Beyond Simple Edits: X-Planner for Complex Instruction-Based Image Editing
作者: Chun-Hsiao Yeh, Yilin Wang, Nanxuan Zhao, Richard Zhang, Yuheng Li, Yi Ma, Krishna Kumar Singh
分类: cs.CV
发布日期: 2025-07-07
备注: Project page: https://danielchyeh.github.io/x-planner/
💡 一句话要点
提出X-Planner,利用MLLM规划复杂指令图像编辑,提升编辑质量和身份保持。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像编辑 多模态大语言模型 思维链推理 指令规划 自动掩码生成
📋 核心要点
- 现有文本引导的图像编辑方法难以理解复杂指令,且身份保持效果不佳,依赖手动掩码。
- X-Planner利用MLLM进行思维链推理,将复杂指令分解为简单子指令,自动生成编辑类型和掩码。
- 论文提出自动化数据生成pipeline训练X-Planner,并在复杂编辑基准上取得SOTA结果。
📝 摘要(中文)
现有的基于扩散模型的图像编辑方法在处理复杂的、间接的指令时表现不佳,并且常常面临身份保持差、意外编辑等问题,同时还严重依赖手动掩码。为了解决这些挑战,我们提出了X-Planner,一个基于多模态大型语言模型(MLLM)的规划系统,有效地将用户意图与编辑模型的能力联系起来。X-Planner采用思维链推理,将复杂的指令系统地分解为更简单、更清晰的子指令。对于每个子指令,X-Planner自动生成精确的编辑类型和分割掩码,无需手动干预,并确保局部化的、身份保持的编辑。此外,我们还提出了一种新颖的自动化pipeline,用于生成大规模数据来训练X-Planner,在现有基准和我们新引入的复杂编辑基准上都取得了最先进的结果。
🔬 方法详解
问题定义:现有基于扩散模型的图像编辑方法在处理复杂、间接的指令时存在困难,例如用户希望“让照片中的人看起来更年轻”,模型可能难以直接理解并执行。此外,这些方法常常无法很好地保持图像中其他部分的原始信息,容易出现不必要的修改,并且通常需要人工提供精确的分割掩码,限制了其自动化程度和易用性。
核心思路:X-Planner的核心思路是利用多模态大型语言模型(MLLM)的强大推理能力,将复杂的编辑指令分解为一系列更简单、更明确的子指令。通过这种“分而治之”的策略,模型可以更容易地理解用户的真实意图,并生成更精确的编辑方案。同时,X-Planner还负责自动生成编辑所需的分割掩码,避免了人工干预,提高了编辑效率。
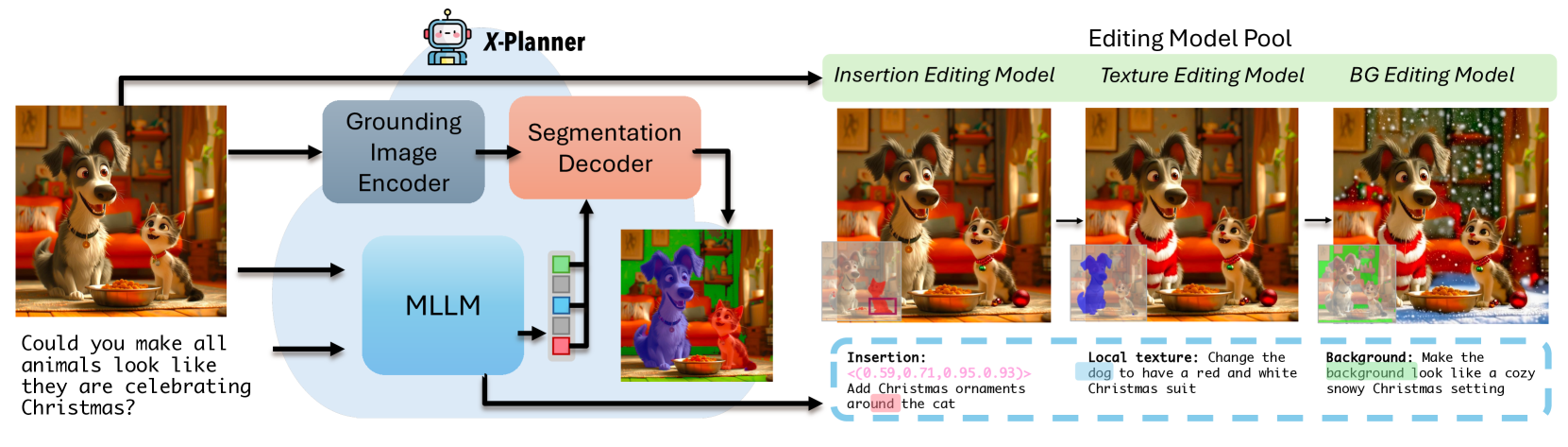
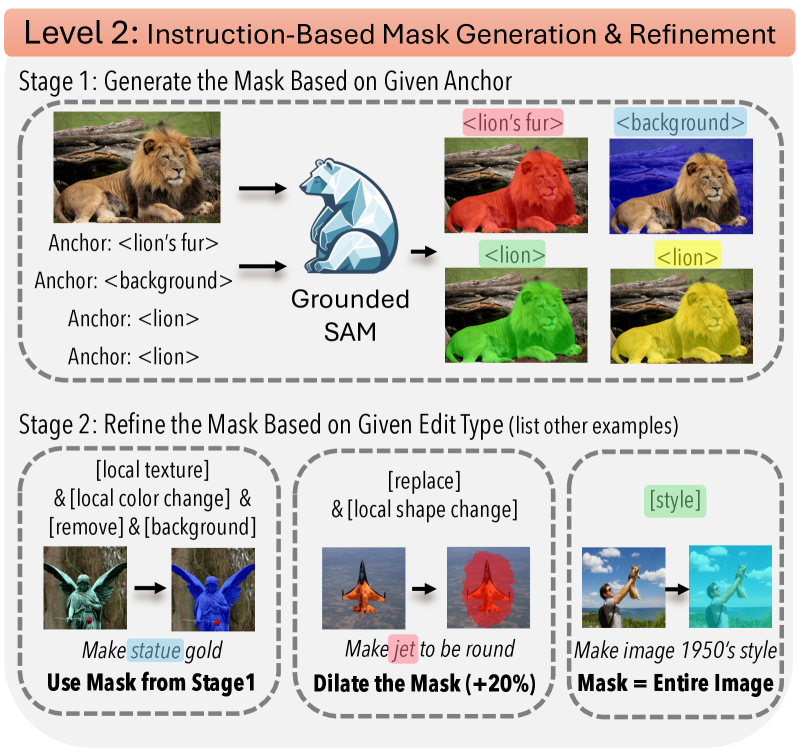
技术框架:X-Planner的整体框架包含以下几个主要阶段:1) 指令分解:MLLM接收用户输入的复杂编辑指令,并利用思维链推理将其分解为一系列简单的子指令。2) 编辑类型预测:对于每个子指令,MLLM预测需要执行的编辑类型,例如“改变发型”、“调整光照”等。3) 掩码生成:MLLM生成与每个子指令相关的分割掩码,用于指定需要进行编辑的图像区域。4) 图像编辑:根据分解后的子指令、编辑类型和分割掩码,使用现有的图像编辑模型(例如基于扩散模型的模型)进行图像编辑。
