Open Vision Reasoner: Transferring Linguistic Cognitive Behavior for Visual Reasoning
作者: Yana Wei, Liang Zhao, Jianjian Sun, Kangheng Lin, Jisheng Yin, Jingcheng Hu, Yinmin Zhang, En Yu, Haoran Lv, Zejia Weng, Jia Wang, Chunrui Han, Yuang Peng, Qi Han, Zheng Ge, Xiangyu Zhang, Daxin Jiang, Vishal M. Patel
分类: cs.CV, cs.CL
发布日期: 2025-07-07 (更新: 2025-09-19)
备注: NeurIPS 2025
💡 一句话要点
提出Open Vision Reasoner,通过迁移语言认知行为增强多模态视觉推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视觉推理 强化学习 语言模型 认知行为
📋 核心要点
- 现有MLLM在视觉推理方面存在不足,缺乏LLM通过可验证奖励强化的认知行为。
- 通过大规模语言冷启动微调和多模态强化学习,将LLM的认知行为迁移到MLLM。
- Open-Vision-Reasoner在多个视觉推理基准测试中取得了SOTA性能,验证了方法的有效性。
📝 摘要(中文)
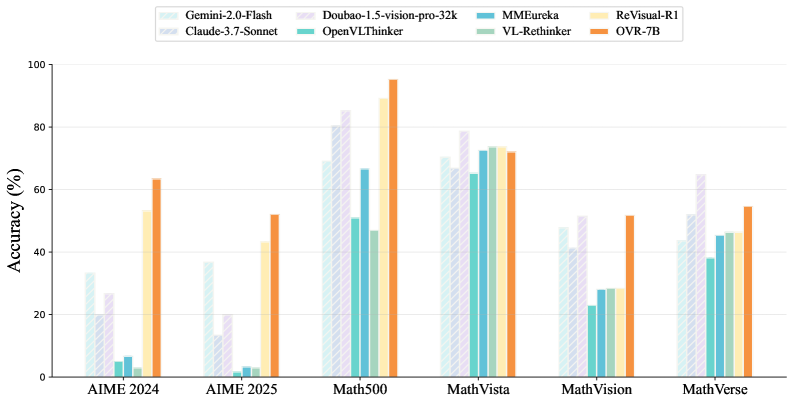
本文研究如何将大型语言模型(LLM)的推理能力迁移到多模态LLM(MLLM)以提升视觉推理能力。作者基于Qwen2.5-VL-7B,提出了一个两阶段范式:首先进行大规模的语言冷启动微调,然后进行近1000步的多模态强化学习,其规模超过了以往所有开源工作。研究揭示了三个基本见解:1)由于语言心理意象,行为迁移在冷启动中出人意料地提前出现;2)冷启动广泛记忆视觉行为,而强化学习则 критически 区分并扩大有效模式;3)迁移策略性地偏爱高实用性的行为,例如视觉反思。最终模型Open-Vision-Reasoner(OVR)在一系列推理基准测试中实现了最先进的性能,包括MATH500上的95.3%,MathVision上的51.8%和MathVerse上的54.6%。作者发布了模型、数据和训练动态,以促进更强大、行为对齐的多模态推理器的开发。
🔬 方法详解
问题定义:现有的大型多模态模型(MLLM)在视觉推理能力上仍有提升空间,尤其是在复杂场景下的推理能力。现有的方法通常缺乏有效的机制来学习和利用视觉信息进行深度推理,无法像人类一样进行视觉反思和策略性决策。
核心思路:本文的核心思路是将大型语言模型(LLM)中通过强化学习获得的认知行为迁移到MLLM中,从而提升其视觉推理能力。作者认为,LLM的推理能力来源于其在大量文本数据上学习到的语言模式和逻辑推理能力,通过将这些能力迁移到MLLM,可以使其更好地理解和利用视觉信息。
技术框架:该方法采用两阶段训练范式。第一阶段是语言冷启动微调,使用大规模的文本数据对MLLM进行预训练,使其具备基本的语言理解和推理能力。第二阶段是多模态强化学习,使用视觉数据和奖励信号对MLLM进行微调,使其能够根据视觉信息进行决策和推理。整体框架基于Qwen2.5-VL-7B模型。
关键创新:该方法最重要的创新点在于将LLM的认知行为迁移到MLLM中,从而提升其视觉推理能力。通过语言冷启动微调和多模态强化学习,MLLM能够学习到视觉反思和策略性决策等高实用性的行为,从而在复杂场景下进行更有效的推理。此外,该研究揭示了行为迁移在冷启动阶段的早期出现,以及强化学习在区分和放大有效模式中的关键作用。
关键设计:在语言冷启动微调阶段,作者使用了大规模的文本数据,并采用了合适的损失函数来训练MLLM。在多模态强化学习阶段,作者设计了合适的奖励信号,以鼓励MLLM进行视觉反思和策略性决策。强化学习训练进行了近1000步,超过了以往的开源工作。具体参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
Open-Vision-Reasoner (OVR) 在多个视觉推理基准测试中取得了最先进的性能,具体包括:MATH500 上达到 95.3%,MathVision 上达到 51.8%,MathVerse 上达到 54.6%。这些结果表明,通过迁移语言认知行为,可以显著提升 MLLM 的视觉推理能力。
🎯 应用场景
该研究成果可应用于智能机器人、自动驾驶、医疗影像分析等领域。通过提升机器的视觉推理能力,可以使其更好地理解和利用视觉信息,从而实现更智能化的决策和控制。例如,在医疗影像分析中,可以帮助医生更准确地诊断疾病;在自动驾驶中,可以帮助车辆更好地理解周围环境,从而提高安全性。
📄 摘要(原文)
The remarkable reasoning capability of large language models (LLMs) stems from cognitive behaviors that emerge through reinforcement with verifiable rewards. This work investigates how to transfer this principle to Multimodal LLMs (MLLMs) to unlock advanced visual reasoning. We introduce a two-stage paradigm built on Qwen2.5-VL-7B: a massive linguistic cold-start fine-tuning, followed by multimodal reinforcement learning (RL) spanning nearly 1,000 steps, surpassing all previous open-source efforts in scale. This pioneering work reveals three fundamental insights: 1) Behavior transfer emerges surprisingly early in cold start due to linguistic mental imagery. 2) Cold start broadly memorizes visual behaviors, while RL critically discerns and scales up effective patterns. 3) Transfer strategically favors high-utility behaviors such as visual reflection. Our resulting model, Open-Vision-Reasoner (OVR), achieves state-of-the-art performance on a suite of reasoning benchmarks, including 95.3% on MATH500, 51.8% on MathVision and 54.6% on MathVerse. We release our model, data, and training dynamics to catalyze the development of more capable, behavior-aligned multimodal reasoners.