Differential Attention for Multimodal Crisis Event Analysis
作者: Nusrat Munia, Junfeng Zhu, Olfa Nasraoui, Abdullah-Al-Zubaer Imran
分类: cs.CV
发布日期: 2025-07-07
备注: Presented at CVPRw 2025, MMFM3
🔗 代码/项目: GITHUB
💡 一句话要点
提出差分注意力机制,增强多模态危机事件分析中的特征对齐与分类性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 危机事件分析 视觉语言模型 差分注意力 引导交叉注意力 特征对齐 灾难响应
📋 核心要点
- 现有危机事件分析方法难以有效提取社交媒体中大规模噪声数据中的关键信息,并整合异构数据。
- 论文提出结合引导交叉注意力和差分注意力机制,增强多模态特征对齐,强调关键信息并过滤无关内容。
- 实验表明,结合预训练视觉语言模型、增强文本描述和自适应融合策略,显著提升了危机事件分类精度。
📝 摘要(中文)
本文旨在解决危机事件中,从社交网络提取有价值信息并有效整合异构数据的难题。研究探索了视觉语言模型(VLMs)和高级融合策略,以提升危机数据在三个不同任务中的分类效果。通过引入LLaVA生成的文本来改善文本-图像对齐,并利用基于CLIP的视觉和文本嵌入,在无需任务特定微调的情况下超越了传统模型。此外,结合引导交叉注意力(Guided CA)和差分注意力机制,通过强调关键信息并过滤无关内容来增强特征对齐。实验结果表明,差分注意力机制提升了分类性能,而引导交叉注意力在对齐多模态特征方面仍然非常有效。在CrisisMMD基准数据集上的大量实验表明,预训练VLMs、丰富的文本描述和自适应融合策略的结合,在分类精度方面始终优于最先进的模型,从而为灾难响应提供了更可靠和可解释的模型。
🔬 方法详解
问题定义:论文旨在解决危机事件分析中,如何从社交媒体等渠道获取的大量多模态数据(图像和文本)中有效提取关键信息,并进行准确分类的问题。现有方法难以有效处理数据中的噪声和冗余信息,并且在多模态特征融合方面存在不足,导致分类性能受限。
核心思路:论文的核心思路是利用预训练的视觉语言模型(VLMs)提取图像和文本的深层特征,并通过差分注意力机制(Differential Attention)自适应地调整不同特征的权重,从而突出关键信息,抑制噪声和冗余信息。同时,结合引导交叉注意力(Guided Cross Attention)来增强多模态特征之间的对齐,从而提升分类性能。
