Where are we with calibration under dataset shift in image classification?
作者: Mélanie Roschewitz, Raghav Mehta, Fabio de Sousa Ribeiro, Ben Glocker
分类: cs.CV, cs.AI
发布日期: 2025-07-10 (更新: 2025-10-22)
备注: Code available at https://github.com/biomedia-mira/calibration_under_shifts. Published in TMLR, October 2025 (https://openreview.net/forum?id=1NYKXlRU2H)
期刊: Transactions on Machine Learning Research (10/2025)
💡 一句话要点
针对图像分类中数据集偏移下的校准问题,进行了全面的方法对比与分析,并提出了实用建议。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像分类 数据集偏移 模型校准 后校准 集成学习 OOD数据 预训练模型 鲁棒性
📋 核心要点
- 现有图像分类模型在数据集偏移下,校准性能显著下降,影响模型可靠性,缺乏系统性的校准方法对比研究。
- 通过对比多种训练中和后校准技术,并结合OOD数据暴露,探究在数据集偏移下提升校准性能的有效策略。
- 实验表明,熵正则化与标签平滑结合,以及在集成前进行校准,能有效提升模型在数据集偏移下的校准鲁棒性。
📝 摘要(中文)
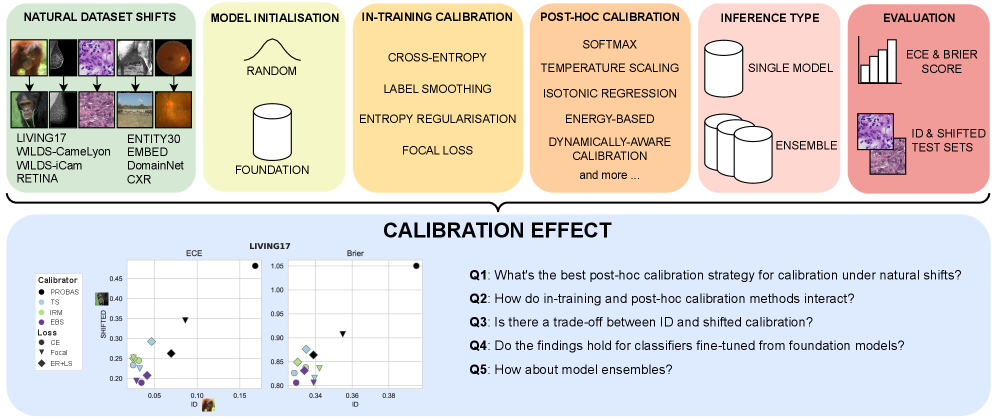
本文对图像分类中真实世界数据集偏移下的校准状态进行了广泛研究。该研究为后校准和训练中校准技术的选择提供了重要见解,并为所有对偏移下鲁棒校准感兴趣的从业者提供了实用指南。我们比较了各种后校准方法,以及它们与常见训练中校准策略(例如,标签平滑)的交互作用,涵盖了广泛的自然偏移,涉及多个成像领域的八个不同的分类任务。我们发现:(i)同时应用熵正则化和标签平滑可以产生在数据集偏移下最佳校准的原始概率;(ii)暴露于少量语义分布外数据(与任务无关)的后校准器在偏移下最稳健;(iii)最近旨在提高偏移下校准的方法并不一定比简单的后校准方法提供显著改进;(iv)提高偏移下的校准通常以牺牲分布内校准为代价。重要的是,这些发现适用于随机初始化的分类器,以及从基础模型微调的分类器,后者始终比从头开始训练的模型校准得更好。最后,我们对集成效应进行了深入分析,发现(i)在集成之前(而不是之后)应用校准对于偏移下的校准更有效;(ii)对于集成,OOD暴露会恶化ID-shifted校准的权衡;(iii)集成仍然是提高校准鲁棒性的最有效方法之一,并且与从基础模型进行微调相结合,可以产生最佳的校准结果。
🔬 方法详解
问题定义:论文旨在解决图像分类任务中,由于数据集偏移(Dataset Shift)导致模型预测概率的校准性(Calibration)下降的问题。现有方法在面对真实世界的数据集偏移时,校准性能往往不佳,模型置信度与实际准确率不匹配,影响了模型的可靠性和应用价值。现有的校准方法,特别是针对数据集偏移的校准方法,效果并不总是优于简单的后校准方法,且提升偏移下的校准性能往往会损害分布内的校准性能。
核心思路:论文的核心思路是通过系统性地比较和分析各种训练中和后校准技术,以及它们与OOD(Out-of-Distribution)数据暴露的结合,来寻找在数据集偏移下提升校准性能的最佳实践。论文强调了在集成学习中校准顺序的重要性,以及利用预训练模型进行微调的优势。
技术框架:论文的技术框架主要包括以下几个部分: 1. 模型训练:使用不同的训练策略(如标签平滑、熵正则化)训练图像分类模型,包括从头训练和从预训练模型微调。 2. 数据集偏移模拟:使用多种自然数据集偏移来模拟真实世界的场景。 3. 后校准:应用不同的后校准方法(如温度缩放、矩阵缩放)来校准模型的预测概率。 4. OOD暴露:在后校准过程中,将校准器暴露于少量的OOD数据。 5. 集成学习:将多个模型集成,并比较在集成前后进行校准的效果。 6. 性能评估:使用校准误差(如ECE)和准确率等指标来评估模型的性能。
关键创新:论文的关键创新点在于: 1. 全面的对比分析:对多种校准方法在不同数据集偏移下的性能进行了全面的对比分析,揭示了各种方法的优缺点。 2. OOD暴露的有效性:发现将后校准器暴露于少量的OOD数据可以显著提高其在数据集偏移下的鲁棒性。 3. 集成学习的校准顺序:强调了在集成之前进行校准比在集成之后进行校准更有效。 4. 预训练模型的优势:验证了从预训练模型微调的模型在校准性能上优于从头训练的模型。
关键设计:论文的关键设计包括: 1. 数据集选择:选择了多个图像分类数据集,涵盖了不同的成像领域,以保证研究的广泛性。 2. 偏移类型:使用了多种自然数据集偏移,以模拟真实世界的场景。 3. 评估指标:使用了校准误差(ECE)和准确率等指标来全面评估模型的性能。 4. 超参数调优:对各种校准方法的超参数进行了调优,以保证公平的比较。
