Comprehensive Evaluation of Large Multimodal Models for Nutrition Analysis: A New Benchmark Enriched with Contextual Metadata
作者: Bruce Coburn, Jiangpeng He, Megan E. Rollo, Satvinder S. Dhaliwal, Deborah A. Kerr, Fengqing Zhu
分类: cs.CV
发布日期: 2025-07-09 (更新: 2025-10-03)
备注: The extended full version of the accepted paper in 2025 IEEE BHI conference with title: Evaluating Large Multimodal Models for Nutrition Analysis: A New Benchmark Enriched with Contextual Metadata. Dataset is available at: https://skynet.ecn.purdue.edu/~coburn6/ACETADA/
💡 一句话要点
提出ACETADA基准,评估上下文元数据增强的大型多模态模型在营养分析中的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 营养分析 上下文感知 大型语言模型 食物图像 数据集 推理修饰符
📋 核心要点
- 现有营养分析方法主要依赖专有模型,缺乏对开源LLM的全面评估,且忽略了上下文元数据的影响。
- 论文提出利用GPS坐标、时间戳等上下文元数据增强LMM的营养分析能力,并结合多种推理修饰符。
- 实验结果表明,整合上下文元数据能显著降低营养价值预测的平均绝对误差和平均绝对百分比误差。
📝 摘要(中文)
大型多模态模型(LMMs)越来越多地应用于膳食图像的营养分析。然而,现有工作主要评估GPT-4等专有模型,对更广泛的LLM探索不足。此外,整合上下文元数据及其与各种推理修饰符的交互作用的影响在很大程度上仍未被探索。本文研究了如何利用从GPS坐标(转换为位置/场所类型)、时间戳(转换为膳食/日期类型)以及食物项目推导出的上下文元数据来增强LMM在估计关键营养价值(包括卡路里、宏量营养素(蛋白质、碳水化合物、脂肪)和份量大小)方面的性能。我们还引入了ACETADA,这是一个新的食物图像数据集,计划公开发布。该开放数据集提供由营养师验证的营养信息,并作为我们分析的基础。我们的评估涵盖八个LMM(四个开源和四个闭源),首先确定了上下文元数据集成优于仅使用图像的直接提示。然后,我们展示了上下文信息的整合如何增强推理修饰符(如思维链、多模态思维链、尺度提示、少样本和专家角色)的有效性。实验结果表明,通过直接提示策略智能地应用元数据集成可以显著降低预测营养价值的平均绝对误差(MAE)和平均绝对百分比误差(MAPE)。这项工作突出了上下文感知LMM在改进营养分析方面的潜力。
🔬 方法详解
问题定义:现有基于图像的营养分析方法,特别是使用大型多模态模型时,主要集中在闭源模型(如GPT-4)上,对开源模型的研究不足。同时,忽略了图像之外的上下文信息(如地理位置、时间等)对营养分析的潜在影响。现有方法缺乏对上下文信息与推理策略之间相互作用的深入理解,导致营养分析的准确性受限。
核心思路:论文的核心思路是利用图像的上下文元数据(GPS坐标和时间戳)来增强大型多模态模型在营养分析任务中的性能。通过将GPS坐标转换为位置/场所类型,将时间戳转换为膳食/日期类型,从而为模型提供更丰富的上下文信息。这种方法旨在模拟人类在进行营养分析时会考虑的各种因素,从而提高模型的准确性和可靠性。
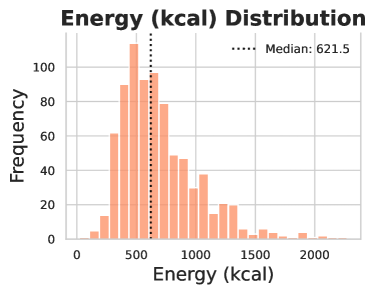
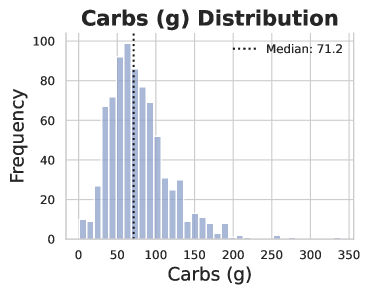
技术框架:整体框架包括以下几个主要阶段:1) 数据集构建:构建包含食物图像和营养信息的ACETADA数据集,并由营养师进行验证。2) 元数据提取与转换:从图像中提取GPS坐标和时间戳,并将它们转换为有意义的上下文信息(如餐厅类型、用餐时间)。3) 模型训练与评估:使用不同的LMM(包括开源和闭源模型),结合不同的推理修饰符(如思维链、少样本学习等),在ACETADA数据集上进行训练和评估。4) 性能分析:分析上下文元数据和推理修饰符对模型性能的影响,并比较不同模型的表现。
关键创新:论文的关键创新在于:1) 提出了ACETADA数据集,这是一个包含上下文元数据的公开营养分析数据集。2) 系统地研究了上下文元数据对LMM营养分析性能的影响。3) 探索了上下文元数据与各种推理修饰符之间的相互作用。与现有方法相比,该论文更全面地评估了LMM在营养分析中的潜力,并强调了上下文信息的重要性。