技术框架:整体框架包括以下几个主要模块:1) 使用LLaVA生成更丰富的文本描述,增强文本-图像对齐;2) 利用CLIP提取图像和文本的嵌入特征;3) 使用引导交叉注意力(Guided CA)进行多模态特征融合;4) 使用差分注意力机制(Differential Attention)自适应地调整特征权重;5) 使用分类器进行最终的危机事件分类。
关键创新:论文的关键创新在于提出了差分注意力机制(Differential Attention),该机制能够根据输入数据的特点,自适应地调整不同特征的权重,从而突出关键信息,抑制噪声和冗余信息。与传统的注意力机制相比,差分注意力机制更加灵活和有效,能够更好地适应危机事件分析中复杂多变的数据。
关键设计:差分注意力机制的具体实现方式未知,论文中可能没有详细阐述其具体公式和参数设置。引导交叉注意力(Guided CA)的具体实现细节也未知。损失函数和网络结构等技术细节在论文中没有明确说明。
🖼️ 关键图片

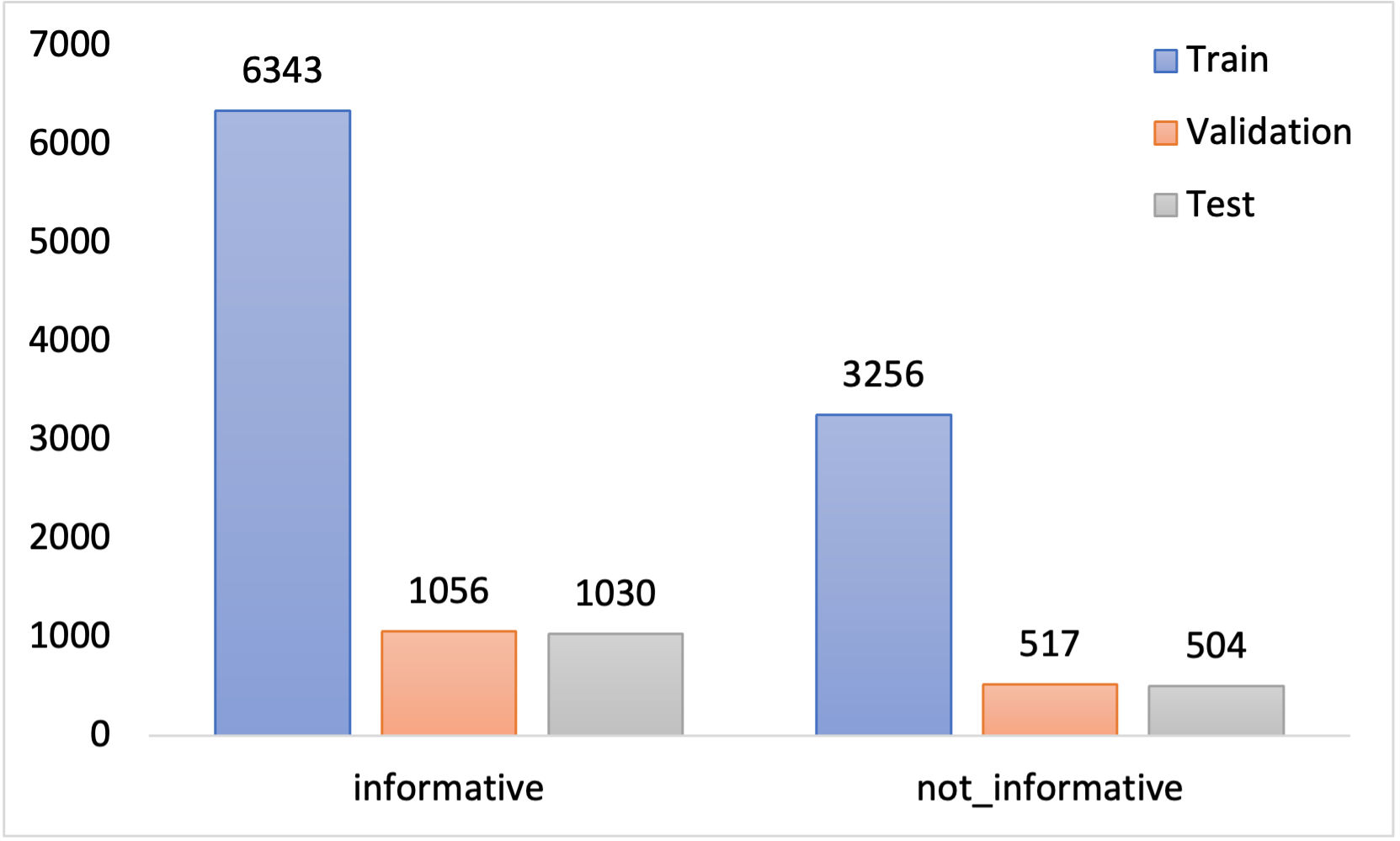
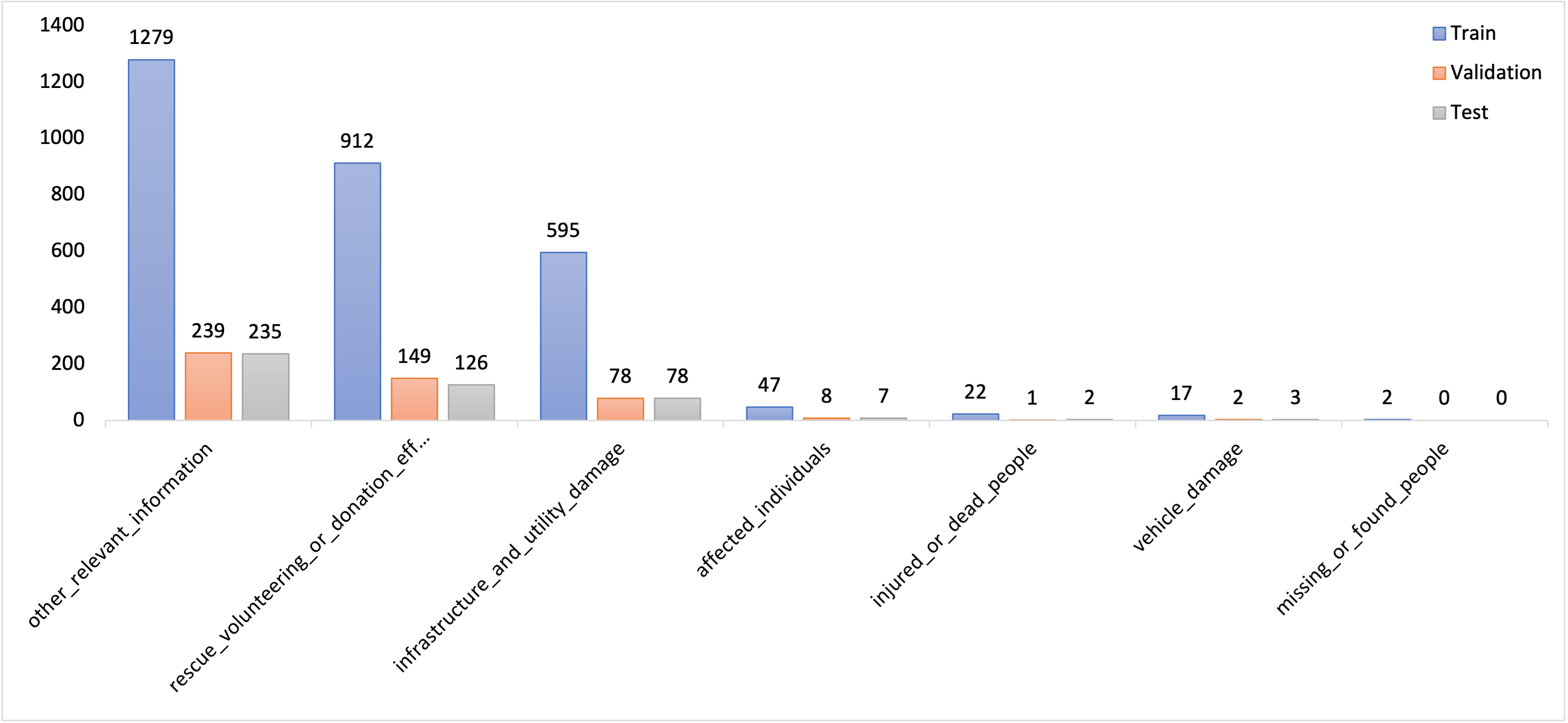
📊 实验亮点
实验结果表明,结合预训练视觉语言模型、增强文本描述和自适应融合策略,在CrisisMMD基准数据集上,该方法在危机事件分类精度方面始终优于最先进的模型。具体性能提升数据未知,论文中没有给出明确的数值对比。
🎯 应用场景
该研究成果可应用于灾难响应、舆情监控、公共安全等领域。通过自动分析社交媒体等多渠道的多模态数据,可以快速识别和评估危机事件的严重程度,为救援人员提供决策支持,提高救援效率,减少人员伤亡和财产损失。未来,该技术还可以扩展到其他领域,如智能交通、智慧城市等。
📄 摘要(原文)
Social networks can be a valuable source of information during crisis events. In particular, users can post a stream of multimodal data that can be critical for real-time humanitarian response. However, effectively extracting meaningful information from this large and noisy data stream and effectively integrating heterogeneous data remains a formidable challenge. In this work, we explore vision language models (VLMs) and advanced fusion strategies to enhance the classification of crisis data in three different tasks. We incorporate LLaVA-generated text to improve text-image alignment. Additionally, we leverage Contrastive Language-Image Pretraining (CLIP)-based vision and text embeddings, which, without task-specific fine-tuning, outperform traditional models. To further refine multimodal fusion, we employ Guided Cross Attention (Guided CA) and combine it with the Differential Attention mechanism to enhance feature alignment by emphasizing critical information while filtering out irrelevant content. Our results show that while Differential Attention improves classification performance, Guided CA remains highly effective in aligning multimodal features. Extensive experiments on the CrisisMMD benchmark data set demonstrate that the combination of pretrained VLMs, enriched textual descriptions, and adaptive fusion strategies consistently outperforms state-of-the-art models in classification accuracy, contributing to more reliable and interpretable models for three different tasks that are crucial for disaster response. Our code is available at https://github.com/Munia03/Multimodal_Crisis_Event.