ZERO: Industry-ready Vision Foundation Model with Multi-modal Prompts
作者: Sangbum Choi, Kyeongryeol Go, Taewoong Jang
分类: cs.CV, cs.AI
发布日期: 2025-07-06 (更新: 2025-11-07)
备注: 9 pages, 2 figures
💡 一句话要点
ZERO:面向工业界的多模态提示视觉基础模型,实现零样本泛化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉基础模型 多模态提示 零样本学习 工业应用 领域特定 目标检测 图像识别
📋 核心要点
- 现有视觉基础模型缺乏领域特定数据,难以在工业界零样本部署。
- ZERO利用多模态提示(文本和视觉)在工业数据集上训练,无需重新训练即可泛化。
- ZERO在多个工业数据集上超越现有模型,并在CVPR相关挑战赛中取得优异成绩。
📝 摘要(中文)
基础模型彻底改变了人工智能领域,但由于缺乏高质量、领域特定的数据集,它们在现实工业环境中的零样本部署中面临挑战。为了弥合这一差距,Superb AI推出了ZERO,一个面向工业界的视觉基础模型,它利用多模态提示(文本和视觉)来实现泛化,而无需重新训练。ZERO在从专有的十亿级工业数据集中提取的紧凑但具有代表性的90万个带注释样本上进行训练,在LVIS-Val等学术基准上表现出竞争性的性能,并在37个不同的工业数据集上显著优于现有模型。此外,ZERO在CVPR 2025对象实例检测挑战赛中获得第二名,在基础小样本对象检测挑战赛中获得第四名,突显了其在最小适应和有限数据下的实际可部署性和泛化能力。据我们所知,ZERO是第一个专门为领域特定的零样本工业应用构建的视觉基础模型。
🔬 方法详解
问题定义:论文旨在解决视觉基础模型在工业界零样本部署的难题。现有方法依赖于通用数据集,缺乏领域特定知识,导致在工业场景下性能不佳。此外,重新训练成本高昂,不具备实际应用性。
核心思路:论文的核心思路是利用多模态提示(文本和视觉)来增强模型的泛化能力。通过在包含丰富领域知识的工业数据集上进行训练,模型能够学习到更具判别性的特征表示,从而在零样本场景下实现更好的性能。多模态提示允许模型利用文本描述和视觉信息,更准确地理解图像内容。
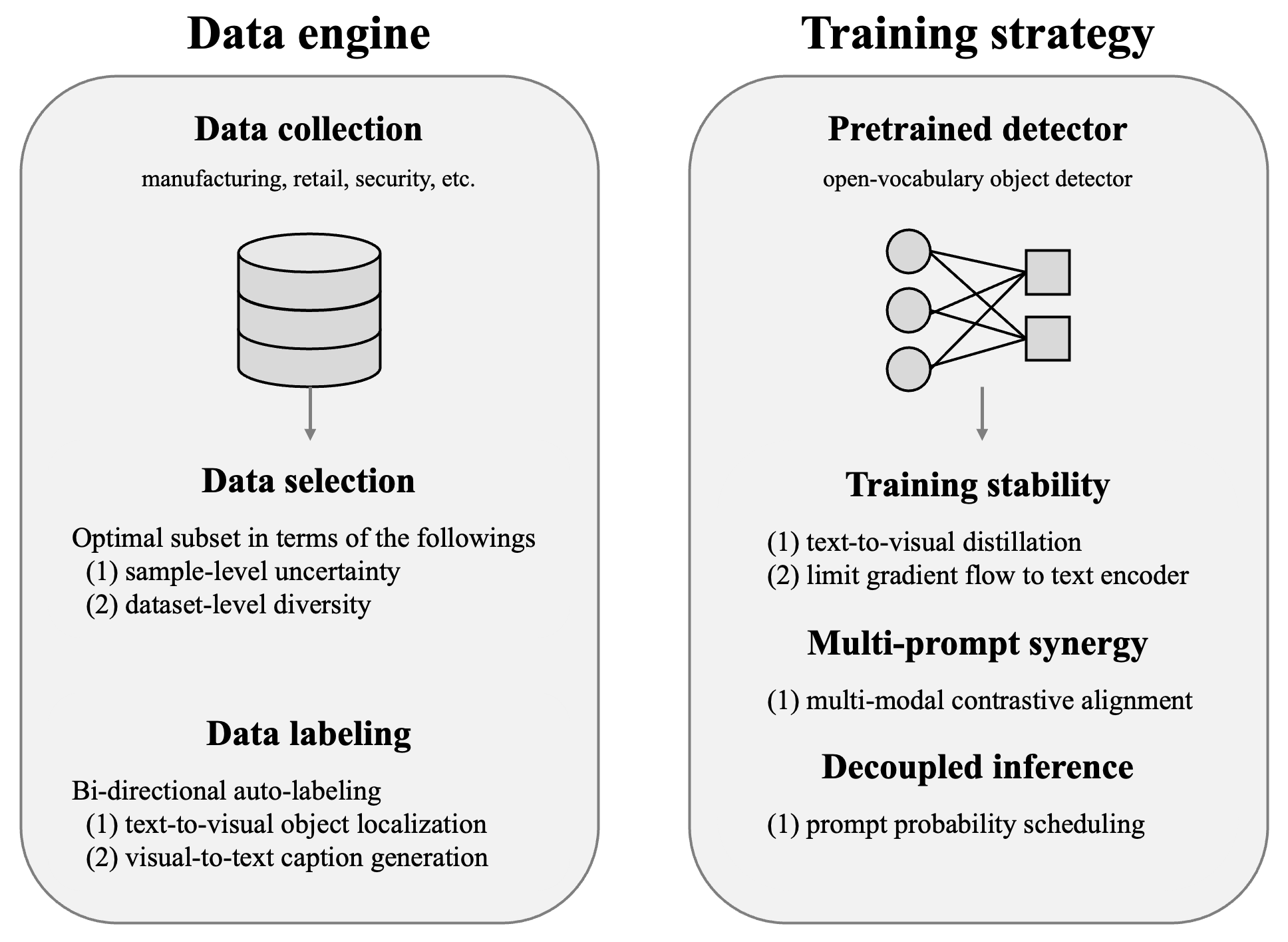
技术框架:ZERO的整体框架包含数据收集与标注、模型训练和评估三个主要阶段。首先,从十亿级工业数据集中筛选出具有代表性的样本,并进行高质量的标注。然后,利用这些数据训练视觉基础模型,并结合多模态提示策略。最后,在多个工业数据集和学术基准上评估模型的性能。
关键创新:ZERO的关键创新在于其面向工业界的领域特定设计和多模态提示策略。与以往的通用视觉基础模型不同,ZERO专门针对工业应用进行优化,能够更好地适应工业场景的复杂性和多样性。多模态提示策略允许模型利用文本和视觉信息,提高模型的理解能力和泛化能力。
关键设计:ZERO的关键设计包括:1) 使用紧凑但具有代表性的90万个带注释样本进行训练,降低了训练成本;2) 采用多模态提示策略,允许模型利用文本和视觉信息;3) 在多个工业数据集和学术基准上进行评估,验证了模型的泛化能力和鲁棒性;4) 具体的网络结构和损失函数等细节未知。
