HumanVideo-MME: Benchmarking MLLMs for Human-Centric Video Understanding
作者: Yuxuan Cai, Jiangning Zhang, Zhenye Gan, Qingdong He, Xiaobin Hu, Junwei Zhu, Yabiao Wang, Chengjie Wang, Zhucun Xue, Chaoyou Fu, Xinwei He, Xiang Bai
分类: cs.CV, cs.AI
发布日期: 2025-07-07 (更新: 2025-09-30)
备注: Under review
💡 一句话要点
提出HV-MMBench,用于全面评估MLLM在以人为中心的视频理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 视频理解 大型语言模型 基准测试 以人为中心 认知推理 时间推理
📋 核心要点
- 现有以人为中心的视频理解基准侧重于视频生成和动作识别,忽略了感知和认知能力评估。
- HV-MMBench通过13个任务、多样数据类型和多领域视频,全面评估MLLM在相关场景下的能力。
- HV-MMBench覆盖短时和长时视频,支持对模型时间推理能力进行系统分析。
📝 摘要(中文)
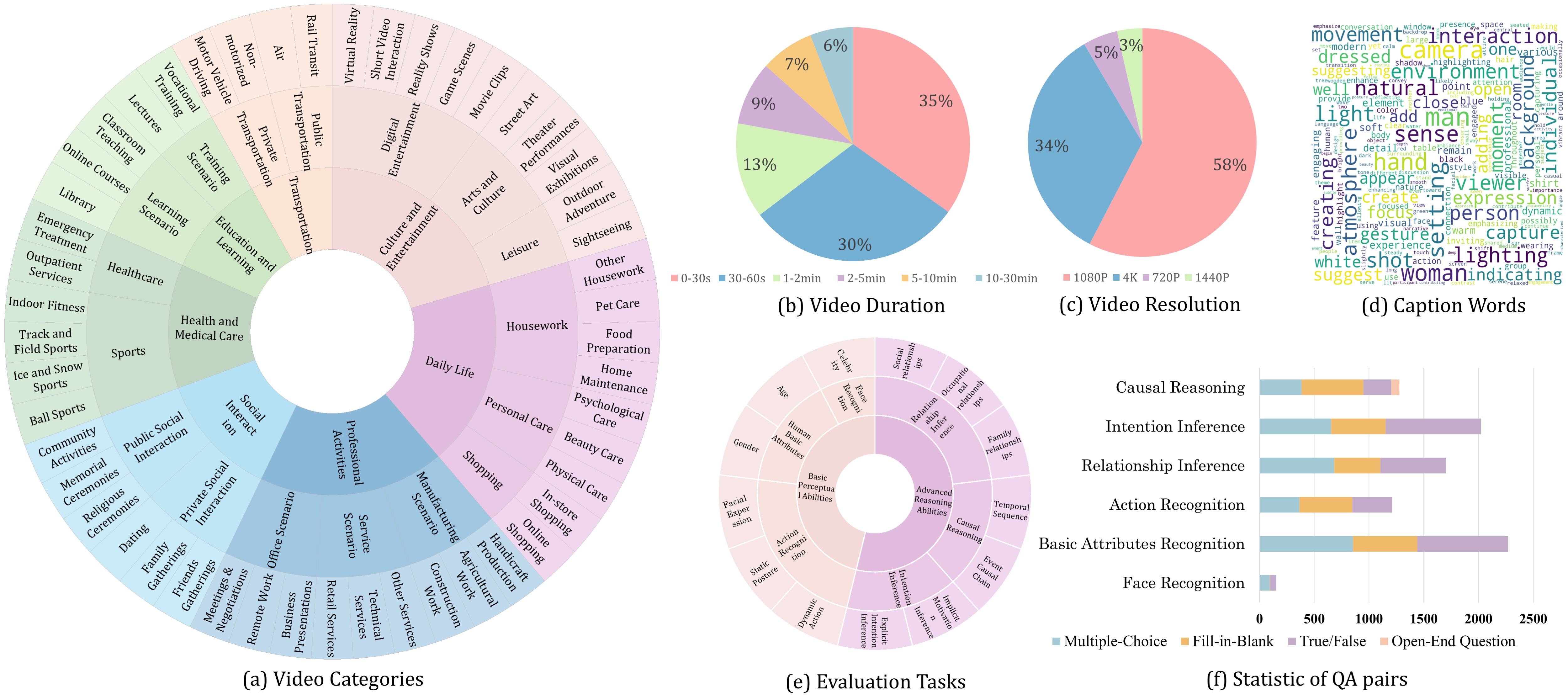
多模态大型语言模型(MLLM)在涉及图像和视频的视觉理解任务中表现出显著的进步。然而,它们理解以人为中心的视频数据的能力仍未得到充分探索,这主要是由于缺乏全面和高质量的评估基准。现有的以人为中心的基准主要强调视频生成质量和动作识别,而忽略了以人为中心场景中所需的基本感知和认知能力。此外,它们通常受到单一问题模式和过于简单的评估指标的限制。为了解决上述局限性,我们提出了一个现代化的HV-MMBench,这是一个经过严格策划的基准,旨在为MLLM在以人为中心的视频理解中提供更全面的评估。与现有的以人为中心的视频基准相比,我们的工作提供了以下关键特性:(1) 多样化的评估维度:HV-MMBench包含13个任务,从基本属性感知(例如,年龄估计、情感识别)到高级认知推理(例如,社会关系预测、意图预测),从而能够全面评估模型能力;(2) 多样的数据类型:该基准包括多项选择、填空、真/假和开放式问题格式,结合多样化的评估指标,以更准确和稳健地反映模型性能;(3) 多领域视频覆盖:该基准跨越50个不同的视觉场景,从而能够全面评估细粒度的场景变化;(4) 时间覆盖:该基准涵盖从短时(10秒)到长时(最长30分钟)的视频,支持对模型在不同上下文长度下的时间推理能力进行系统分析。
🔬 方法详解
问题定义:现有以人为中心的视频理解基准测试主要关注视频生成质量和动作识别,缺乏对模型在感知(如年龄估计、情感识别)和认知(如社会关系预测、意图预测)等更高级能力的全面评估。此外,现有基准通常采用单一问题模式和过于简化的评估指标,难以准确反映模型的真实性能。
核心思路:HV-MMBench的核心思路是构建一个更全面、多样化和具有挑战性的基准测试,以更准确地评估MLLM在以人为中心的视频理解方面的能力。通过引入多种任务类型、数据格式和评估指标,以及覆盖更广泛的视频场景和时间跨度,HV-MMBench旨在推动该领域的研究进展。
