Rationale-Enhanced Decoding for Multi-modal Chain-of-Thought
作者: Shin'ya Yamaguchi, Kosuke Nishida, Daiki Chijiwa
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-07-10
备注: 17 pages, 4 figures
💡 一句话要点
提出Rationale-Enhanced Decoding (RED),提升多模态Chain-of-Thought推理中理性内容利用率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 思维链 视觉语言模型 理性内容 解码策略
📋 核心要点
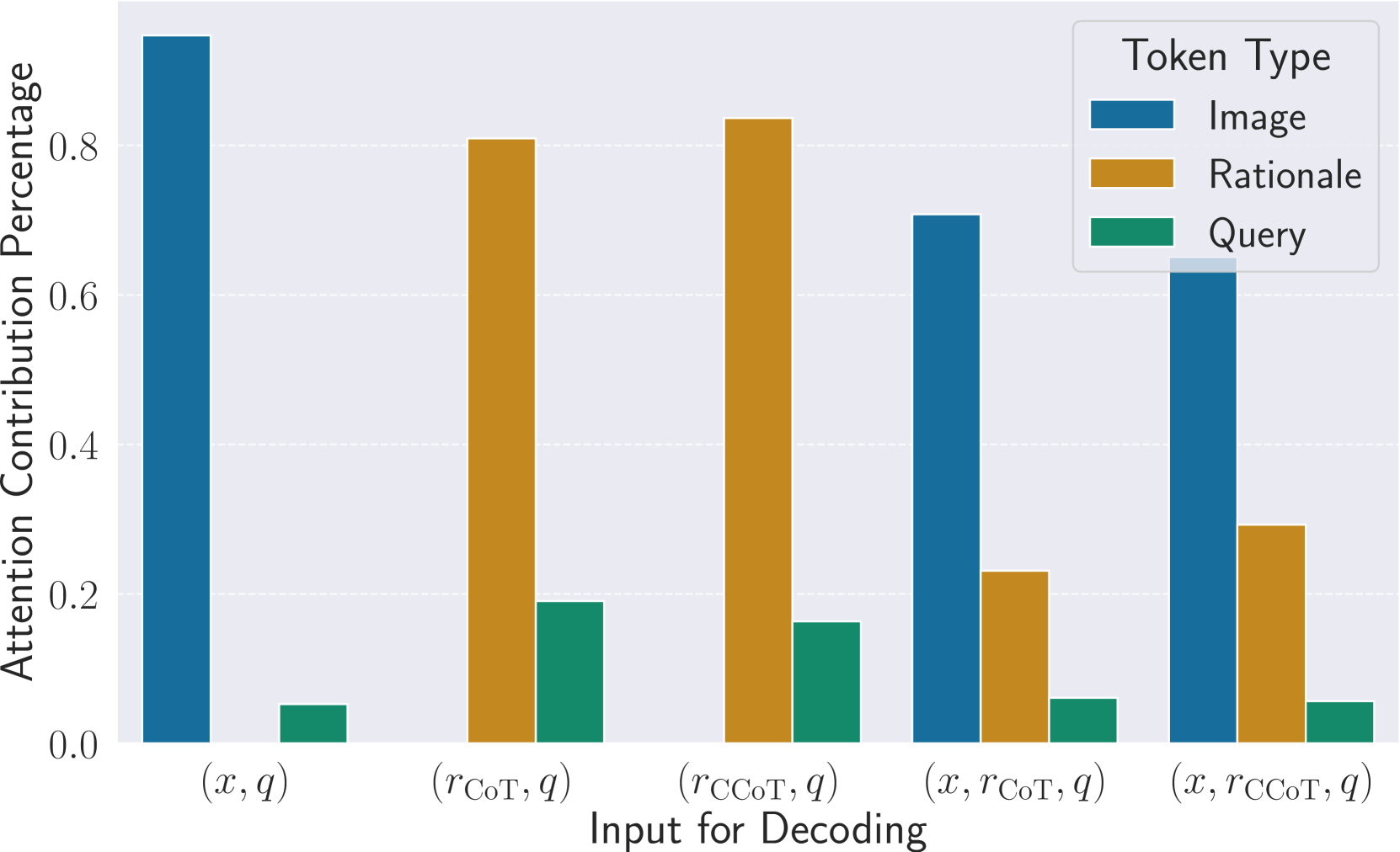
- 现有LVLMs在CoT推理中存在忽略生成理性内容的问题,导致推理过程与理性内容不一致。
- 论文提出Rationale-Enhanced Decoding (RED),通过融合图像和理性内容信息来指导解码过程。
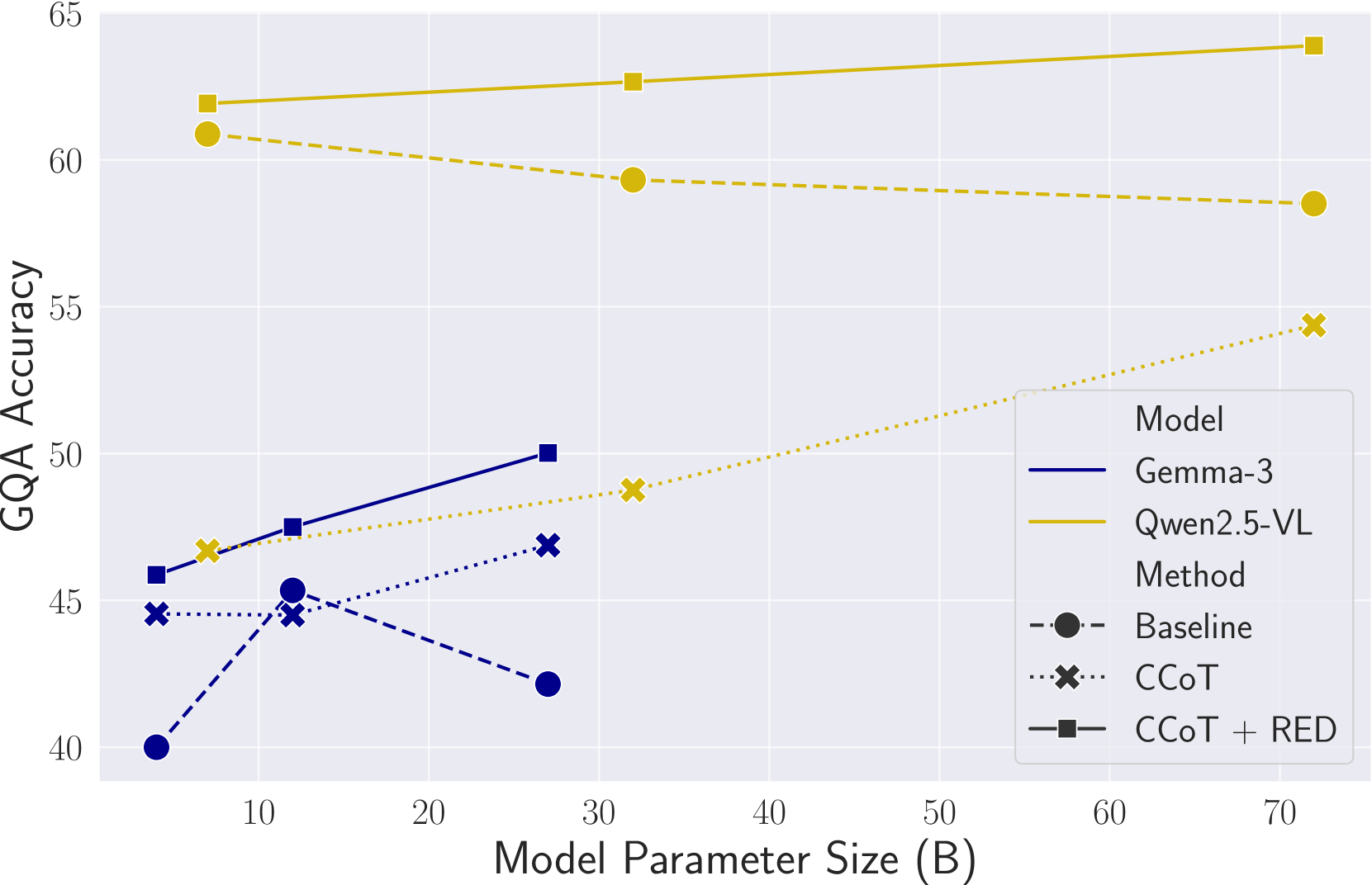
- 实验表明,RED在多个基准测试和LVLMs上显著提高了推理性能,优于标准CoT和其他解码方法。
📝 摘要(中文)
大型视觉-语言模型(LVLMs)通过整合预训练的视觉编码器和大型语言模型(LLMs)展现了卓越的能力。类似于单模态LLMs,思维链(CoT)提示已被应用于LVLMs,通过生成基于视觉和文本输入的中间理性内容来增强多模态推理。虽然CoT被认为可以提高LVLMs的 grounding 和准确性,但我们的实验揭示了一个关键挑战:现有的LVLMs在CoT推理中经常忽略生成的理性内容。为了解决这个问题,我们将多模态CoT推理重新定义为以理性内容为条件的对数似然的KL约束奖励最大化问题。作为最优解,我们提出了一种新的即插即用推理时解码策略,即理性增强解码(RED)。RED通过将不同的图像条件和理性内容条件下的下一个token分布相乘来协调视觉和理性内容信息。大量的实验表明,RED在多个基准测试和LVLMs上始终如一地显著提高了相对于标准CoT和其他解码方法的推理能力。我们的工作提供了一种实用有效的方法来提高LVLMs中CoT推理的忠实性和准确性,为更可靠的基于理性内容的多模态系统铺平了道路。
🔬 方法详解
问题定义:现有的大型视觉语言模型(LVLMs)在进行多模态思维链(CoT)推理时,虽然能够生成中间的理性内容,但往往忽略这些理性内容,导致最终的推理结果与生成的理性内容不一致,即理性内容没有被充分利用。这降低了推理的可靠性和准确性。
