EPIC: Efficient Prompt Interaction for Text-Image Classification
作者: Xinyao Yu, Hao Sun, Zeyu Ling, Ziwei Niu, Zhenjia Bai, Rui Qin, Yen-Wei Chen, Lanfen Lin
分类: cs.CV
发布日期: 2025-07-10
备注: arXiv admin note: substantial text overlap with arXiv:2401.14856
💡 一句话要点
EPIC:一种高效的文本-图像分类提示交互方法,显著降低计算成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本-图像分类 多模态学习 提示学习 高效微调 相似性交互
📋 核心要点
- 大规模多模态模型微调成本高昂,限制了其在下游任务中的应用。
- 提出EPIC,利用时间提示和相似性提示交互,实现高效的模态信息融合。
- 实验表明,EPIC在降低计算成本的同时,在多个数据集上取得了优异的性能。
📝 摘要(中文)
近年来,大规模预训练多模态模型(LMMs)在整合视觉和语言模态方面取得了显著进展,并在文本-图像分类等多模态任务中获得了巨大成功。然而,LMMs的规模不断增长,导致微调这些模型以适应下游任务的计算成本显著增加。因此,研究基于提示的交互策略以更有效地对齐模态变得重要。本文提出了一种新颖的、高效的基于提示的多模态交互策略,即用于文本-图像分类的高效提示交互(EPIC)。具体而言,我们在中间层利用时间提示,并通过基于相似性的提示交互来整合不同的模态,从而充分利用模态之间的信息交换。利用这种方法,与其他微调策略相比,我们的方法降低了计算资源消耗,并减少了可训练参数(约占基础模型的1%)。此外,它在UPMC-Food101和SNLI-VE数据集上表现出卓越的性能,同时在MM-IMDB数据集上实现了可比的性能。
🔬 方法详解
问题定义:本文旨在解决大规模预训练多模态模型在文本-图像分类任务中微调成本过高的问题。现有方法通常需要微调整个模型,导致计算资源消耗巨大,难以在资源受限的环境中应用。
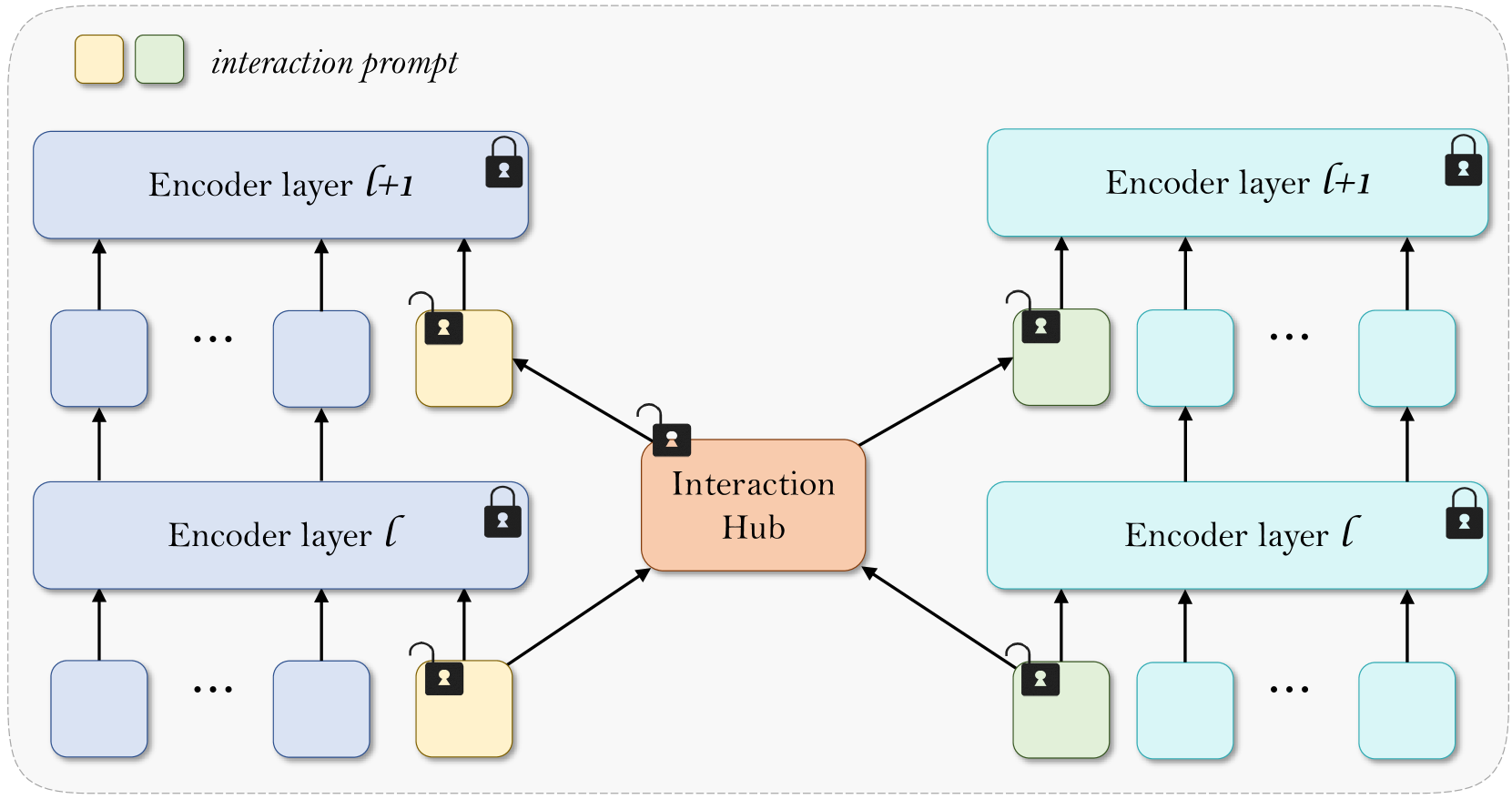
核心思路:EPIC的核心思路是利用提示学习(Prompt Learning)的思想,仅微调少量提示参数,而非整个模型。通过在模型的中间层引入时间提示,并利用基于相似性的提示交互,实现不同模态信息的有效融合,从而在降低计算成本的同时,保持甚至提升模型的性能。
技术框架:EPIC主要包含以下几个模块:1) 文本编码器和图像编码器:用于提取文本和图像的特征表示。2) 时间提示模块:在模型的中间层插入可学习的时间提示,用于引导模型关注关键信息。3) 相似性提示交互模块:计算文本和图像特征之间的相似性,并利用相似性权重对提示进行交互,从而实现模态信息的融合。4) 分类器:基于融合后的特征进行分类。
关键创新:EPIC的关键创新在于提出了基于时间提示和相似性提示交互的高效模态融合方法。与传统的微调方法相比,EPIC仅需要微调少量提示参数,大大降低了计算成本。同时,通过时间提示和相似性提示交互,可以更有效地利用模态之间的信息,提升模型的性能。
关键设计:时间提示模块的具体实现方式可以是添加可学习的向量到中间层的特征表示中。相似性提示交互模块可以使用余弦相似度或点积等方法计算文本和图像特征之间的相似性。损失函数可以使用交叉熵损失函数。
