MK-Pose: Category-Level Object Pose Estimation via Multimodal-Based Keypoint Learning
作者: Yifan Yang, Peili Song, Enfan Lan, Dong Liu, Jingtai Liu
分类: cs.CV, cs.RO
发布日期: 2025-07-09
🔗 代码/项目: GITHUB
💡 一句话要点
提出MK-Pose以解决类别级物体姿态估计问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 类别级姿态估计 多模态学习 关键点检测 图增强特征融合 自监督学习
📋 核心要点
- 现有方法在物体遮挡和跨实例、跨类别的泛化能力上存在不足,限制了类别级物体姿态估计的应用。
- 本文提出的MK-Pose框架通过多模态学习,结合RGB图像、点云和文本描述,提升了姿态估计的准确性和鲁棒性。
- 实验结果显示,MK-Pose在CAMERA25和REAL275数据集上表现优异,IoU和平均精度均超越了现有最先进方法。
📝 摘要(中文)
类别级物体姿态估计是指在已知类别的情况下预测物体的姿态,而无需对单个实例的先验知识。这在仓库自动化和制造等应用中至关重要。现有方法依赖于RGB图像或点云数据,常常在物体遮挡和跨实例、跨类别的泛化方面面临挑战。本文提出了一种基于多模态的关键点学习框架MK-Pose,集成了RGB图像、点云和类别级文本描述。该模型使用自监督关键点检测模块,增强了基于注意力的查询生成、软热图匹配和基于图的关系建模。此外,设计了图增强特征融合模块,以整合局部几何信息和全局上下文。MK-Pose在CAMERA25和REAL275数据集上进行了评估,并在HouseCat6D数据集上测试了跨数据集能力。结果表明,MK-Pose在IoU和平均精度上均优于现有的最先进方法,且无需形状先验。
🔬 方法详解
问题定义:本文旨在解决类别级物体姿态估计问题,现有方法在处理物体遮挡和不同实例、类别的泛化能力上存在明显不足。
核心思路:MK-Pose通过多模态关键点学习,融合RGB图像、点云和文本描述,利用自监督学习提升关键点检测的准确性和鲁棒性。
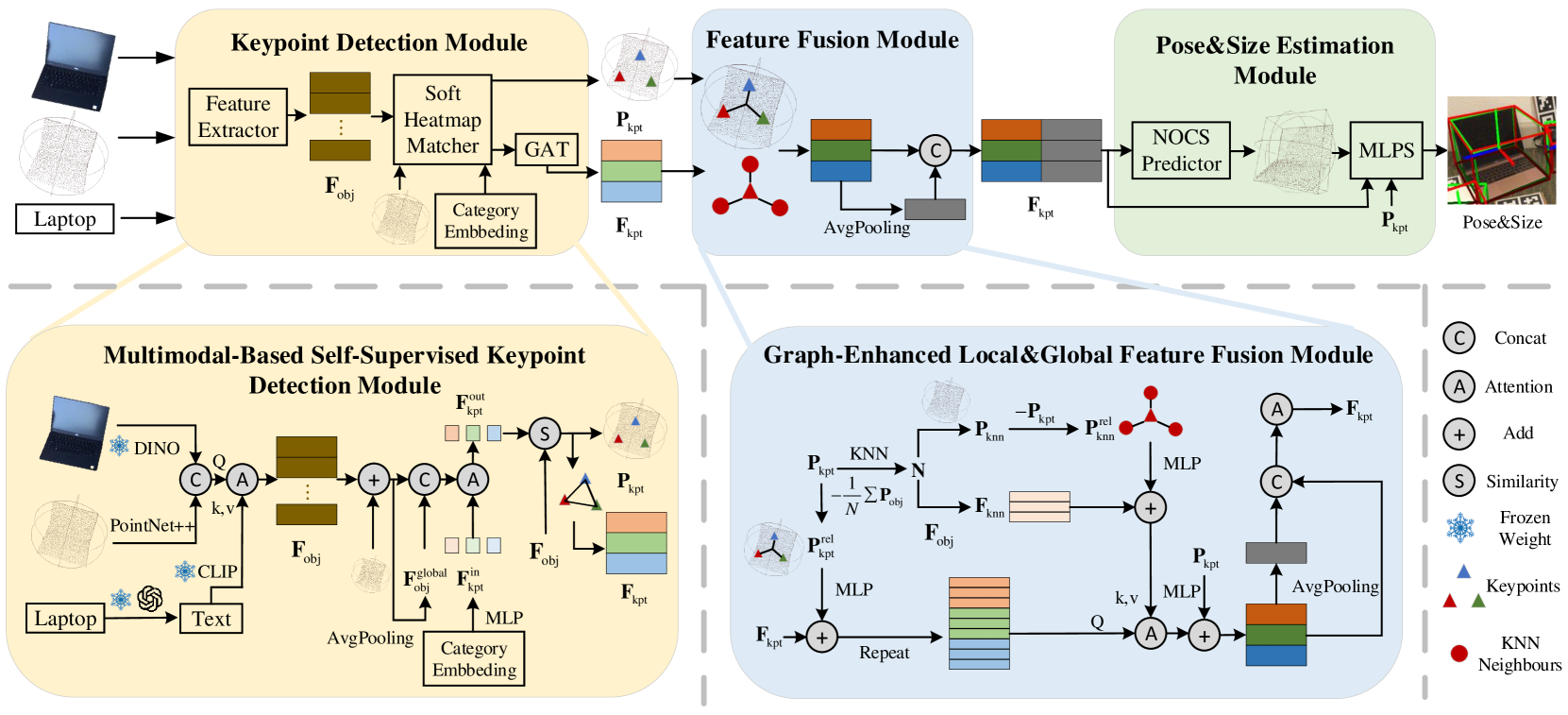
技术框架:MK-Pose的整体架构包括自监督关键点检测模块和图增强特征融合模块。前者负责关键点的检测和生成,后者则整合局部几何信息与全局上下文。
关键创新:MK-Pose的主要创新在于其多模态学习框架,尤其是基于注意力的查询生成和图关系建模,与传统方法相比,显著提升了姿态估计的准确性。
关键设计:模型采用自监督学习策略,设计了软热图匹配和图增强特征融合,确保了局部与全局信息的有效结合。
🖼️ 关键图片


📊 实验亮点
MK-Pose在CAMERA25和REAL275数据集上的实验结果显示,其在IoU和平均精度上均超过了现有最先进的方法,具体提升幅度未明确说明,但表明了其在类别级物体姿态估计中的优越性。代码将公开发布,便于后续研究和应用。
🎯 应用场景