核心思路:论文的核心思路是将多模态CoT推理视为一个KL约束的奖励最大化问题,目标是最大化以理性内容为条件的对数似然。通过这种方式,模型在生成答案时会更加关注并利用生成的理性内容。RED解码策略通过融合图像和理性内容信息来指导解码过程,从而确保生成的答案与两者都保持一致。
技术框架:RED是一种即插即用的推理时解码策略,可以应用于现有的LVLMs。其主要流程如下:1) 输入图像和问题;2) LVLM生成中间理性内容;3) RED解码器利用图像和理性内容信息生成最终答案。RED解码器通过融合图像条件和理性内容条件下的下一个token分布来生成最终的token分布,从而指导解码过程。
关键创新:RED的关键创新在于其融合图像和理性内容信息的方式。传统的解码方法通常只考虑图像信息,而RED同时考虑了图像和理性内容信息,从而更好地利用了理性内容。RED通过将图像条件和理性内容条件下的下一个token分布相乘来实现这种融合,这是一种简单而有效的方法。
关键设计:RED解码器通过以下公式融合图像和理性内容信息:P(token | image, rationale) = P(token | image) * P(token | rationale)。其中,P(token | image)是图像条件下的token分布,P(token | rationale)是理性内容条件下的token分布。通过将这两个分布相乘,RED解码器可以同时考虑图像和理性内容信息。论文没有详细说明具体的网络结构或损失函数,因为RED是一种解码策略,可以应用于各种LVLMs。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RED在多个基准测试(如ScienceQA、A-OKVQA)和不同的LVLMs(如LLaVA、InstructBLIP)上都取得了显著的性能提升。例如,在ScienceQA数据集上,RED相对于标准CoT方法提升了多个百分点。这些结果表明,RED是一种有效且通用的方法,可以提高LVLMs的推理能力。
🎯 应用场景
该研究成果可应用于各种需要多模态推理的场景,例如视觉问答、图像描述生成、机器人导航等。通过提高LVLMs的推理能力和可靠性,可以构建更智能、更值得信赖的多模态系统,例如辅助诊断、智能客服等,具有广泛的应用前景。
📄 摘要(原文)
Large vision-language models (LVLMs) have demonstrated remarkable capabilities by integrating pre-trained vision encoders with large language models (LLMs). Similar to single-modal LLMs, chain-of-thought (CoT) prompting has been adapted for LVLMs to enhance multi-modal reasoning by generating intermediate rationales based on visual and textual inputs. While CoT is assumed to improve grounding and accuracy in LVLMs, our experiments reveal a key challenge: existing LVLMs often ignore the contents of generated rationales in CoT reasoning. To address this, we re-formulate multi-modal CoT reasoning as a KL-constrained reward maximization focused on rationale-conditional log-likelihood. As the optimal solution, we propose rationale-enhanced decoding (RED), a novel plug-and-play inference-time decoding strategy. RED harmonizes visual and rationale information by multiplying distinct image-conditional and rationale-conditional next token distributions. Extensive experiments show that RED consistently and significantly improves reasoning over standard CoT and other decoding methods across multiple benchmarks and LVLMs. Our work offers a practical and effective approach to improve both the faithfulness and accuracy of CoT reasoning in LVLMs, paving the way for more reliable rationale-grounded multi-modal systems.