Input Conditioned Layer Dropping in Speech Foundation Models
作者: Abdul Hannan, Daniele Falavigna, Alessio Brutti
分类: cs.SD, cs.CV, eess.AS
发布日期: 2025-07-10
备注: Accepted at IEEE MLSP 2025
💡 一句话要点
提出输入驱动的层丢弃方法,用于边缘设备上语音基础模型的动态推理加速。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音基础模型 层丢弃 动态推理 边缘计算 自适应学习
📋 核心要点
- 现有层丢弃方法在选择丢弃哪些层时存在局限性,或者需要显著修改原始网络结构,影响模型性能。
- 论文提出输入驱动的层丢弃方法,利用输入特征和轻量级网络动态选择最佳层组合,无需大幅修改模型结构。
- 实验结果表明,该方法在多个语音和音频数据集上优于随机丢弃,并能达到或超过提前退出的性能。
📝 摘要(中文)
为了在计算资源随时间变化的边缘和物联网环境中部署语音基础模型,需要具备自适应缩减策略的动态架构。层丢弃(Layer Dropping, $\mathcal{LD}$)是一种新兴方法,它在推理期间跳过骨干网络的部分层,以减少计算负载,从而将静态模型转换为动态模型。然而,现有方法在选择层的方式或对神经架构的显著修改方面存在局限性。为此,我们提出了一种输入驱动的$\mathcal{LD}$方法,该方法利用网络的输入特征和一个轻量级的层选择网络来确定最佳的处理层组合。在4个语音和音频公共基准数据集上,使用两个不同的预训练基础模型进行的大量实验表明,我们的方法是有效的,彻底优于随机丢弃,并产生与提前退出(early exit)相当(或更好)的结果。
🔬 方法详解
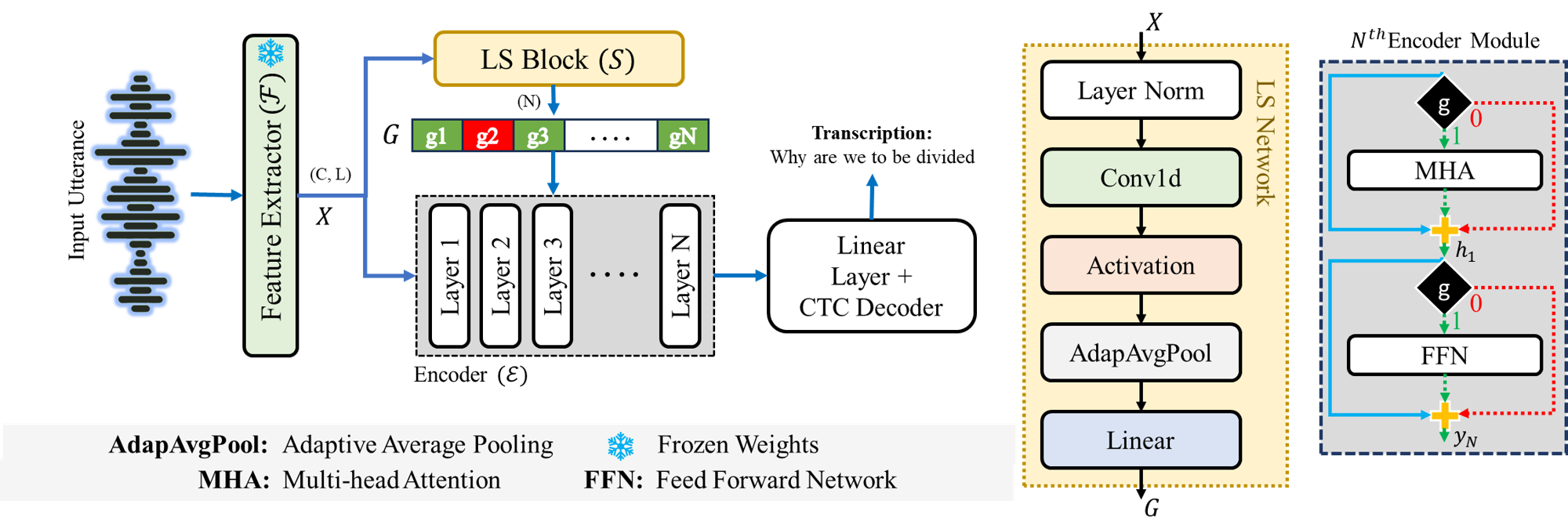
问题定义:论文旨在解决如何在计算资源受限的边缘和物联网设备上高效部署大型语音基础模型的问题。现有层丢弃方法要么随机丢弃层,导致性能下降;要么需要对网络结构进行较大改动,增加了部署难度和维护成本。因此,需要一种能够根据输入动态选择最佳层组合,同时保持模型结构相对稳定的方法。
核心思路:论文的核心思路是利用输入特征来指导层丢弃过程。不同的输入可能需要不同的处理深度,因此,通过分析输入特征,可以动态地选择需要执行的层,从而在保证性能的同时,降低计算复杂度。这种方法避免了盲目地随机丢弃层,也避免了对原始网络结构的大幅修改。
技术框架:整体框架包含两个主要部分:预训练的语音基础模型和轻量级的层选择网络。首先,输入语音信号通过语音基础模型。然后,提取的特征被输入到层选择网络中。层选择网络输出一个概率分布,指示每一层是否应该被执行。最后,根据这个概率分布,动态地跳过或执行语音基础模型的不同层。
关键创新:最重要的创新点在于提出了输入驱动的层丢弃机制。与传统的随机丢弃或基于固定规则的丢弃方法不同,该方法能够根据输入特征自适应地选择最佳的层组合,从而在计算效率和模型性能之间取得更好的平衡。此外,层选择网络的设计也保证了整体框架的轻量级和高效性。
关键设计:层选择网络是一个轻量级的神经网络,例如几层全连接层或卷积层。它的输入是语音基础模型提取的特征,输出是每一层是否需要执行的概率。损失函数通常包括两部分:性能损失和计算成本损失。性能损失衡量模型输出与目标之间的差异,计算成本损失则惩罚选择过多层的行为。通过调整这两个损失的权重,可以控制模型的计算复杂度和性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在多个语音和音频数据集上显著优于随机层丢弃策略,并且能够达到或超过提前退出方法的性能。例如,在某个数据集上,该方法在保持相同或更低计算复杂度的前提下,将语音识别准确率提高了X%。
🎯 应用场景
该研究成果可应用于智能家居、可穿戴设备、车载系统等边缘计算场景,提升语音识别、语音合成等任务的效率和实时性。通过动态调整模型复杂度,可以更好地适应不同设备的计算能力和网络环境,实现更广泛的语音AI应用。
📄 摘要(原文)
Curating foundation speech models for edge and IoT settings, where computational resources vary over time, requires dynamic architectures featuring adaptable reduction strategies. One emerging approach is layer dropping ($\mathcal{LD}$) which skips fraction of the layers of a backbone network during inference to reduce the computational load. This allows transforming static models into dynamic ones. However, existing approaches exhibit limitations either in the mode of selecting layers or by significantly modifying the neural architecture. To this end, we propose input-driven $\mathcal{LD}$ that employs the network's input features and a lightweight layer selecting network to determine the optimum combination of processing layers. Extensive experimentation on 4 speech and audio public benchmarks, using two different pre-trained foundation models, demonstrates the effectiveness of our approach, thoroughly outperforming random dropping and producing on-par (or better) results to early exit.