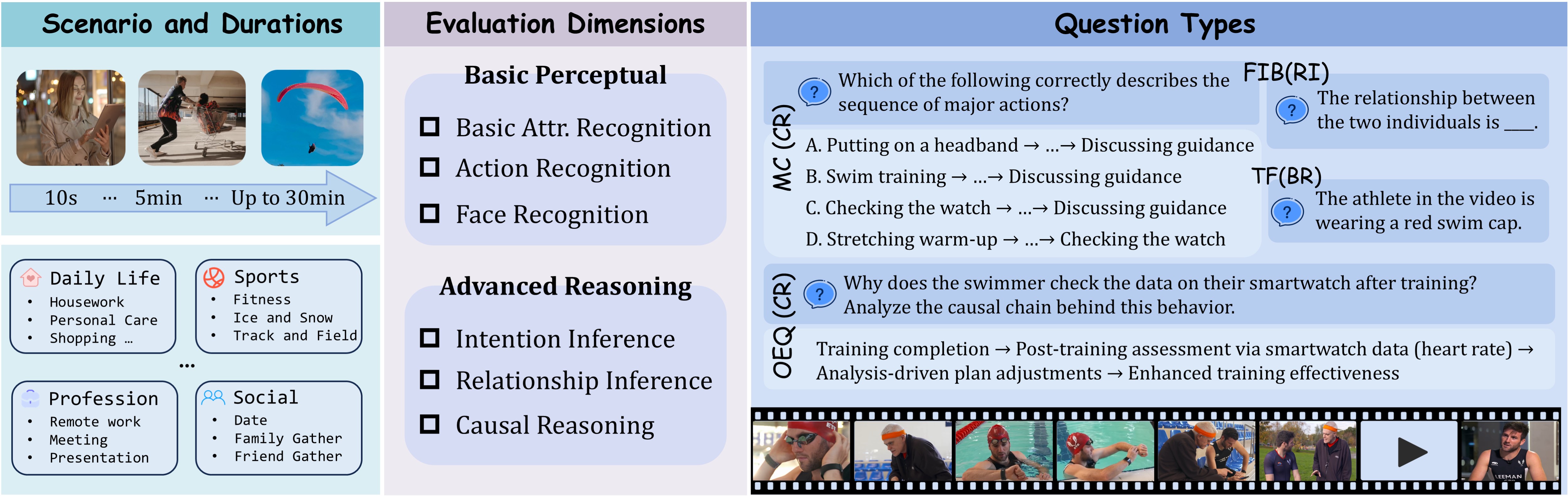
技术框架:HV-MMBench包含以下几个关键组成部分: 1. 多样化的评估维度:涵盖13个任务,从基本属性感知到高级认知推理。 2. 多样的数据类型:包括多项选择、填空、真/假和开放式问题。 3. 多领域视频覆盖:包含50个不同的视觉场景。 4. 时间覆盖:涵盖短时(10秒)到长时(30分钟)视频。
整体流程是,给定一个视频片段,MLLM需要根据HV-MMBench中定义的任务类型和问题进行回答,然后根据相应的评估指标进行评分。
关键创新:HV-MMBench的关键创新在于其全面性和多样性。它不仅涵盖了更广泛的评估维度,还引入了更多样化的数据类型和视频场景,从而能够更准确地评估MLLM在以人为中心的视频理解方面的能力。此外,HV-MMBench还考虑了视频的时间跨度,支持对模型的时间推理能力进行评估。
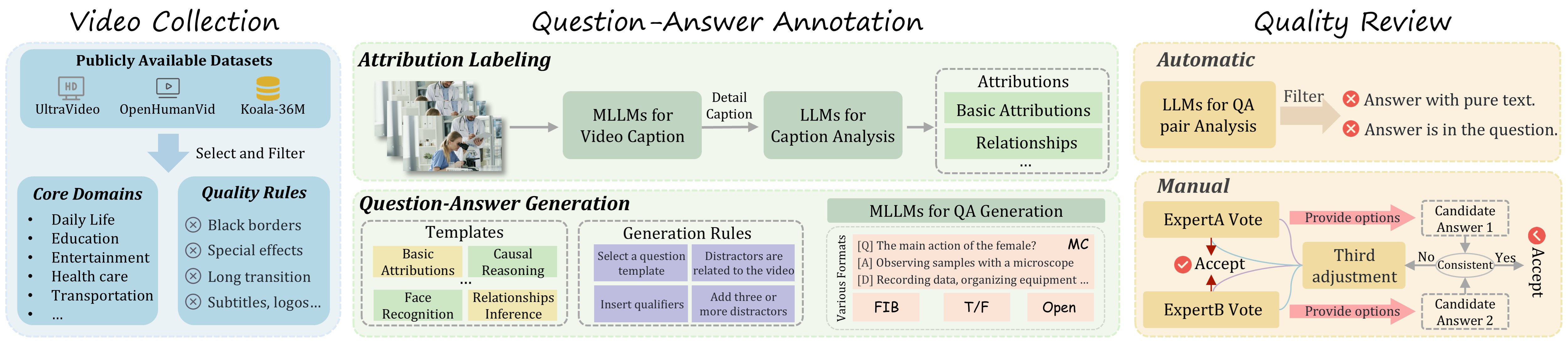
关键设计:HV-MMBench的关键设计包括: 1. 任务选择:精心挑选了13个与以人为中心的视频理解相关的任务,涵盖了感知、认知和社会交互等多个方面。 2. 数据收集和标注:收集了大量高质量的视频数据,并进行了细致的人工标注,以确保基准测试的准确性和可靠性。 3. 评估指标:采用了多种评估指标,包括准确率、F1值、BLEU等,以全面评估模型的性能。
🖼️ 关键图片
📊 实验亮点
HV-MMBench是一个新提出的基准,论文主要贡献在于数据集的构建和任务的定义,并没有给出具体的实验结果。因此,实验亮点主要体现在数据集的多样性和任务的全面性上,为后续研究提供了一个有力的评估工具。
🎯 应用场景
HV-MMBench可用于评估和比较不同的MLLM在以人为中心的视频理解方面的能力,从而推动该领域的研究进展。该基准测试还可以用于开发更智能的视频分析系统,例如智能监控、人机交互和社交媒体分析等。通过提高MLLM对人类行为和意图的理解能力,可以为这些应用带来更准确、更可靠的结果。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have demonstrated significant advances in visual understanding tasks involving both images and videos. However, their capacity to comprehend human-centric video data remains underexplored, primarily due to the absence of comprehensive and high-quality evaluation benchmarks. Existing human-centric benchmarks predominantly emphasize video generation quality and action recognition, while overlooking essential perceptual and cognitive abilities required in human-centered scenarios. Furthermore, they are often limited by single-question paradigms and overly simplistic evaluation metrics. To address above limitations, we propose a modern HV-MMBench, a rigorously curated benchmark designed to provide a more holistic evaluation of MLLMs in human-centric video understanding. Compared to existing human-centric video benchmarks, our work offers the following key features: (1) Diverse evaluation dimensions: HV-MMBench encompasses 13 tasks, ranging from basic attribute perception (e.g., age estimation, emotion recognition) to advanced cognitive reasoning (e.g., social relationship prediction, intention prediction), enabling comprehensive assessment of model capabilities; (2) Varied data types: The benchmark includes multiple-choice, fill-in-blank, true/false, and open-ended question formats, combined with diverse evaluation metrics, to more accurately and robustly reflect model performance; (3) Multi-domain video coverage: The benchmark spans 50 distinct visual scenarios, enabling comprehensive evaluation across fine-grained scene variations; (4) Temporal coverage: The benchmark covers videos from short-term (10 seconds) to long-term (up to 30min) durations, supporting systematic analysis of models temporal reasoning abilities across diverse contextual lengths.