🖼️ 关键图片


📊 实验亮点
ZERO在37个不同的工业数据集上显著优于现有模型,并在CVPR 2025对象实例检测挑战赛中获得第二名,在基础小样本对象检测挑战赛中获得第四名。这些结果表明,ZERO具有很强的泛化能力和鲁棒性,能够在实际工业场景中取得良好的性能。具体提升幅度未知。
🎯 应用场景
ZERO在工业检测、智能制造、自动化等领域具有广泛的应用前景。例如,可用于产品缺陷检测、零件识别、机器人导航等任务。该研究的实际价值在于降低了模型部署的成本和难度,提高了工业生产的效率和智能化水平。未来,ZERO有望成为工业人工智能领域的重要基础设施。
📄 摘要(原文)
Foundation models have revolutionized AI, yet they struggle with zero-shot deployment in real-world industrial settings due to a lack of high-quality, domain-specific datasets. To bridge this gap, Superb AI introduces ZERO, an industry-ready vision foundation model that leverages multi-modal prompting (textual and visual) for generalization without retraining. Trained on a compact yet representative 0.9 million annotated samples from a proprietary billion-scale industrial dataset, ZERO demonstrates competitive performance on academic benchmarks like LVIS-Val and significantly outperforms existing models across 37 diverse industrial datasets. Furthermore, ZERO achieved 2nd place in the CVPR 2025 Object Instance Detection Challenge and 4th place in the Foundational Few-shot Object Detection Challenge, highlighting its practical deployability and generalizability with minimal adaptation and limited data. To the best of our knowledge, ZERO is the first vision foundation model explicitly built for domain-specific, zero-shot industrial applications.