All in One: Visual-Description-Guided Unified Point Cloud Segmentation
作者: Zongyan Han, Mohamed El Amine Boudjoghra, Jiahua Dong, Jinhong Wang, Rao Muhammad Anwer
分类: cs.CV, cs.AI
发布日期: 2025-07-07 (更新: 2025-07-25)
备注: Accepted by ICCV2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出VDG-Uni3DSeg,利用视觉描述引导的统一框架实现点云分割。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 点云分割 多模态融合 视觉语言模型 大型语言模型 场景理解 语义分割 实例分割
📋 核心要点
- 现有3D点云分割方法难以有效利用语义和上下文信息,导致细粒度对象区分能力不足。
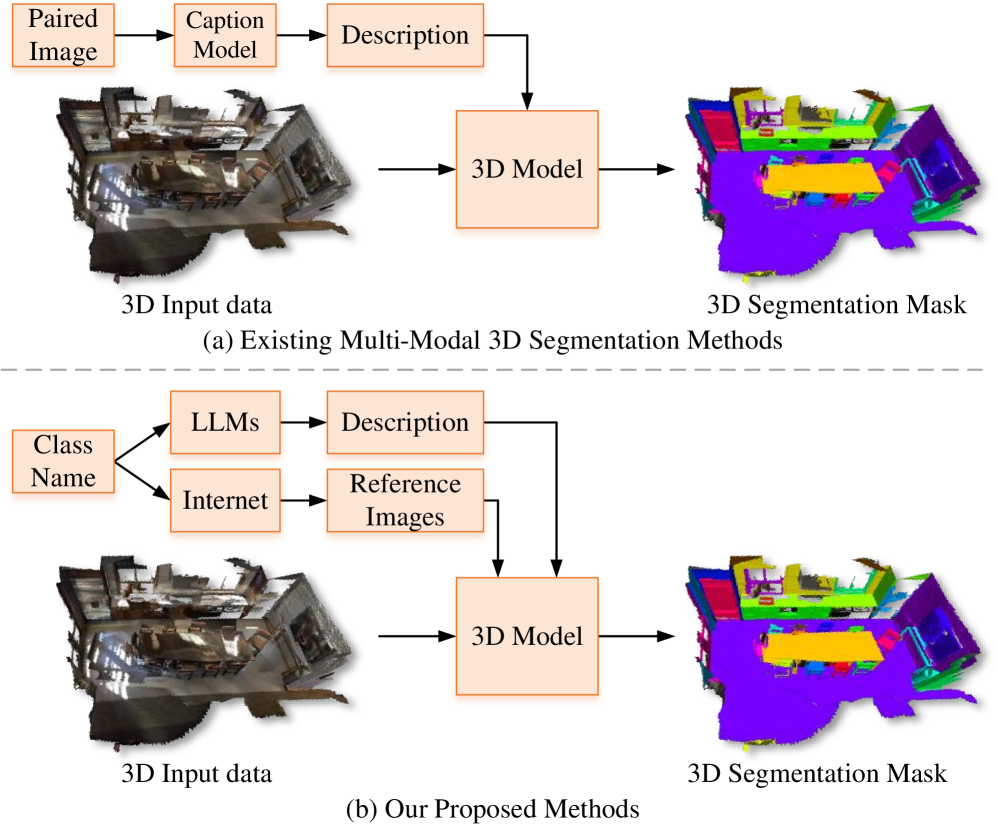
- VDG-Uni3DSeg利用LLM生成文本描述和互联网参考图像,融入多模态信息以提升分割性能。
- 通过语义-视觉对比损失和空间增强模块,VDG-Uni3DSeg在多个分割任务上取得SOTA结果。
📝 摘要(中文)
三维点云的统一分割对于场景理解至关重要,但受到其稀疏结构、有限标注以及复杂环境中区分细粒度对象类别的挑战的阻碍。现有方法通常难以捕获丰富的语义和上下文信息,因为它们缺乏足够的监督和多样化的多模态线索,导致类和实例的区分不佳。为了应对这些挑战,我们提出了一种新颖的框架VDG-Uni3DSeg,该框架集成了预训练的视觉-语言模型(例如CLIP)和大型语言模型(LLM)来增强3D分割。通过利用LLM生成的文本描述和来自互联网的参考图像,我们的方法结合了丰富的多模态线索,从而促进了细粒度的类和实例分离。我们进一步设计了一个语义-视觉对比损失来将点特征与多模态查询对齐,并设计了一个空间增强模块来有效地建模场景范围内的关系。VDG-Uni3DSeg在利用离线生成的多模态知识的封闭集范式中运行,在语义、实例和全景分割方面实现了最先进的结果,为3D理解提供了一种可扩展且实用的解决方案。
🔬 方法详解
问题定义:现有3D点云分割方法,尤其是在统一分割任务中,面临着数据稀疏性、标注不足以及难以区分细粒度对象类别的挑战。现有方法通常依赖有限的监督信息,缺乏对丰富语义和上下文信息的有效利用,导致类间和实例间的区分度不高。
核心思路:VDG-Uni3DSeg的核心思路是利用预训练的视觉-语言模型(如CLIP)和大型语言模型(LLM)的强大能力,为3D点云分割引入丰富的多模态信息。通过LLM生成场景的文本描述,并从互联网检索相关的参考图像,从而为点云分割提供额外的语义和视觉线索。这种方法旨在弥补传统方法在信息获取方面的不足,提升对细粒度对象类别的区分能力。
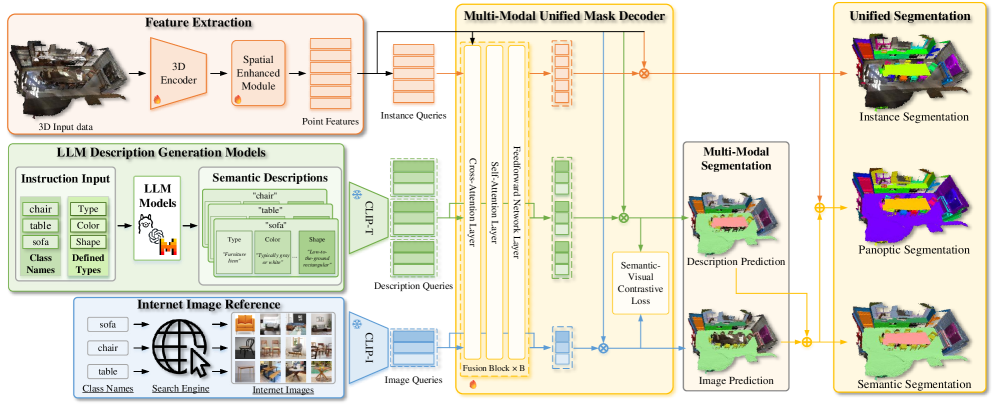
技术框架:VDG-Uni3DSeg的整体框架包括以下几个主要模块:1) 特征提取模块:用于提取点云的几何特征。2) 多模态信息融合模块:利用LLM生成文本描述,并检索相关图像,然后将这些多模态信息与点云特征进行融合。3) 语义-视觉对比学习模块:通过语义-视觉对比损失,将点云特征与多模态查询对齐,增强特征的语义表达能力。4) 空间增强模块:用于建模场景范围内的关系,提升分割的连贯性。5) 分割模块:基于融合后的特征进行语义、实例和全景分割。
关键创新:VDG-Uni3DSeg的关键创新在于其多模态信息的引入和融合方式。与传统方法仅依赖点云的几何特征或有限的标注信息不同,VDG-Uni3DSeg充分利用了预训练模型和互联网资源,为点云分割提供了更丰富的语义和视觉线索。此外,语义-视觉对比学习模块的设计也有效地提升了特征的表达能力。