🖼️ 关键图片


📊 实验亮点
EPIC在UPMC-Food101和SNLI-VE数据集上取得了优于其他微调策略的性能,同时在MM-IMDB数据集上实现了可比的性能。值得注意的是,EPIC的可训练参数仅占基础模型的1%,显著降低了计算成本。实验结果表明,EPIC是一种高效且有效的文本-图像分类方法。
🎯 应用场景
EPIC具有广泛的应用前景,例如在图像搜索、视觉问答、多模态情感分析等领域。该方法可以降低多模态模型在资源受限设备上的部署成本,促进多模态技术在移动设备、嵌入式系统等场景中的应用。此外,EPIC的设计思想也可以推广到其他多模态任务中,为多模态学习领域的研究提供新的思路。
📄 摘要(原文)
In recent years, large-scale pre-trained multimodal models (LMMs) generally emerge to integrate the vision and language modalities, achieving considerable success in multimodal tasks, such as text-image classification. The growing size of LMMs, however, results in a significant computational cost for fine-tuning these models for downstream tasks. Hence, prompt-based interaction strategy is studied to align modalities more efficiently. In this context, we propose a novel efficient prompt-based multimodal interaction strategy, namely Efficient Prompt Interaction for text-image Classification (EPIC). Specifically, we utilize temporal prompts on intermediate layers, and integrate different modalities with similarity-based prompt interaction, to leverage sufficient information exchange between modalities. Utilizing this approach, our method achieves reduced computational resource consumption and fewer trainable parameters (about 1\% of the foundation model) compared to other fine-tuning strategies. Furthermore, it demonstrates superior performance on the UPMC-Food101 and SNLI-VE datasets, while achieving comparable performance on the MM-IMDB dataset.