SPARC: Concept-Aligned Sparse Autoencoders for Cross-Model and Cross-Modal Interpretability
作者: Ali Nasiri-Sarvi, Hassan Rivaz, Mahdi S. Hosseini
分类: cs.CV, cs.AI
发布日期: 2025-07-07
🔗 代码/项目: GITHUB
💡 一句话要点
SPARC:概念对齐的稀疏自编码器,实现跨模型和跨模态的可解释性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏自编码器 可解释性 跨模型 跨模态 概念对齐 表示学习 多模态学习
📋 核心要点
- 现有可解释性方法为每个模型单独学习概念,导致概念空间不兼容,限制了跨模型理解。
- SPARC通过全局TopK稀疏和交叉重建损失,学习跨模型和模态的统一对齐的潜在空间。
- 实验表明,SPARC显著提高了概念对齐度,并支持文本引导定位和跨模态检索等应用。
📝 摘要(中文)
理解不同AI模型如何编码相同的高级概念(如对象或属性)仍然具有挑战性,因为每个模型通常产生其自身孤立的表示。现有的可解释性方法,如稀疏自编码器(SAEs),为每个模型单独生成潜在概念,导致不兼容的概念空间并限制了跨模型的可解释性。为了解决这个问题,我们引入了SPARC(用于概念对齐表示的稀疏自编码器),这是一个新的框架,可以学习跨不同架构和模态(例如,像DINO这样的视觉模型和像CLIP这样的多模态模型)共享的单个统一的潜在空间。SPARC的对齐通过两个关键创新来强制执行:(1)全局TopK稀疏机制,确保所有输入流为给定概念激活相同的潜在维度;(2)交叉重建损失,明确鼓励模型之间的语义一致性。在Open Images上,SPARC显著提高了概念对齐,实现了0.80的Jaccard相似度,比以前的方法提高了三倍以上。SPARC创建了一个共享的稀疏潜在空间,其中各个维度通常对应于跨模型和模态的相似高级概念,从而可以直接比较不同架构如何表示相同的概念,而无需手动对齐或特定于模型的分析。由于这种对齐的表示,SPARC还支持实际应用,例如纯视觉模型中的文本引导空间定位以及跨模型/跨模态检索。代码和模型可在https://github.com/AtlasAnalyticsLab/SPARC获得。
🔬 方法详解
问题定义:现有可解释性方法,如稀疏自编码器(SAEs),在不同模型上独立学习潜在概念,导致概念空间不一致,难以进行跨模型和跨模态的比较和理解。不同模型对同一概念的表示方式缺乏统一的框架进行分析,阻碍了对模型内部机制的深入理解。
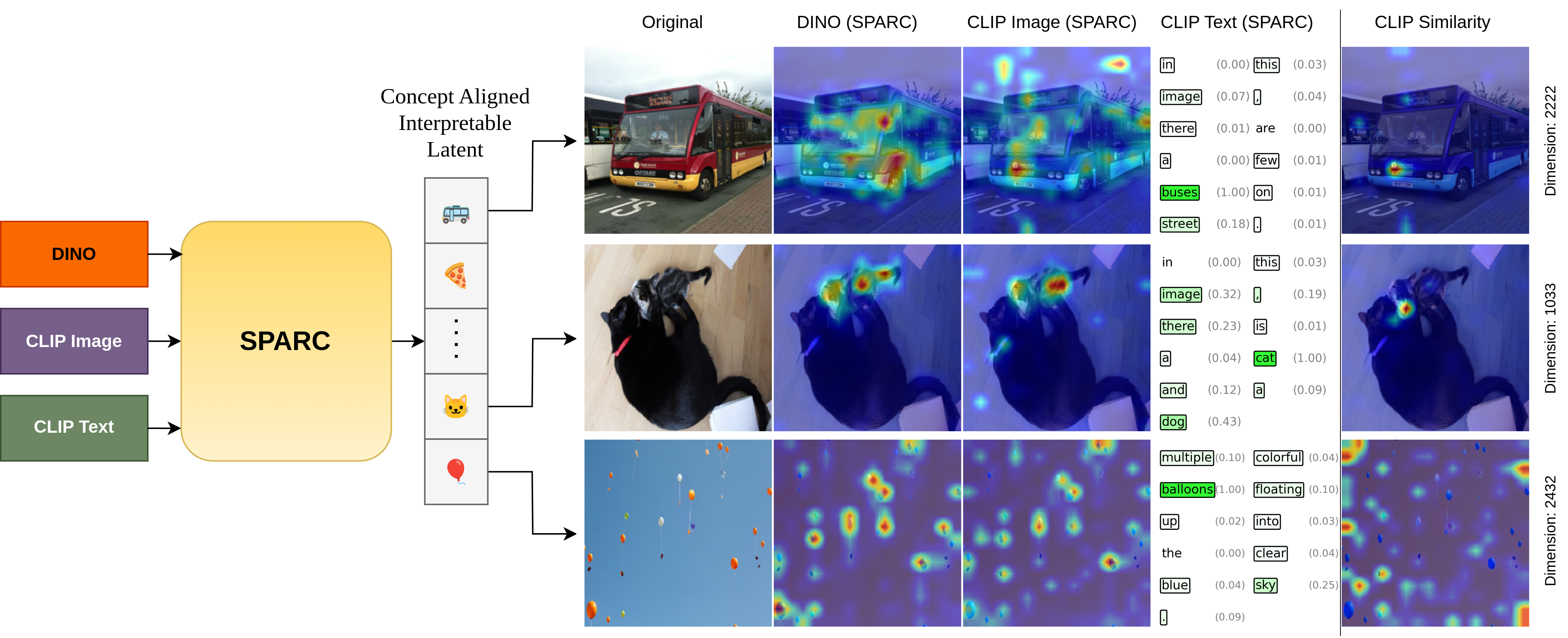
核心思路:SPARC的核心思路是学习一个跨模型和跨模态共享的、对齐的稀疏潜在空间。通过强制不同模型对同一概念激活相同的潜在维度,并鼓励模型之间的语义一致性,从而实现概念空间的一致性。这样,就可以直接比较不同模型如何表示相同的概念,而无需手动对齐或模型特定的分析。
技术框架:SPARC框架包含多个输入流(对应不同的模型或模态),每个输入流通过一个编码器映射到共享的潜在空间。该潜在空间通过全局TopK稀疏机制进行约束,确保只有最相关的维度被激活。然后,每个输入流通过一个解码器从共享的潜在空间重建。框架通过最小化重建损失和交叉重建损失来训练,其中交叉重建损失鼓励不同模型之间的语义一致性。
关键创新:SPARC的关键创新在于其概念对齐机制,包括全局TopK稀疏和交叉重建损失。全局TopK稀疏确保不同模型对同一概念激活相同的潜在维度,从而实现概念空间的一致性。交叉重建损失通过鼓励一个模型从另一个模型的潜在表示中重建输入,从而强制模型之间的语义一致性。这与传统的独立学习潜在概念的方法有本质区别。
关键设计:全局TopK稀疏选择每个batch中激活程度最高的K个神经元,其余神经元置零。交叉重建损失定义为:L_cross = E_{x_i, x_j} [||x_i - D_i(E_j(x_j))||^2],其中x_i和x_j是来自不同模型或模态的输入,E_i和D_i分别是模型i的编码器和解码器。损失函数还包括重建损失和L1正则化项,以保证重建质量和潜在空间的稀疏性。
🖼️ 关键图片


📊 实验亮点
SPARC在Open Images数据集上实现了显著的概念对齐提升,Jaccard相似度达到0.80,是现有方法的3倍以上。此外,SPARC还成功应用于文本引导的空间定位任务,证明了其在实际应用中的有效性。实验结果表明,SPARC能够学习到跨模型和跨模态的共享概念表示,为AI模型的可解释性研究提供了新的思路。
