DreamVLA: A Vision-Language-Action Model Dreamed with Comprehensive World Knowledge
作者: Wenyao Zhang, Hongsi Liu, Zekun Qi, Yunnan Wang, Xinqiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, Fan Lu, He Wang, Zhizheng Zhang, Li Yi, Wenjun Zeng, Xin Jin
分类: cs.CV, cs.RO
发布日期: 2025-07-06 (更新: 2025-08-26)
💡 一句话要点
DreamVLA:融合全面世界知识的视觉-语言-动作模型,提升机器人操作的泛化性和推理能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人操作 世界知识预测 动态区域引导 块状结构化注意力 扩散Transformer 逆动力学建模
📋 核心要点
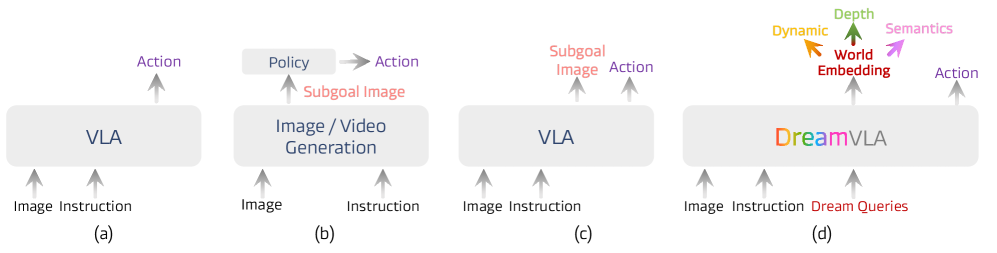
- 现有VLA模型在基于图像的预测方面存在局限性,冗余信息过多且缺乏动态、空间和语义等全面的世界知识。
- DreamVLA通过动态区域引导的世界知识预测,结合空间和语义信息,为动作规划提供紧凑且全面的表示,模拟人类的抽象多模态推理。
- DreamVLA在真实机器人任务中达到76.7%的成功率,并在CALVIN ABC-D基准测试中取得4.44的平均长度,验证了其有效性。
📝 摘要(中文)
本文提出了一种新的视觉-语言-动作(VLA)框架DreamVLA,旨在通过整合全面的世界知识预测来实现逆动力学建模,从而为机器人操作任务建立一个感知-预测-动作循环。DreamVLA引入了动态区域引导的世界知识预测,并结合了空间和语义线索,为动作规划提供紧凑而全面的表示。为了减轻训练过程中动态、空间和语义信息之间的干扰,采用了块状结构化注意力机制,屏蔽了它们之间的相互注意力,防止信息泄露并保持每个表示的清晰和解耦。此外,为了对未来动作的条件分布进行建模,采用了一种基于扩散的Transformer,将动作表示与共享的潜在特征解耦。在真实世界和模拟环境中的大量实验表明,DreamVLA在真实机器人任务上的成功率达到76.7%,在CALVIN ABC-D基准测试上的平均长度为4.44。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在机器人操作任务中,依赖于直接从图像进行预测,这导致了信息冗余,并且缺乏对动态、空间和语义等关键世界知识的理解。这种局限性阻碍了模型在复杂环境中的泛化能力和推理能力。
核心思路:DreamVLA的核心思路是通过预测全面的世界知识来弥补现有VLA模型的不足。它不是直接从图像预测动作,而是首先预测环境的动态变化、空间布局和语义信息,然后基于这些预测结果进行动作规划。这种方法更符合人类的认知方式,即先形成抽象的多模态推理链,然后再采取行动。
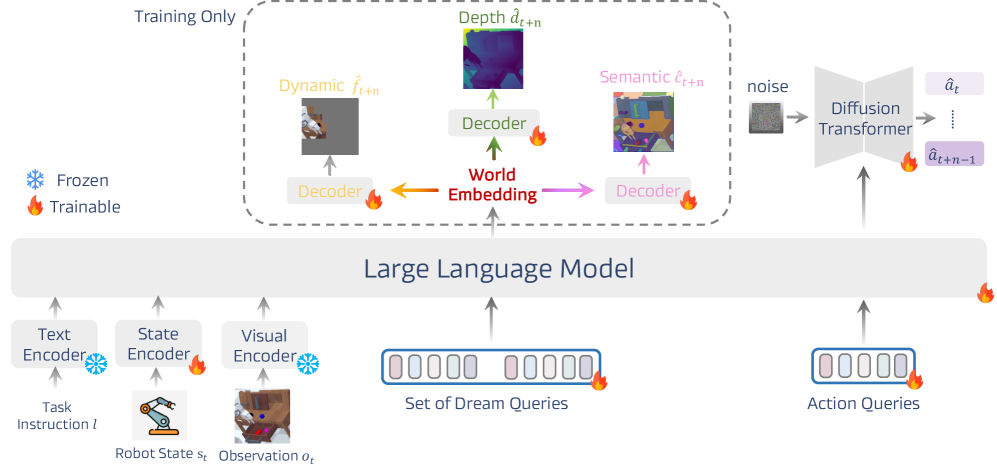
技术框架:DreamVLA的整体框架包含以下几个主要模块:1) 动态区域引导的世界知识预测模块:该模块负责预测环境的动态变化、空间布局和语义信息。2) 块状结构化注意力机制:用于减轻训练过程中动态、空间和语义信息之间的干扰,防止信息泄露。3) 基于扩散的Transformer:用于对未来动作的条件分布进行建模,将动作表示与共享的潜在特征解耦。整个流程形成一个感知-预测-动作的闭环。
关键创新:DreamVLA的关键创新在于其对世界知识的全面预测和利用。与现有方法直接从图像预测动作不同,DreamVLA首先预测环境的动态变化、空间布局和语义信息,然后基于这些预测结果进行动作规划。这种方法能够更好地捕捉环境的本质特征,提高模型的泛化能力和推理能力。
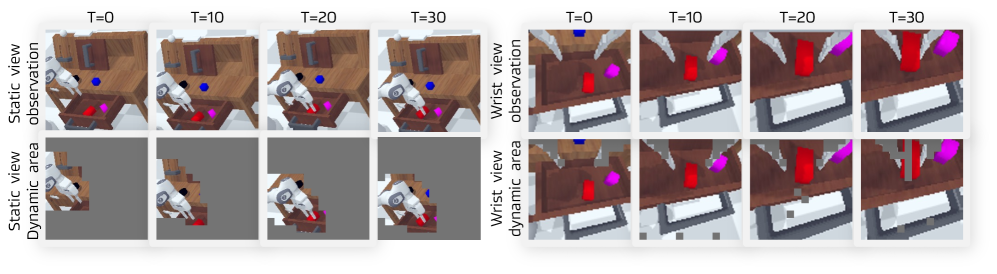
关键设计:在动态区域引导的世界知识预测模块中,使用了动态区域引导机制来关注图像中发生变化的区域,从而提高预测的准确性。在块状结构化注意力机制中,通过mask掉不同类型信息之间的相互注意力,防止信息泄露,保持每个表示的清晰和解耦。在基于扩散的Transformer中,使用了扩散模型来生成动作序列,从而更好地建模动作的条件分布。
🖼️ 关键图片
📊 实验亮点
