OpenWorldSAM: Extending SAM2 for Universal Image Segmentation with Language Prompts
作者: Shiting Xiao, Rishabh Kabra, Yuhang Li, Donghyun Lee, Joao Carreira, Priyadarshini Panda
分类: cs.CV
发布日期: 2025-07-07 (更新: 2025-11-12)
🔗 代码/项目: GITHUB
💡 一句话要点
提出OpenWorldSAM以解决开放词汇图像分割问题
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 开放词汇 图像分割 多模态嵌入 视觉-语言模型 实例意识 零-shot 学习 资源效率
📋 核心要点
- 现有方法在处理开放词汇和多样化类别时,往往无法有效地将文本语义转化为空间掩码,导致分割效果不佳。
- OpenWorldSAM通过集成轻量级视觉-语言模型的多模态嵌入,支持多种语言提示,提升了分割任务的灵活性和效率。
- 实验结果显示,OpenWorldSAM在多个基准测试中实现了最先进的性能,尤其在未见类别的零-shot 分割能力上表现突出。
📝 摘要(中文)
基于开放式语言提示进行物体分割的能力仍然是一个关键挑战,要求模型将文本语义与精确的空间掩码相结合,同时处理多样化和未见过的类别。我们提出了OpenWorldSAM,一个扩展了基于提示的Segment Anything Model v2 (SAM2)的框架,通过集成从轻量级视觉-语言模型(VLM)提取的多模态嵌入,适用于开放词汇场景。我们的研究遵循四个关键原则:统一提示、效率、实例意识和泛化能力。实验表明,OpenWorldSAM在多个基准测试中实现了开放词汇语义、实例和全景分割的最先进性能。
🔬 方法详解
问题定义:本论文旨在解决基于开放式语言提示的图像分割问题。现有方法在处理未见类别时,往往无法有效地将文本语义与空间掩码结合,导致分割效果不理想。
核心思路:OpenWorldSAM的核心思路是通过集成多模态嵌入,支持多种类型的语言提示,从而提升模型的灵活性和适应性。通过冻结SAM2和VLM的预训练组件,仅训练少量参数,显著提高了资源效率。
技术框架:OpenWorldSAM的整体架构包括多个模块:首先是输入的语言提示,接着通过VLM提取多模态嵌入,然后利用SAM2进行图像分割,最后通过后处理模块生成最终的分割结果。
关键创新:OpenWorldSAM的主要创新在于引入了新的位置平衡嵌入和交叉注意力层,增强了模型的空间理解能力,使其能够有效分割多个实例,并在开放词汇场景中表现出色。
关键设计:在模型设计中,冻结了SAM2和VLM的预训练组件,仅训练4.5百万个参数,使用COCO-stuff数据集进行训练。此外,采用了新的损失函数和网络结构,以提升模型的分割精度和效率。
🖼️ 关键图片

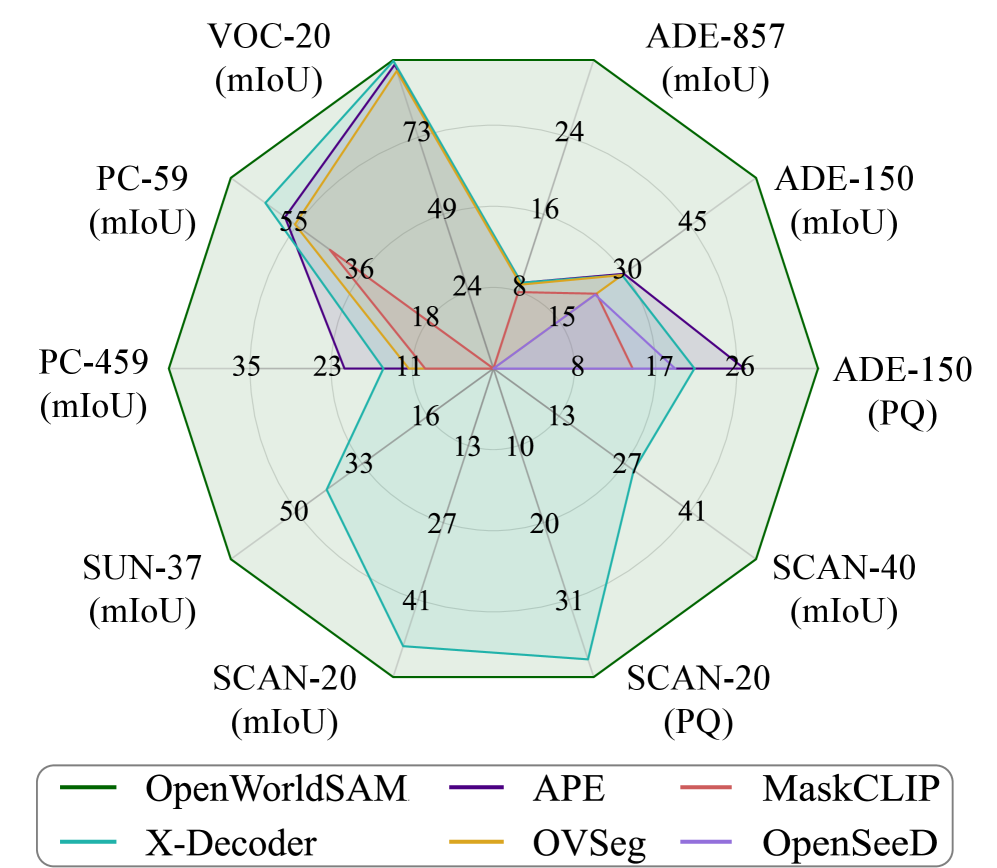

📊 实验亮点
OpenWorldSAM在多个基准测试中实现了最先进的性能,特别是在开放词汇语义、实例和全景分割任务上,展现出强大的零-shot 能力。与现有方法相比,模型在未见类别的分割精度上有显著提升,具体性能数据尚未披露。
🎯 应用场景
OpenWorldSAM在图像分割领域具有广泛的应用潜力,尤其适用于需要处理多样化和未见类别的任务,如自动驾驶、医疗影像分析和智能监控等。其灵活的提示机制和高效的资源利用,使得该模型在实际应用中具备较高的价值和影响力。
📄 摘要(原文)
The ability to segment objects based on open-ended language prompts remains a critical challenge, requiring models to ground textual semantics into precise spatial masks while handling diverse and unseen categories. We present OpenWorldSAM, a framework that extends the prompt-driven Segment Anything Model v2 (SAM2) to open-vocabulary scenarios by integrating multi-modal embeddings extracted from a lightweight vision-language model (VLM). Our approach is guided by four key principles: i) Unified prompting: OpenWorldSAM supports a diverse range of prompts, including category-level and sentence-level language descriptions, providing a flexible interface for various segmentation tasks. ii) Efficiency: By freezing the pre-trained components of SAM2 and the VLM, we train only 4.5 million parameters on the COCO-stuff dataset, achieving remarkable resource efficiency. iii) Instance Awareness: We enhance the model's spatial understanding through novel positional tie-breaker embeddings and cross-attention layers, enabling effective segmentation of multiple instances. iv) Generalization: OpenWorldSAM exhibits strong zero-shot capabilities, generalizing well on unseen categories and an open vocabulary of concepts without additional training. Extensive experiments demonstrate that OpenWorldSAM achieves state-of-the-art performance in open-vocabulary semantic, instance, and panoptic segmentation across multiple benchmarks. Code is available at https://github.com/GinnyXiao/OpenWorldSAM.