Driver-Net: Multi-Camera Fusion for Assessing Driver Take-Over Readiness in Automated Vehicles
作者: Mahdi Rezaei, Mohsen Azarmi
分类: cs.CV, cs.AI, cs.ET, cs.LG, cs.RO
发布日期: 2025-07-05 (更新: 2025-09-08)
期刊: 2025 IEEE Intelligent Vehicles Symposium (IV)
DOI: 10.1109/IV64158.2025.11097677
💡 一句话要点
Driver-Net:融合多相机信息评估自动驾驶中驾驶员接管准备度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 驾驶员监控 自动驾驶 多相机融合 深度学习 接管准备度 时空特征 跨模态融合
📋 核心要点
- 现有驾驶员监控系统主要依赖头部姿态或眼动追踪,忽略了手部和身体姿势等重要信息,导致接管准备度评估不准确。
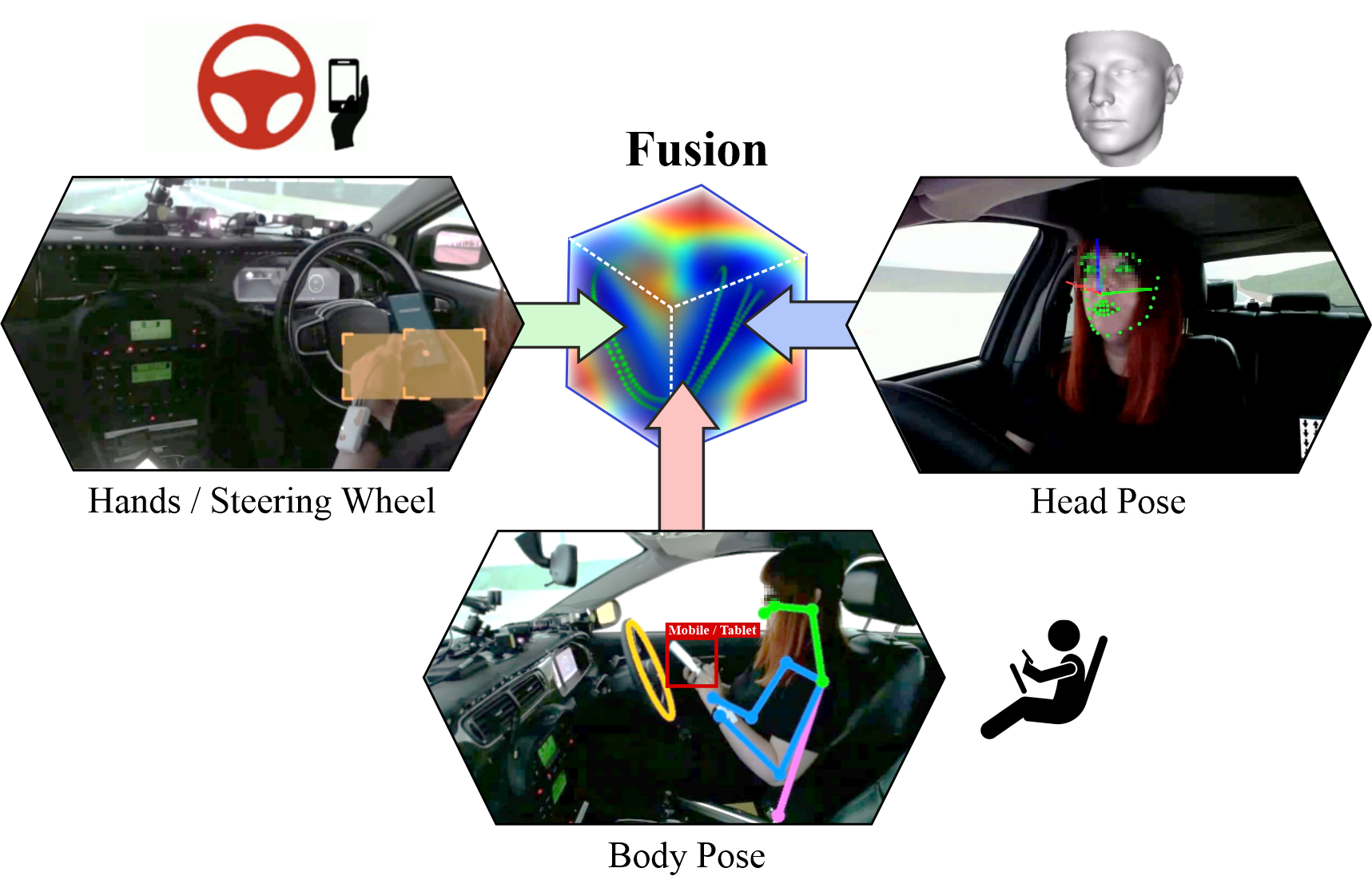
- Driver-Net通过多相机同步捕捉驾驶员头部、手部和身体姿势,利用双路径架构和跨模态融合策略,提升接管准备度预测的准确性。
- 实验结果表明,Driver-Net在驾驶员准备度分类中达到了95.8%的准确率,显著优于现有方法,验证了多模态和多视角融合的有效性。
📝 摘要(中文)
本文提出了一种名为Driver-Net的新型深度学习框架,该框架融合多相机输入以评估驾驶员在自动驾驶车辆中的接管准备度。与传统的基于视觉的驾驶员监控系统(侧重于头部姿势或眼睛注视)不同,Driver-Net通过三相机设置捕获驾驶员头部、手部和身体姿势的同步视觉线索。该模型采用双路径架构(包括上下文块和特征块)整合时空数据,然后采用跨模态融合策略来提高预测精度。在利兹大学驾驶模拟器收集的多样化数据集上进行评估,该方法在驾驶员准备度分类中实现了高达95.8%的准确率。这一性能显著优于现有方法,并突出了多模态和多视角融合的重要性。作为一个实时的、非侵入式的解决方案,Driver-Net为开发更安全、更可靠的自动驾驶车辆做出了有意义的贡献,并符合新的监管要求和即将到来的安全标准。
🔬 方法详解
问题定义:论文旨在解决自动驾驶车辆中驾驶员接管准备度评估的问题。现有方法主要依赖于单视角下的头部姿态或眼动追踪,无法全面捕捉驾驶员的状态信息,导致评估结果不够准确,容易出现安全隐患。这些方法忽略了手部动作、身体姿势等重要线索,并且缺乏对时序信息的有效利用。
