Multigranular Evaluation for Brain Visual Decoding
作者: Weihao Xia, Cengiz Oztireli
分类: cs.CV, cs.AI, eess.IV, q-bio.NC
发布日期: 2025-07-10 (更新: 2025-11-30)
备注: AAAI 2026 (Oral). Code: https://github.com/weihaox/BASIC
💡 一句话要点
提出BASIC框架,用于脑视觉解码的多粒度、神经科学驱动的综合评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脑视觉解码 多粒度评估 神经科学 图像重建 多模态学习
📋 核心要点
- 现有脑视觉解码评估指标粗糙,难以区分模型优劣,缺乏神经科学依据,无法捕捉精细视觉差异。
- BASIC框架通过联合量化结构保真度、推断对齐性和上下文连贯性,实现多粒度综合评估。
- 实验表明,BASIC框架能够更有效地区分不同视觉解码方法,并提供更具解释性的评估结果。
📝 摘要(中文)
现有的脑视觉解码评估方法主要依赖于粗糙的指标,掩盖了模型间的差异,缺乏神经科学基础,并且无法捕捉细粒度的视觉区别。为了解决这些局限性,我们引入了BASIC,一个统一的、多粒度的评估框架,它联合量化了解码图像和真实图像之间的结构保真度、推断对齐性和上下文连贯性。在结构层面,我们引入了一套基于分割的层次化指标,包括前景、语义、实例和组件掩码,这些掩码基于跨掩码结构的粒度感知对应关系。在语义层面,我们使用多模态大型语言模型提取包含对象、属性和关系的结构化场景表示,从而实现与真实刺激的详细、可扩展和上下文丰富的比较。我们在该统一评估框架内,对多个刺激-神经影像数据集上的一系列视觉解码方法进行了基准测试。总之,这些标准为评估脑视觉解码方法提供了一个更具区分性、可解释性和综合性的基础。
🔬 方法详解
问题定义:脑视觉解码旨在从神经活动中重建或理解个体所看到的图像。现有评估方法主要依赖于像素级别的相似度或简单的分类准确率等粗糙指标,无法充分反映解码图像的质量,也难以捕捉解码图像在结构、语义和上下文等多个层面的信息。此外,现有评估方法缺乏与神经科学的紧密联系,难以解释解码结果与大脑认知过程之间的关系。
核心思路:BASIC框架的核心思路是从多个粒度层面评估解码图像的质量,包括结构保真度、推断对齐性和上下文连贯性。通过引入基于分割的层次化指标,可以更精细地评估解码图像的结构信息。利用多模态大型语言模型提取场景表示,可以更全面地评估解码图像的语义信息和上下文关系。这种多粒度的评估方式能够更准确地反映解码图像的质量,并提供更具解释性的评估结果。
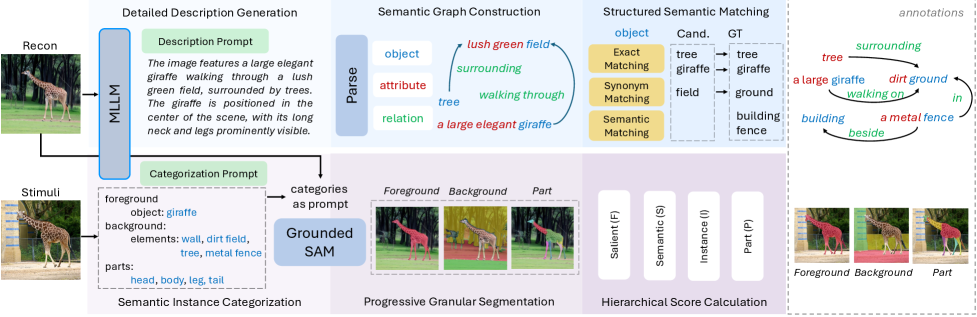
技术框架:BASIC框架包含三个主要模块:结构评估模块、语义评估模块和上下文评估模块。结构评估模块使用基于分割的层次化指标,包括前景、语义、实例和组件掩码,来评估解码图像的结构保真度。语义评估模块使用多模态大型语言模型提取场景表示,包括对象、属性和关系,来评估解码图像的语义信息。上下文评估模块则通过比较解码图像和真实图像的场景表示,来评估解码图像的上下文连贯性。
关键创新:BASIC框架的关键创新在于其多粒度的评估方式和与神经科学的紧密联系。通过引入基于分割的层次化指标和多模态大型语言模型,BASIC框架能够更精细、更全面地评估解码图像的质量。此外,BASIC框架的设计考虑了大脑的认知过程,能够提供更具解释性的评估结果。
关键设计:在结构评估模块中,使用了Dice系数、IoU等指标来衡量解码图像和真实图像在不同分割掩码上的相似度。在语义评估模块中,使用了CLIP模型来提取图像的视觉特征,并使用大型语言模型来提取场景表示。在上下文评估模块中,使用了余弦相似度等指标来衡量解码图像和真实图像的场景表示之间的相似度。框架中各个模块的权重可以根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