关键创新:X-Planner的关键创新在于利用MLLM进行指令规划和自动掩码生成。与现有方法相比,X-Planner无需人工提供掩码,并且能够更好地理解和执行复杂的编辑指令。此外,论文还提出了一个自动化数据生成pipeline,用于训练X-Planner,解决了训练数据不足的问题。
关键设计:论文的关键设计包括:1) 使用思维链推理来分解复杂指令,提高MLLM的推理能力。2) 设计了专门的损失函数来训练MLLM,使其能够准确地预测编辑类型和生成分割掩码。3) 提出了一个基于规则和图像处理技术的自动化数据生成pipeline,用于生成大规模的训练数据。具体参数设置和网络结构细节在论文中进行了详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
X-Planner在现有基准和论文提出的复杂编辑基准上都取得了SOTA结果。具体性能数据(未知),表明X-Planner能够更好地理解和执行复杂的编辑指令,并生成更高质量的编辑结果。与现有方法相比,X-Planner在身份保持和编辑精度方面都有显著提升。
🎯 应用场景
X-Planner具有广泛的应用前景,例如照片美化、虚拟试穿、产品设计等。它可以帮助用户轻松地实现复杂的图像编辑任务,无需专业的图像处理技能。未来,X-Planner可以集成到各种图像编辑软件和在线平台中,为用户提供更智能、更便捷的图像编辑体验。
📄 摘要(原文)
Recent diffusion-based image editing methods have significantly advanced text-guided tasks but often struggle to interpret complex, indirect instructions. Moreover, current models frequently suffer from poor identity preservation, unintended edits, or rely heavily on manual masks. To address these challenges, we introduce X-Planner, a Multimodal Large Language Model (MLLM)-based planning system that effectively bridges user intent with editing model capabilities. X-Planner employs chain-of-thought reasoning to systematically decompose complex instructions into simpler, clear sub-instructions. For each sub-instruction, X-Planner automatically generates precise edit types and segmentation masks, eliminating manual intervention and ensuring localized, identity-preserving edits. Additionally, we propose a novel automated pipeline for generating large-scale data to train X-Planner which achieves state-of-the-art results on both existing benchmarks and our newly introduced complex editing benchmark.