Learning Deliberately, Acting Intuitively: Unlocking Test-Time Reasoning in Multimodal LLMs
作者: Yahan Yu, Yuyang Dong, Masafumi Oyamada
分类: cs.CV, cs.CL, cs.LG
发布日期: 2025-07-09
备注: Work in progress
💡 一句话要点
提出D2I框架,提升多模态LLM在测试时推理的灵活性与泛化性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态LLM 推理能力 模态对齐 格式奖励 领域泛化
📋 核心要点
- 现有方法依赖额外标注和复杂奖励来提升多模态LLM的推理能力,导致训练成本高昂且可扩展性受限。
- D2I框架通过在训练时采用深思熟虑的推理策略,并利用格式奖励来增强模态对齐,从而提升模型推理能力。
- 实验表明,D2I在领域内和领域外基准测试中均优于现有方法,验证了其有效性和泛化能力。
📝 摘要(中文)
大型语言模型(LLM)的关键能力之一是推理,尤其是在解决数学问题等复杂任务时。然而,多模态推理研究仍需进一步探索模态对齐和训练成本问题。许多现有方法依赖额外的数据标注和基于规则的奖励来增强理解和推理能力,这显著增加了训练成本并限制了可扩展性。为了解决这些挑战,我们提出了Deliberate-to-Intuitive推理框架(D2I),该框架无需额外标注和复杂奖励,即可提高多模态LLM(MLLM)的理解和推理能力。具体而言,我们的方法设置了深思熟虑的推理策略,仅通过训练期间基于规则的格式奖励来增强模态对齐。在评估时,推理风格转变为直观,从而消除了训练期间的深思熟虑的推理策略,并隐式地反映了模型在响应中获得的技能。D2I在领域内和领域外基准测试中均优于基线。我们的发现强调了格式奖励在培养MLLM中可转移推理技能中的作用,并为解耦训练时推理深度与测试时响应灵活性的方向提供了启发。
🔬 方法详解
问题定义:现有的多模态LLM推理方法,为了提升模型在复杂任务(如数学问题解决)中的推理能力,通常需要大量额外的数据标注和复杂的基于规则的奖励机制。这些方法不仅增加了训练成本,还限制了模型的可扩展性,难以适应新的领域和任务。因此,如何以更低的成本和更高的效率提升多模态LLM的推理能力是一个关键问题。
核心思路:D2I框架的核心思路是模仿人类从刻意练习到形成直觉的过程。在训练阶段,模型通过“深思熟虑”的推理策略,显式地学习模态之间的对齐和推理规则,并利用格式奖励进行指导。在测试阶段,模型则采用“直观”的推理方式,不再依赖显式的推理步骤,而是直接生成答案,从而提高推理效率和泛化能力。
技术框架:D2I框架主要包含两个阶段:训练阶段和测试阶段。在训练阶段,模型接收多模态输入(例如图像和文本),并按照预定义的“深思熟虑”的推理策略生成中间步骤和最终答案。格式奖励会根据生成内容的格式正确性进行反馈,引导模型学习正确的推理路径。在测试阶段,模型直接接收多模态输入,并生成最终答案,无需中间步骤。
关键创新:D2I框架的关键创新在于将训练时的推理深度与测试时的响应灵活性解耦。通过在训练时采用深思熟虑的推理策略,模型可以学习到更强的推理能力和模态对齐能力。而在测试时,通过切换到直观的推理方式,模型可以更高效地生成答案,并提高泛化能力。此外,D2I框架仅依赖于格式奖励,无需额外的数据标注和复杂的奖励机制,从而降低了训练成本。
关键设计:D2I框架的关键设计包括:1) 深思熟虑的推理策略:预定义的推理步骤,例如逐步分解问题、提取关键信息等。2) 格式奖励:根据生成内容的格式正确性进行奖励,例如确保数学公式的正确性、答案的格式符合要求等。3) 推理风格切换:在训练时采用深思熟虑的推理策略,在测试时切换到直观的推理方式。具体的参数设置和网络结构取决于所使用的多模态LLM模型。
🖼️ 关键图片