关键设计:论文的关键设计包括:1) 上下文元数据的转换方式:将GPS坐标转换为位置/场所类型,将时间戳转换为膳食/日期类型,以便模型更好地理解。2) 推理修饰符的选择:选择了思维链、多模态思维链、尺度提示、少样本和专家角色等多种推理修饰符,以探索它们与上下文元数据的协同作用。3) 评估指标:使用平均绝对误差(MAE)和平均绝对百分比误差(MAPE)来评估模型的性能。
🖼️ 关键图片
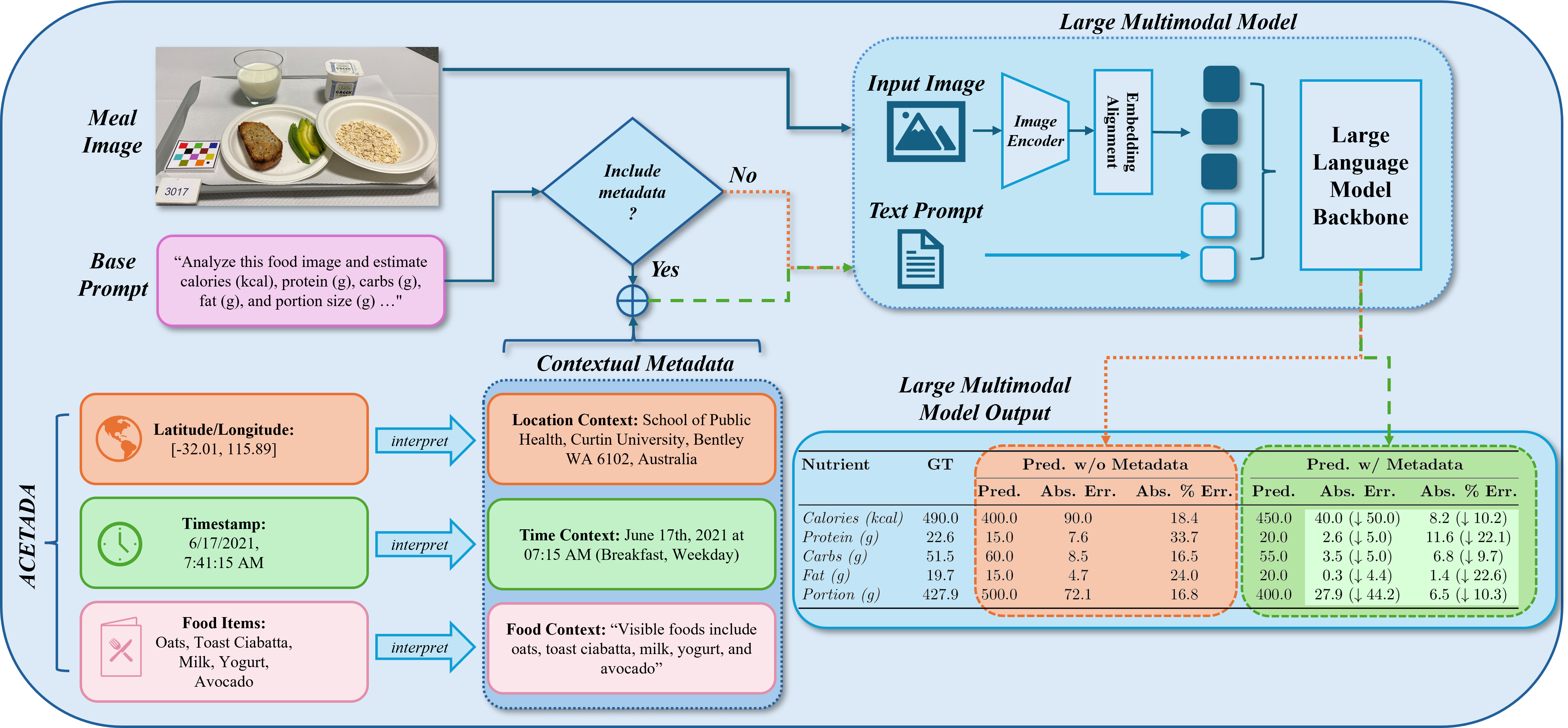
📊 实验亮点
实验结果表明,整合上下文元数据能够显著降低营养价值预测的误差。例如,通过简单的提示策略应用元数据集成,可以有效降低平均绝对误差(MAE)和平均绝对百分比误差(MAPE)。该研究还发现,上下文元数据能够增强推理修饰符(如思维链)的有效性,进一步提升模型的性能。
🎯 应用场景
该研究成果可应用于智能膳食推荐系统、个性化营养指导APP等领域。通过结合食物图像和上下文信息,可以更准确地评估膳食的营养价值,为用户提供更科学的饮食建议。未来,该技术有望在医疗健康、运动健身等领域发挥重要作用,提升人们的健康水平。
📄 摘要(原文)
Large Multimodal Models (LMMs) are increasingly applied to meal images for nutrition analysis. However, existing work primarily evaluates proprietary models, such as GPT-4. This leaves the broad range of LLMs underexplored. Additionally, the influence of integrating contextual metadata and its interaction with various reasoning modifiers remains largely uncharted. This work investigates how interpreting contextual metadata derived from GPS coordinates (converted to location/venue type), timestamps (transformed into meal/day type), and the food items present can enhance LMM performance in estimating key nutritional values. These values include calories, macronutrients (protein, carbohydrates, fat), and portion sizes. We also introduce \textbf{ACETADA}, a new food-image dataset slated for public release. This open dataset provides nutrition information verified by the dietitian and serves as the foundation for our analysis. Our evaluation across eight LMMs (four open-weight and four closed-weight) first establishes the benefit of contextual metadata integration over straightforward prompting with images alone. We then demonstrate how this incorporation of contextual information enhances the efficacy of reasoning modifiers, such as Chain-of-Thought, Multimodal Chain-of-Thought, Scale Hint, Few-Shot, and Expert Persona. Empirical results show that integrating metadata intelligently, when applied through straightforward prompting strategies, can significantly reduce the Mean Absolute Error (MAE) and Mean Absolute Percentage Error (MAPE) in predicted nutritional values. This work highlights the potential of context-aware LMMs for improved nutrition analysis.