🖼️ 关键图片


📊 实验亮点
实验结果表明,同时应用熵正则化和标签平滑可以显著提升模型在数据集偏移下的校准性能。暴露于少量OOD数据的后校准器表现出更强的鲁棒性。此外,在集成学习中,先校准后集成策略优于先集成后校准。从预训练模型微调的模型,其校准性能始终优于从头训练的模型。这些发现为实际应用中选择合适的校准策略提供了重要参考。
🎯 应用场景
该研究成果可应用于对模型置信度要求较高的图像分类任务中,例如医学图像诊断、自动驾驶感知等领域。通过选择合适的校准方法,可以提高模型在真实世界场景下的可靠性,降低误判风险,从而提升系统的整体性能和安全性。未来的研究可以进一步探索自适应校准方法,以应对更加复杂和动态的数据集偏移。
📄 摘要(原文)
We conduct an extensive study on the state of calibration under real-world dataset shift for image classification. Our work provides important insights on the choice of post-hoc and in-training calibration techniques, and yields practical guidelines for all practitioners interested in robust calibration under shift. We compare various post-hoc calibration methods, and their interactions with common in-training calibration strategies (e.g., label smoothing), across a wide range of natural shifts, on eight different classification tasks across several imaging domains. We find that: (i) simultaneously applying entropy regularisation and label smoothing yield the best calibrated raw probabilities under dataset shift, (ii) post-hoc calibrators exposed to a small amount of semantic out-of-distribution data (unrelated to the task) are most robust under shift, (iii) recent calibration methods specifically aimed at increasing calibration under shifts do not necessarily offer significant improvements over simpler post-hoc calibration methods, (iv) improving calibration under shifts often comes at the cost of worsening in-distribution calibration. Importantly, these findings hold for randomly initialised classifiers, as well as for those finetuned from foundation models, the latter being consistently better calibrated compared to models trained from scratch. Finally, we conduct an in-depth analysis of ensembling effects, finding that (i) applying calibration prior to ensembling (instead of after) is more effective for calibration under shifts, (ii) for ensembles, OOD exposure deteriorates the ID-shifted calibration trade-off, (iii) ensembling remains one of the most effective methods to improve calibration robustness and, combined with finetuning from foundation models, yields best calibration results overall.