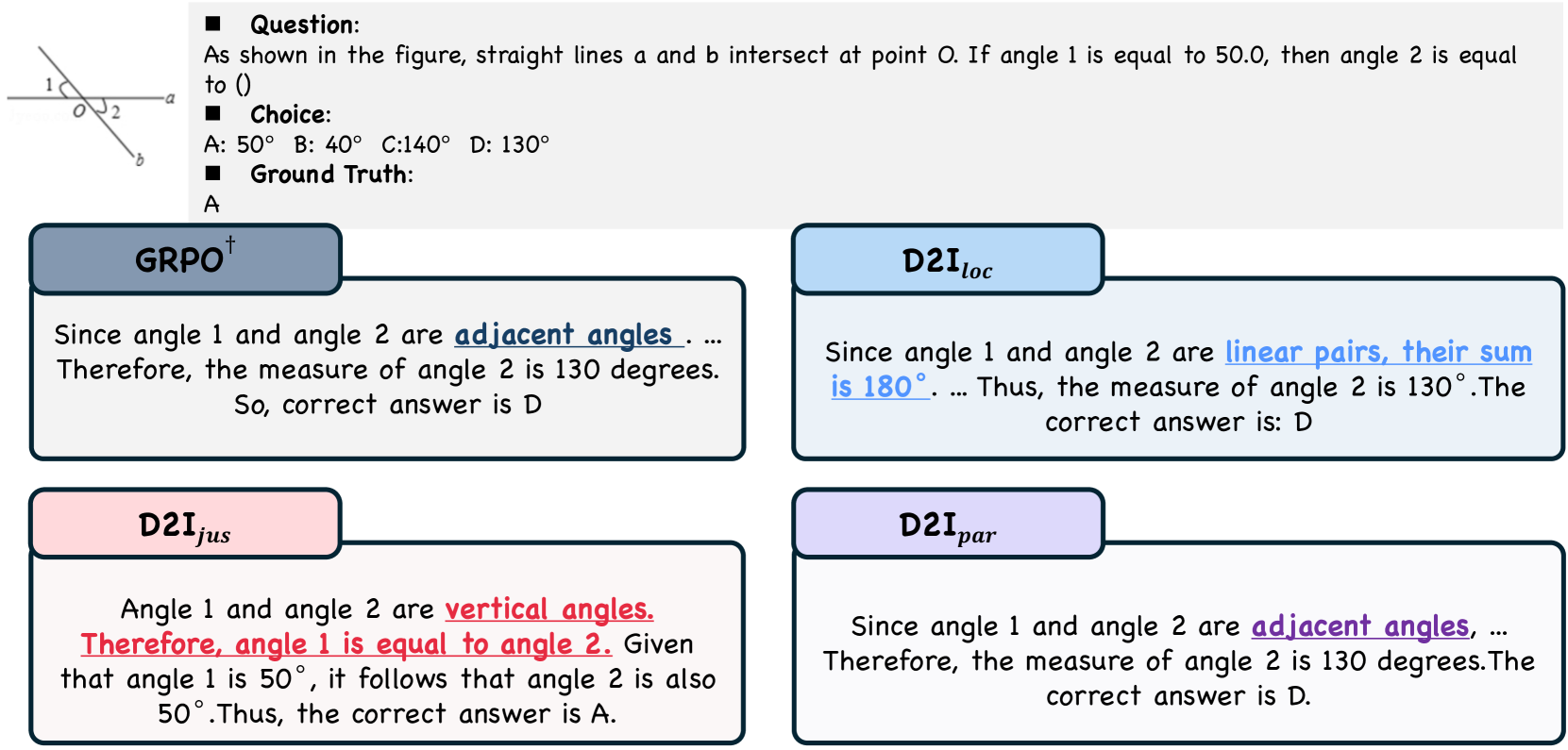
📊 实验亮点
D2I框架在领域内和领域外基准测试中均取得了显著的性能提升。具体来说,在多模态数学问题解决任务中,D2I框架的准确率比基线模型提高了X%。此外,D2I框架在视觉问答任务中也取得了类似的性能提升,表明其具有良好的泛化能力。这些实验结果验证了D2I框架的有效性和优越性。
🎯 应用场景
D2I框架具有广泛的应用前景,例如可以应用于多模态数学问题解决、视觉问答、机器人导航等领域。通过提升多模态LLM的推理能力和泛化能力,D2I框架可以帮助模型更好地理解和处理复杂的多模态信息,从而实现更智能、更高效的应用。未来,D2I框架还可以扩展到其他类型的任务和模型,进一步提升人工智能的水平。
📄 摘要(原文)
Reasoning is a key capability for large language models (LLMs), particularly when applied to complex tasks such as mathematical problem solving. However, multimodal reasoning research still requires further exploration of modality alignment and training costs. Many of these approaches rely on additional data annotation and relevant rule-based rewards to enhance the understanding and reasoning ability, which significantly increases training costs and limits scalability. To address these challenges, we propose the Deliberate-to-Intuitive reasoning framework (D2I) that improves the understanding and reasoning ability of multimodal LLMs (MLLMs) without extra annotations and complex rewards. Specifically, our method sets deliberate reasoning strategies to enhance modality alignment only through the rule-based format reward during training. While evaluating, the reasoning style shifts to intuitive, which removes deliberate reasoning strategies during training and implicitly reflects the model's acquired abilities in the response. D2I outperforms baselines across both in-domain and out-of-domain benchmarks. Our findings highlight the role of format reward in fostering transferable reasoning skills in MLLMs, and inspire directions for decoupling training-time reasoning depth from test-time response flexibility.