Neural-Driven Image Editing
作者: Pengfei Zhou, Jie Xia, Xiaopeng Peng, Wangbo Zhao, Zilong Ye, Zekai Li, Suorong Yang, Jiadong Pan, Yuanxiang Chen, Ziqiao Wang, Kai Wang, Qian Zheng, Hao Jin, Xiaojun Chang, Gang Pan, Shurong Dong, Kaipeng Zhang, Yang You
分类: cs.CV
发布日期: 2025-07-07 (更新: 2026-01-09)
备注: 22 pages, 14 figures
💡 一句话要点
LoongX:提出一种基于多模态神经信号驱动的免手动图像编辑方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经驱动图像编辑 脑机接口 多模态融合 扩散模型 免手动操作
📋 核心要点
- 传统图像编辑依赖手动提示,对运动或语言障碍人士不友好,存在可访问性问题。
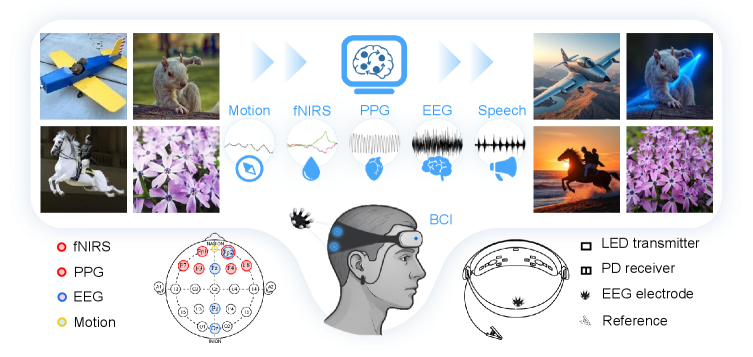
- LoongX利用脑机接口和生成模型,通过多模态神经生理信号驱动图像编辑,实现免手动操作。
- 实验表明,LoongX性能与文本驱动方法相当,神经信号结合语音时更优,验证了神经驱动生成模型的潜力。
📝 摘要(中文)
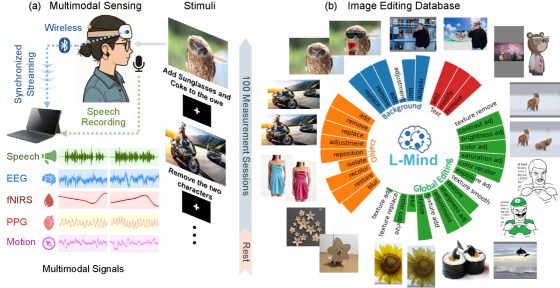
本文提出了一种名为LoongX的免手动图像编辑方法,该方法利用多模态神经生理信号驱动图像编辑,旨在解决传统图像编辑依赖手动操作,对运动或语言能力受限人群不友好的问题。LoongX利用最先进的扩散模型,该模型基于包含23928个图像编辑对的数据集进行训练,每个图像编辑对都与同步的脑电图(EEG)、功能性近红外光谱(fNIRS)、光电容积脉搏波(PPG)和头部运动信号配对,这些信号捕捉用户的意图。为了有效解决这些信号的异构性,LoongX集成了两个关键模块:跨尺度状态空间(CS3)模块,用于编码信息丰富的特定模态特征;动态门控融合(DGF)模块,用于将这些特征聚合到统一的潜在空间中,并通过在扩散Transformer (DiT)上进行微调,将该潜在空间与编辑语义对齐。此外,我们使用对比学习预训练编码器,以将认知状态与嵌入自然语言的语义意图对齐。大量实验表明,LoongX的性能与文本驱动的方法相当,并且在神经信号与语音结合时优于文本驱动的方法。代码和数据集已发布在项目网站上。
🔬 方法详解
问题定义:传统图像编辑方法依赖于手动输入文本提示或进行其他手动操作,这对于那些运动控制或语言能力有限的人来说是具有挑战性的。因此,论文旨在解决如何让这类人群也能方便地进行图像编辑的问题。现有方法的痛点在于需要用户具备一定的操作能力,限制了图像编辑的普及性。
核心思路:论文的核心思路是利用脑机接口(BCI)技术,通过捕捉用户的神经生理信号(如脑电图、近红外光谱等)来推断用户的编辑意图,并将其转化为图像编辑指令。这样,用户无需手动操作,仅通过“思考”即可完成图像编辑。这种设计的关键在于如何有效地解码神经信号,并将其与图像编辑的语义信息对齐。
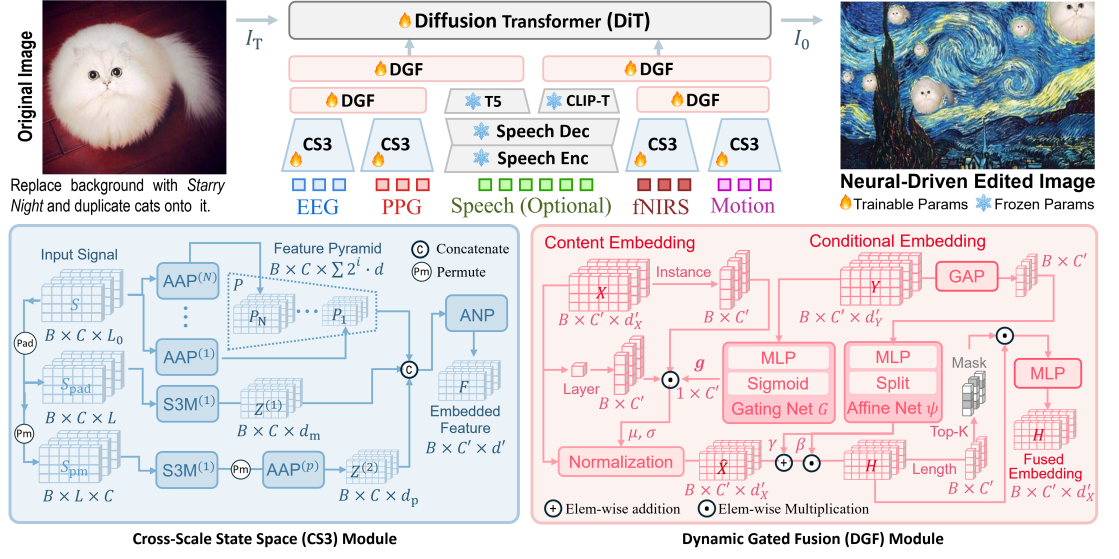
技术框架:LoongX的整体框架包含以下几个主要模块:1) 数据采集模块:收集图像编辑对以及对应的多模态神经生理信号(EEG, fNIRS, PPG, 头部运动)。2) 特征编码模块:使用跨尺度状态空间(CS3)模块对不同模态的神经信号进行编码,提取模态特定的信息特征。3) 特征融合模块:使用动态门控融合(DGF)模块将不同模态的特征融合到一个统一的潜在空间中。4) 语义对齐模块:通过在扩散Transformer (DiT)上进行微调,将融合后的潜在空间与图像编辑的语义信息对齐。5) 图像生成模块:利用扩散模型生成编辑后的图像。
关键创新:LoongX的关键创新在于:1) 提出了一个基于多模态神经生理信号的图像编辑框架,实现了免手动操作。2) 设计了跨尺度状态空间(CS3)模块和动态门控融合(DGF)模块,有效地处理了异构神经信号。3) 使用对比学习预训练编码器,将认知状态与语义意图对齐。与现有方法的本质区别在于,LoongX直接利用神经信号作为输入,无需人工干预。
关键设计:1) 跨尺度状态空间(CS3)模块的具体结构和参数设置未知。2) 动态门控融合(DGF)模块的门控机制如何实现,以及门控信号的来源未知。3) 扩散Transformer (DiT)的微调策略,包括损失函数、学习率等未知。4) 对比学习的损失函数和负样本选择策略未知。
🖼️ 关键图片
📊 实验亮点