核心思路:Driver-Net的核心思路是利用多相机融合技术,从多个视角捕捉驾驶员的头部、手部和身体姿势等信息,构建一个更全面的驾驶员状态表示。通过双路径架构提取时空特征,并采用跨模态融合策略,将不同视角的信息进行有效整合,从而提高驾驶员接管准备度评估的准确性和鲁棒性。
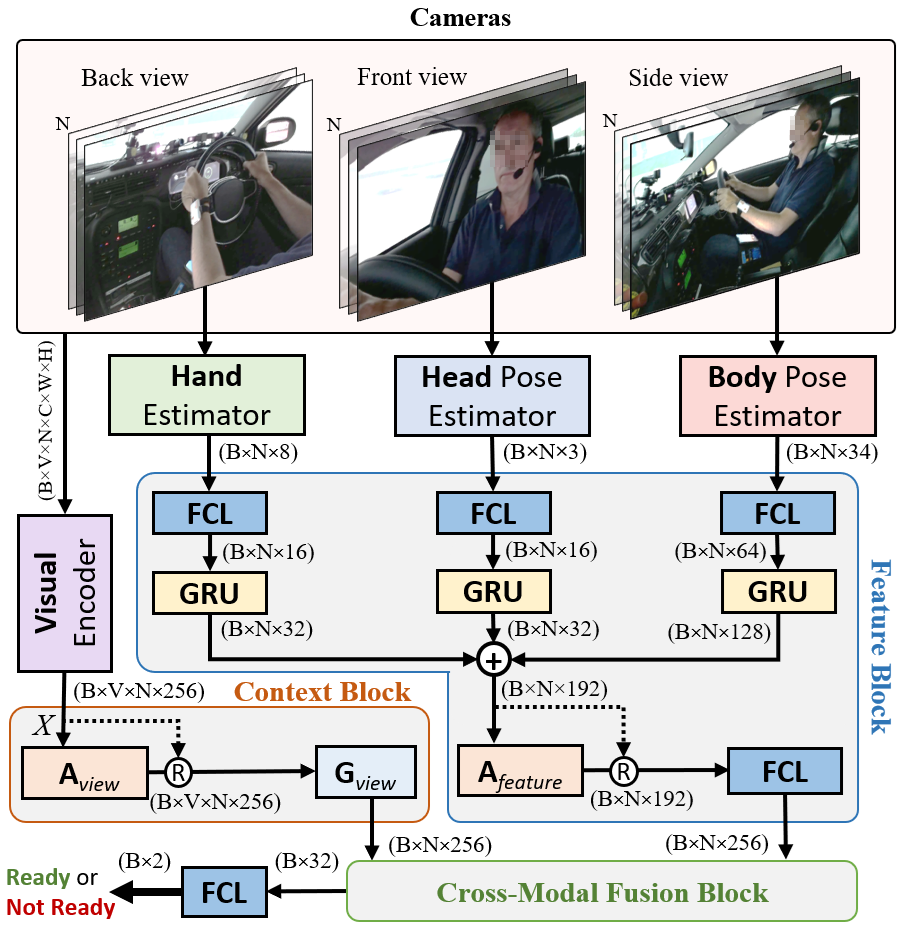
技术框架:Driver-Net的整体架构包含以下几个主要模块:1) 三相机输入:分别捕捉驾驶员的头部、手部和身体姿势。2) 双路径架构:包含Context Block和Feature Block,分别用于提取上下文信息和局部特征。3) 时空特征提取:利用LSTM等时序模型对每个相机视角的特征进行时序建模。4) 跨模态融合:将不同相机视角的时空特征进行融合,得到最终的驾驶员状态表示。5) 分类器:根据驾驶员状态表示,预测驾驶员的接管准备度。
关键创新:Driver-Net的关键创新在于以下几个方面:1) 多相机融合:首次将多相机融合技术应用于驾驶员接管准备度评估,能够更全面地捕捉驾驶员的状态信息。2) 双路径架构:Context Block和Feature Block的设计能够有效提取上下文信息和局部特征,提高特征表达能力。3) 跨模态融合策略:能够有效地将不同相机视角的特征进行融合,提高评估的准确性和鲁棒性。
关键设计:在网络结构方面,Context Block和Feature Block的具体实现方式未知,但可以推测使用了卷积神经网络等技术。时序特征提取可能采用了LSTM或GRU等循环神经网络。跨模态融合可能采用了注意力机制或简单的拼接操作。损失函数可能采用了交叉熵损失函数,用于训练分类器。具体的参数设置和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
Driver-Net在利兹大学驾驶模拟器数据集上进行了评估,结果表明,该方法在驾驶员准备度分类中实现了高达95.8%的准确率。这一性能显著优于现有的基于单视角的方法,证明了多相机融合和跨模态融合的有效性。具体的对比基线和提升幅度需要在论文中进一步查找。
🎯 应用场景
Driver-Net可应用于各种自动驾驶车辆,提升驾驶员接管的安全性。该技术可集成到高级驾驶辅助系统(ADAS)中,实时监控驾驶员状态,并在必要时发出警报或自动减速。此外,Driver-Net还可用于驾驶员培训和评估,帮助提高驾驶安全性,并为未来的自动驾驶安全标准提供参考。
📄 摘要(原文)
Ensuring safe transition of control in automated vehicles requires an accurate and timely assessment of driver readiness. This paper introduces Driver-Net, a novel deep learning framework that fuses multi-camera inputs to estimate driver take-over readiness. Unlike conventional vision-based driver monitoring systems that focus on head pose or eye gaze, Driver-Net captures synchronised visual cues from the driver's head, hands, and body posture through a triple-camera setup. The model integrates spatio-temporal data using a dual-path architecture, comprising a Context Block and a Feature Block, followed by a cross-modal fusion strategy to enhance prediction accuracy. Evaluated on a diverse dataset collected from the University of Leeds Driving Simulator, the proposed method achieves an accuracy of up to 95.8% in driver readiness classification. This performance significantly enhances existing approaches and highlights the importance of multimodal and multi-view fusion. As a real-time, non-intrusive solution, Driver-Net contributes meaningfully to the development of safer and more reliable automated vehicles and aligns with new regulatory mandates and upcoming safety standards.