Transcribing Spanish Texts from the Past: Experiments with Transkribus, Tesseract and Granite
作者: Yanco Amor Torterolo-Orta, Jaione Macicior-Mitxelena, Marina Miguez-Lamanuzzi, Ana García-Serrano
分类: cs.CV, cs.CL
发布日期: 2025-07-07
备注: This paper was written as part of a shared task organized within the 2025 edition of the Iberian Languages Evaluation Forum (IberLEF 2025), held at SEPLN 2025 in Zaragoza. This paper describes the joint participation of two teams in said competition, GRESEL1 and GRESEL2, each with an individual paper that will be published in CEUR
💡 一句话要点
GRESEL团队探索多种OCR方法转录西班牙古籍文本,为PastReader任务提供对比。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: OCR 古籍文本转录 西班牙语 多模态模型 Tesseract
📋 核心要点
- 古籍文本转录面临字体陈旧、纸张退化等挑战,传统OCR方法效果有限。
- 探索Web OCR服务、传统OCR引擎和紧凑多模态模型,对比不同方案的性能。
- 实验在消费级硬件上进行,结果表明现有方法有提升空间,未来将继续探索。
📝 摘要(中文)
本文介绍了GRESEL团队在IberLEF 2025共享任务PastReader:转录古籍文本中进行的实验和获得的结果。为了参与该任务并实现不同方法之间的比较,我们进行了三种类型的实验,包括使用基于Web的OCR服务、传统的OCR引擎和一个紧凑的多模态模型。所有实验均在消费级硬件上运行,尽管缺乏高性能计算能力,但提供了足够的存储和稳定性。结果虽然令人满意,但仍有进一步改进的空间。未来的工作将侧重于探索使用西班牙国家图书馆(BNE)提供的西班牙语数据集的新技术和想法。
🔬 方法详解
问题定义:论文旨在解决西班牙古籍文本的自动转录问题。现有OCR方法在处理此类文本时,由于字体古老、纸张质量差、噪声干扰等因素,识别精度较低,难以满足实际应用需求。因此,需要探索更有效的OCR方法,提高古籍文本的转录质量。
核心思路:论文的核心思路是对比多种OCR方案在古籍文本转录任务上的性能,包括基于Web的OCR服务、传统OCR引擎和紧凑的多模态模型。通过实验分析不同方案的优缺点,为后续研究提供参考。
技术框架:论文采用了三种不同的OCR方案进行实验: 1. Web OCR服务:使用在线OCR服务,无需本地部署,方便快捷。 2. 传统OCR引擎:使用Tesseract等传统OCR引擎,进行本地部署和训练。 3. 紧凑多模态模型:使用结合图像和文本信息的多模态模型,提高识别精度。 实验流程包括数据预处理、模型训练/调用、结果评估等步骤。