该研究在仓库自动化、制造业和机器人操作等领域具有广泛的应用潜力。通过提高物体姿态估计的准确性,MK-Pose能够优化物体抓取、搬运和分类等任务,进而提升生产效率和自动化水平。未来,该技术有望在智能制造和自主机器人等领域发挥更大作用。
📄 摘要(原文)
Category-level object pose estimation, which predicts the pose of objects within a known category without prior knowledge of individual instances, is essential in applications like warehouse automation and manufacturing. Existing methods relying on RGB images or point cloud data often struggle with object occlusion and generalization across different instances and categories. This paper proposes a multimodal-based keypoint learning framework (MK-Pose) that integrates RGB images, point clouds, and category-level textual descriptions. The model uses a self-supervised keypoint detection module enhanced with attention-based query generation, soft heatmap matching and graph-based relational modeling. Additionally, a graph-enhanced feature fusion module is designed to integrate local geometric information and global context. MK-Pose is evaluated on CAMERA25 and REAL275 dataset, and is further tested for cross-dataset capability on HouseCat6D dataset. The results demonstrate that MK-Pose outperforms existing state-of-the-art methods in both IoU and average precision without shape priors. Codes will be released at \href{https://github.com/yangyifanYYF/MK-Pose}{https://github.com/yangyifanYYF/MK-Pose}.