DreamVLA在真实机器人任务中取得了显著的性能提升,成功率达到76.7%,显著优于现有方法。在CALVIN ABC-D基准测试中,DreamVLA的平均长度为4.44,表明其在长期规划方面具有优势。这些实验结果充分证明了DreamVLA在机器人操作任务中的有效性和优越性。
🎯 应用场景
DreamVLA具有广泛的应用前景,包括但不限于:智能制造、家庭服务机器人、自动驾驶、医疗机器人等领域。通过提升机器人操作的泛化性和推理能力,可以使机器人在更复杂、更动态的环境中执行任务,从而提高生产效率、改善生活质量,并为人类提供更安全、更便捷的服务。
📄 摘要(原文)
Recent advances in vision-language-action (VLA) models have shown promise in integrating image generation with action prediction to improve generalization and reasoning in robot manipulation. However, existing methods are limited to challenging image-based forecasting, which suffers from redundant information and lacks comprehensive and critical world knowledge, including dynamic, spatial and semantic information. To address these limitations, we propose DreamVLA, a novel VLA framework that integrates comprehensive world knowledge forecasting to enable inverse dynamics modeling, thereby establishing a perception-prediction-action loop for manipulation tasks. Specifically, DreamVLA introduces a dynamic-region-guided world knowledge prediction, integrated with the spatial and semantic cues, which provide compact yet comprehensive representations for action planning. This design aligns with how humans interact with the world by first forming abstract multimodal reasoning chains before acting. To mitigate interference among the dynamic, spatial and semantic information during training, we adopt a block-wise structured attention mechanism that masks their mutual attention, preventing information leakage and keeping each representation clean and disentangled. Moreover, to model the conditional distribution over future actions, we employ a diffusion-based transformer that disentangles action representations from shared latent features. Extensive experiments on both real-world and simulation environments demonstrate that DreamVLA achieves 76.7% success rate on real robot tasks and 4.44 average length on the CALVIN ABC-D benchmarks.