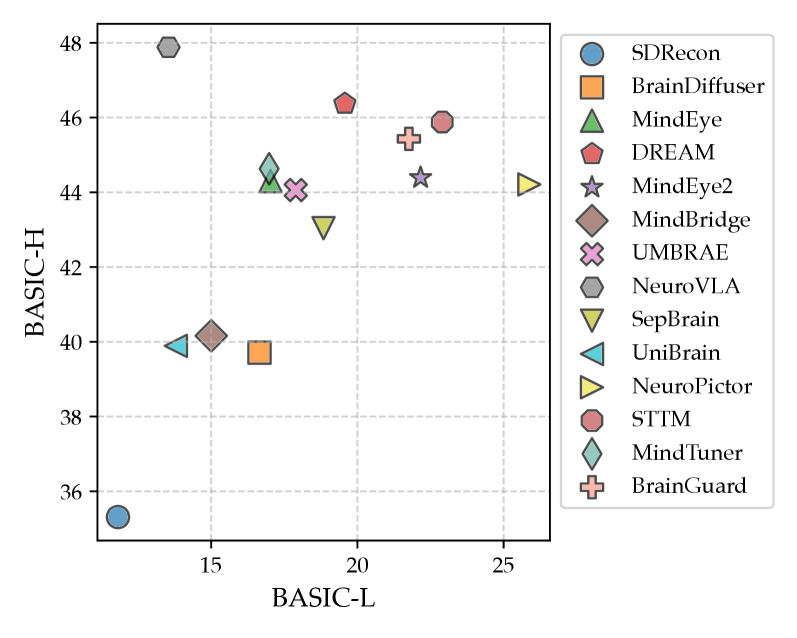
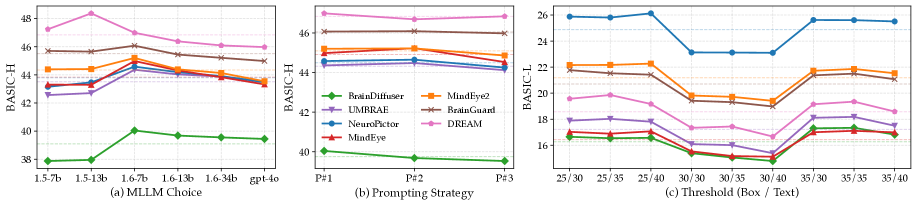
该研究在多个刺激-神经影像数据集上对一系列视觉解码方法进行了基准测试,结果表明BASIC框架能够更有效地区分不同解码方法的性能,并提供更具解释性的评估结果。例如,在某些数据集上,使用BASIC框架评估得到的模型性能排序与使用传统指标评估得到的排序存在显著差异,表明BASIC框架能够更准确地反映模型的真实性能。
🎯 应用场景
该研究成果可应用于脑机接口、神经科学研究、以及人工智能领域。在脑机接口方面,可以用于评估和改进视觉解码算法,提高解码图像的质量,从而帮助瘫痪患者恢复视觉功能。在神经科学研究方面,可以用于研究大脑的视觉认知过程,揭示大脑如何编码和处理视觉信息。在人工智能领域,可以为生成模型提供更有效的评估指标,提高生成图像的质量和真实感。
📄 摘要(原文)
Existing evaluation protocols for brain visual decoding predominantly rely on coarse metrics that obscure inter-model differences, lack neuroscientific foundation, and fail to capture fine-grained visual distinctions. To address these limitations, we introduce BASIC, a unified, multigranular evaluation framework that jointly quantifies structural fidelity, inferential alignment, and contextual coherence between decoded and ground-truth images. For the structural level, we introduce a hierarchical suite of segmentation-based metrics, including foreground, semantic, instance, and component masks, anchored in granularity-aware correspondence across mask structures. For the semantic level, we extract structured scene representations encompassing objects, attributes, and relationships using multimodal large language models, enabling detailed, scalable, and context-rich comparisons with ground-truth stimuli. We benchmark a diverse set of visual decoding methods across multiple stimulus-neuroimaging datasets within this unified evaluation framework. Together, these criteria provide a more discriminative, interpretable, and comprehensive foundation for evaluating brain visual decoding methods.