🎯 应用场景
SPARC具有广泛的应用前景,包括:1) 跨模型和跨模态的可解释性分析,帮助研究人员理解不同模型如何表示相同的概念;2) 知识迁移,可以将一个模型学习到的知识迁移到另一个模型;3) 跨模态检索,可以根据文本描述在视觉模型中定位目标对象;4) 模型调试和改进,通过分析潜在空间可以发现模型中的问题并进行改进。SPARC有望推动AI模型的可解释性和泛化能力。
📄 摘要(原文)
Understanding how different AI models encode the same high-level concepts, such as objects or attributes, remains challenging because each model typically produces its own isolated representation. Existing interpretability methods like Sparse Autoencoders (SAEs) produce latent concepts individually for each model, resulting in incompatible concept spaces and limiting cross-model interpretability. To address this, we introduce SPARC (Sparse Autoencoders for Aligned Representation of Concepts), a new framework that learns a single, unified latent space shared across diverse architectures and modalities (e.g., vision models like DINO, and multimodal models like CLIP). SPARC's alignment is enforced through two key innovations: (1) a Global TopK sparsity mechanism, ensuring all input streams activate identical latent dimensions for a given concept; and (2) a Cross-Reconstruction Loss, which explicitly encourages semantic consistency between models. On Open Images, SPARC dramatically improves concept alignment, achieving a Jaccard similarity of 0.80, more than tripling the alignment compared to previous methods. SPARC creates a shared sparse latent space where individual dimensions often correspond to similar high-level concepts across models and modalities, enabling direct comparison of how different architectures represent identical concepts without requiring manual alignment or model-specific analysis. As a consequence of this aligned representation, SPARC also enables practical applications such as text-guided spatial localization in vision-only models and cross-model/cross-modal retrieval. Code and models are available at https://github.com/AtlasAnalyticsLab/SPARC.