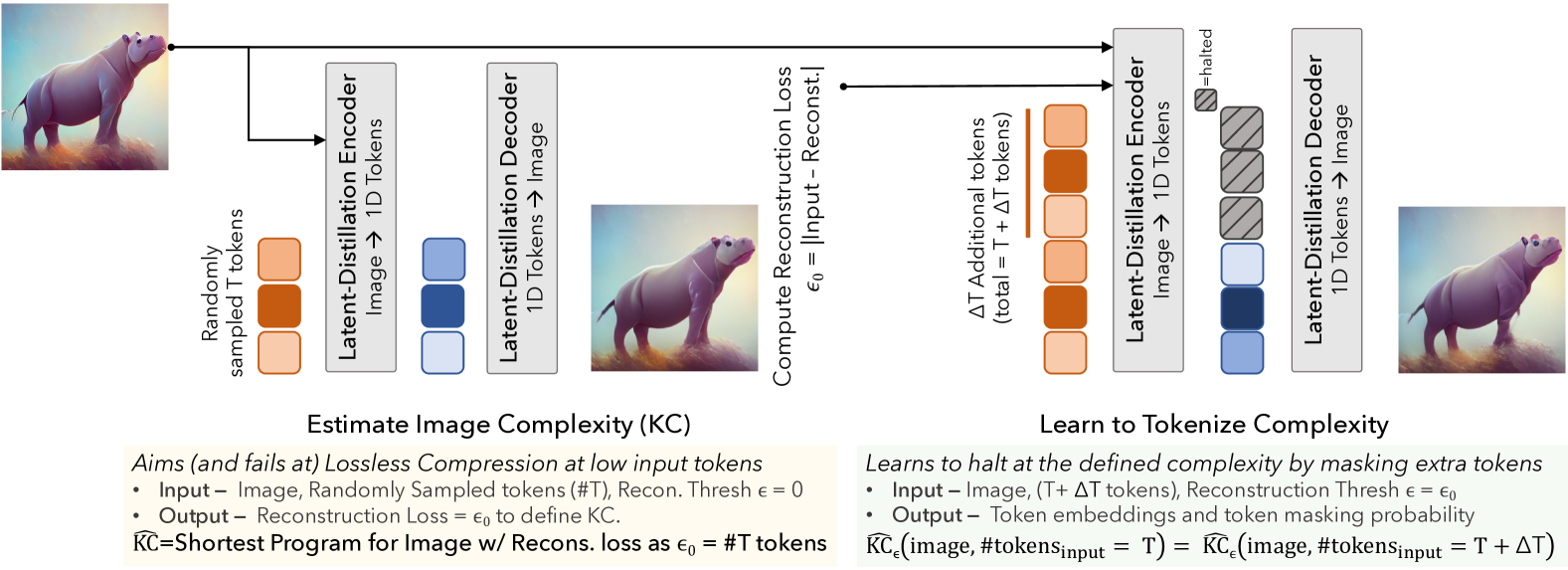
问题定义:现有自适应Token化方法通常需要在测试时搜索多个编码才能找到最具预测性的编码,计算成本高昂。论文旨在解决如何在单次前向传播中实现自适应图像Token化,从而降低计算复杂度,并更有效地表示图像信息。
核心思路:论文的核心思路是模拟Kolmogorov复杂度(KC)的概念,即智能表示应该能够将数据压缩成能够重建其内容的最短程序。通过预测图像所需的Token数量作为最小描述长度的代理,并在达到近似KC时停止Token化过程,从而实现自适应表示。
技术框架:KARL的整体架构包含一个编码器和一个解码器。编码器将图像转换为潜在表示,然后由一个预测模块预测Token停止概率。解码器使用生成的Token重建图像。训练过程采用类似于Upside-Down强化学习的范式,根据期望的重建质量来学习有条件地预测Token停止。
关键创新:KARL的关键创新在于其单次自适应Token化能力。与需要多次前向传播搜索最佳Token数量的现有方法不同,KARL能够在一次前向传播中预测合适的Token数量,显著提高了效率。此外,KARL将Token数量与Kolmogorov复杂度联系起来,为自适应表示学习提供了一个新的理论视角。
关键设计:KARL的关键设计包括:1) 使用预测模块预测Token停止概率,该模块基于编码器的输出和期望的重建质量来决定是否停止Token化;2) 采用Upside-Down强化学习范式进行训练,通过奖励高质量的重建和惩罚过多的Token来学习最佳的Token停止策略;3) 分析了编码器/解码器大小、连续与离散Token化等因素对性能的影响,并提出了相应的优化策略。
🖼️ 关键图片


📊 实验亮点
KARL在图像重建任务上取得了与现有自适应Token化器相当的性能,但只需要单次前向传播,显著降低了计算成本。论文还通过实验验证了KARL预测的Token数量与图像的复杂度和人类直觉之间存在一致性,表明KARL能够有效地捕捉图像的内在结构和语义信息。
🎯 应用场景
KARL的单次自适应图像Token化方法具有广泛的应用前景,例如图像压缩、图像检索、目标检测和图像生成等。它可以根据图像的复杂度和重要性自适应地分配计算资源,从而提高效率和性能。此外,KARL还可以用于理解图像的内在结构和语义信息,为视觉理解任务提供更有效的表示。
📄 摘要(原文)
According to Algorithmic Information Theory (AIT) -- Intelligent representations compress data into the shortest possible program that can reconstruct its content, exhibiting low Kolmogorov Complexity (KC). In contrast, most visual representation learning systems use fixed-length representations for all inputs, ignoring variations in complexity or familiarity. Recent adaptive tokenization methods address this by allocating variable-length representations but typically require test-time search over multiple encodings to find the most predictive one. Inspired by Kolmogorov Complexity principles, we propose a single-pass adaptive tokenizer, KARL, which predicts the appropriate number of tokens for an image in a single forward pass, halting once its approximate KC is reached. The token count serves as a proxy for the minimum description length. KARL's training procedure closely resembles the Upside-Down Reinforcement Learning paradigm, as it learns to conditionally predict token halting based on a desired reconstruction quality. KARL matches the performance of recent adaptive tokenizers while operating in a single pass. We present scaling laws for KARL, analyzing the role of encoder/decoder size, continuous vs. discrete tokenization and more. Additionally, we offer a conceptual study drawing an analogy between Adaptive Image Tokenization and Algorithmic Information Theory, examining the predicted image complexity (KC) across axes such as structure vs. noise and in- vs. out-of-distribution familiarity -- revealing alignment with human intuition.