关键设计:在语义-视觉对比学习中,设计了对比损失函数,用于拉近点云特征与对应文本描述和参考图像的特征表示。空间增强模块可能采用了图神经网络或Transformer等结构,用于建模点云中点与点之间的关系。具体的网络结构和参数设置需要在代码中进一步分析。
🖼️ 关键图片

📊 实验亮点
VDG-Uni3DSeg在多个公开数据集上取得了state-of-the-art的结果,证明了其有效性。具体性能数据需要在论文中查找。该方法在语义分割、实例分割和全景分割任务上均优于现有方法,尤其是在细粒度对象类别的区分方面,提升幅度显著。
🎯 应用场景
VDG-Uni3DSeg在机器人导航、自动驾驶、虚拟现实、增强现实等领域具有广泛的应用前景。它可以帮助机器人更好地理解周围环境,从而实现更智能的导航和交互。在自动驾驶领域,它可以提升车辆对场景的感知能力,从而提高驾驶安全性。在VR/AR领域,它可以用于构建更逼真的虚拟场景,提升用户体验。
📄 摘要(原文)
Unified segmentation of 3D point clouds is crucial for scene understanding, but is hindered by its sparse structure, limited annotations, and the challenge of distinguishing fine-grained object classes in complex environments. Existing methods often struggle to capture rich semantic and contextual information due to limited supervision and a lack of diverse multimodal cues, leading to suboptimal differentiation of classes and instances. To address these challenges, we propose VDG-Uni3DSeg, a novel framework that integrates pre-trained vision-language models (e.g., CLIP) and large language models (LLMs) to enhance 3D segmentation. By leveraging LLM-generated textual descriptions and reference images from the internet, our method incorporates rich multimodal cues, facilitating fine-grained class and instance separation. We further design a Semantic-Visual Contrastive Loss to align point features with multimodal queries and a Spatial Enhanced Module to model scene-wide relationships efficiently. Operating within a closed-set paradigm that utilizes multimodal knowledge generated offline, VDG-Uni3DSeg achieves state-of-the-art results in semantic, instance, and panoptic segmentation, offering a scalable and practical solution for 3D understanding. Our code is available at https://github.com/Hanzy1996/VDG-Uni3DSeg.