关键创新:论文的主要创新在于对比了多种OCR方案在西班牙古籍文本转录任务上的性能,并分析了不同方案的优缺点。这为后续研究提供了有价值的参考,有助于选择更合适的OCR方案。此外,论文还探索了紧凑多模态模型在古籍文本转录中的应用,为提高识别精度提供了新的思路。
关键设计:论文中,传统OCR引擎使用了Tesseract,具体配置参数未知。紧凑多模态模型的具体结构和参数设置未知。损失函数和训练策略也未详细说明。Web OCR服务使用的具体服务商和API也未知。
🖼️ 关键图片

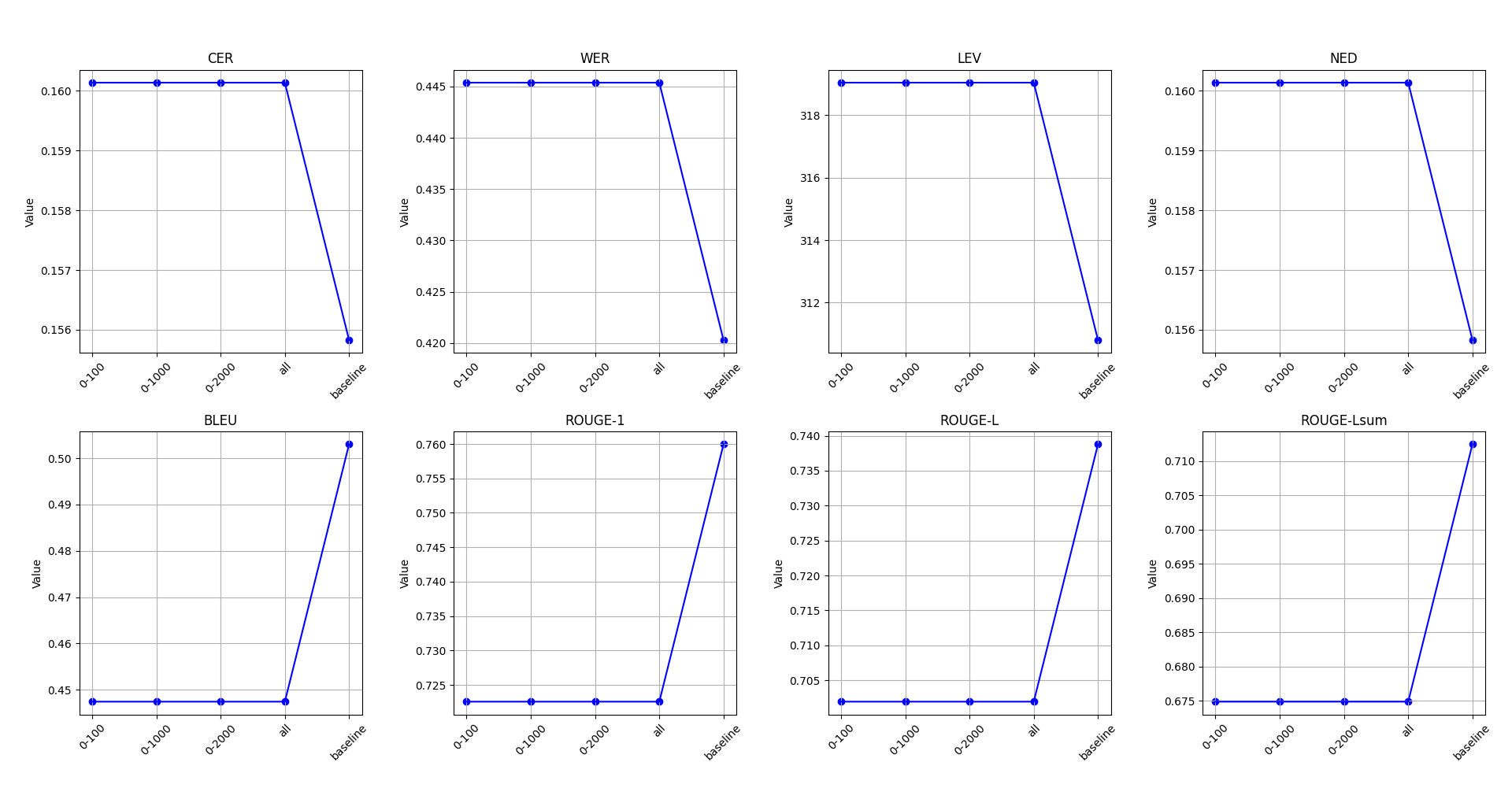

📊 实验亮点
论文对比了三种OCR方案在西班牙古籍文本转录任务上的性能,结果表明现有方法仍有提升空间。具体的性能数据和对比基线未在摘要中详细说明。未来的工作将侧重于探索新的技术和想法,以提高古籍文本的转录质量。
🎯 应用场景
该研究成果可应用于古籍数字化、历史文献研究、文化遗产保护等领域。通过提高古籍文本的转录效率和准确性,可以更好地保存和利用珍贵的历史文化资源。未来,该技术有望应用于其他语言的古籍文本转录,促进文化交流和学术研究。
📄 摘要(原文)
This article presents the experiments and results obtained by the GRESEL team in the IberLEF 2025 shared task PastReader: Transcribing Texts from the Past. Three types of experiments were conducted with the dual aim of participating in the task and enabling comparisons across different approaches. These included the use of a web-based OCR service, a traditional OCR engine, and a compact multimodal model. All experiments were run on consumer-grade hardware, which, despite lacking high-performance computing capacity, provided sufficient storage and stability. The results, while satisfactory, leave room for further improvement. Future work will focus on exploring new techniques and ideas using the Spanish-language dataset provided by the shared task, in collaboration with Biblioteca Nacional de España (BNE).