LoongX的实验结果表明,其性能与文本驱动的图像编辑方法相当(CLIP-I: 0.6605 vs. 0.6558; DINO: 0.4812 vs. 0.4636)。更重要的是,当神经信号与语音结合时,LoongX的性能优于文本驱动的方法(CLIP-T: 0.2588 vs. 0.2549)。这些数据表明,LoongX在利用神经信号进行图像编辑方面具有显著的优势。
🎯 应用场景
LoongX具有广泛的应用前景,尤其是在辅助技术领域。它可以帮助运动障碍、语言障碍或其他认知障碍人士进行图像编辑和创作,提升他们的生活质量和创造力。此外,该技术还可以应用于艺术创作、设计等领域,为艺术家和设计师提供一种全新的创作方式。未来,随着脑机接口技术的不断发展,LoongX有望成为一种普及的图像编辑工具。
📄 摘要(原文)
Traditional image editing typically relies on manual prompting, making it labor-intensive and inaccessible to individuals with limited motor control or language abilities. Leveraging recent advances in brain-computer interfaces (BCIs) and generative models, we propose LoongX, a hands-free image editing approach driven by multimodal neurophysiological signals. LoongX utilizes state-of-the-art diffusion models trained on a comprehensive dataset of 23,928 image editing pairs, each paired with synchronized electroencephalography (EEG), functional near-infrared spectroscopy (fNIRS), photoplethysmography (PPG), and head motion signals that capture user intent. To effectively address the heterogeneity of these signals, LoongX integrates two key modules. The cross-scale state space (CS3) module encodes informative modality-specific features. The dynamic gated fusion (DGF) module further aggregates these features into a unified latent space, which is then aligned with edit semantics via fine-tuning on a diffusion transformer (DiT). Additionally, we pre-train the encoders using contrastive learning to align cognitive states with semantic intentions from embedded natural language. Extensive experiments demonstrate that LoongX achieves performance comparable to text-driven methods (CLIP-I: 0.6605 vs. 0.6558; DINO: 0.4812 vs. 0.4636) and outperforms them when neural signals are combined with speech (CLIP-T: 0.2588 vs. 0.2549). These results highlight the promise of neural-driven generative models in enabling accessible, intuitive image editing and open new directions for cognitive-driven creative technologies. The code and dataset are released on the project website: https://loongx1.github.io.