Move to Understand a 3D Scene: Bridging Visual Grounding and Exploration for Efficient and Versatile Embodied Navigation
作者: Ziyu Zhu, Xilin Wang, Yixuan Li, Zhuofan Zhang, Xiaojian Ma, Yixin Chen, Baoxiong Jia, Wei Liang, Qian Yu, Zhidong Deng, Siyuan Huang, Qing Li
分类: cs.CV
发布日期: 2025-07-05 (更新: 2025-07-30)
备注: Embodied AI; 3D Vision Language Understanding; ICCV 2025 Highlight; https://mtu3d.github.io; Spatial intelligence
💡 一句话要点
提出MTU3D框架,桥接视觉理解与主动探索,实现高效通用具身导航
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身导航 视觉定位 主动探索 3D视觉-语言学习 在线表征学习
📋 核心要点
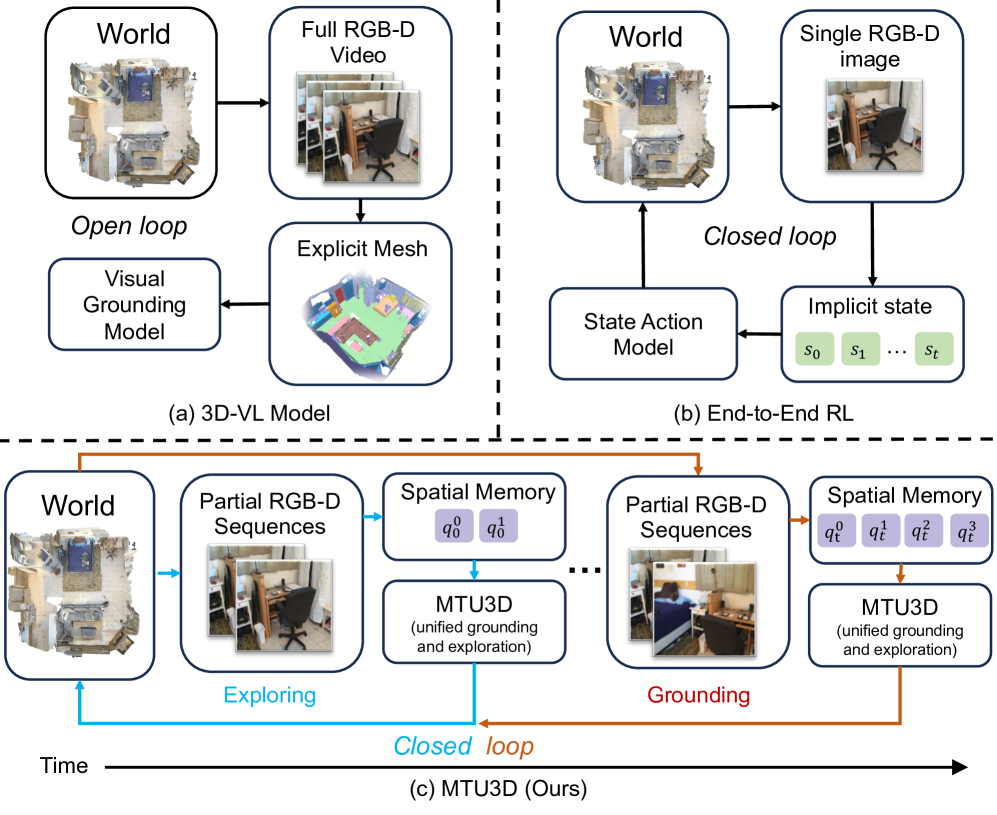
- 现有3D视觉-语言模型侧重于在静态3D重建中定位对象,缺乏主动感知和探索环境的能力。
- MTU3D框架通过在线查询式表征学习、统一的定位与探索目标以及端到端轨迹学习,实现主动探索和环境理解。
- 实验结果表明,MTU3D在多个具身导航和问答基准测试中显著优于现有方法,成功率提升高达23%。
📝 摘要(中文)
本文提出Move to Understand (MTU3D),一个统一的框架,将主动感知与3D视觉-语言学习相结合,使具身智能体能够有效地探索和理解环境。该框架包含三个关键创新:1) 基于在线查询的表征学习,能够直接从RGB-D帧构建空间记忆,无需显式的3D重建;2) 用于定位和探索的统一目标,将未探索的位置表示为前沿查询,并联合优化对象定位和前沿选择;3) 端到端轨迹学习,结合了视觉-语言-探索预训练,该预训练基于从模拟和真实RGB-D序列中收集的一百万条多样化轨迹。在各种具身导航和问答基准上的大量评估表明,MTU3D在HM3D-OVON、GOAT-Bench、SG3D和A-EQA上的成功率分别比最先进的强化学习和模块化导航方法高出14%、23%、9%和2%。MTU3D的多功能性支持使用包括类别、语言描述和参考图像在内的多种输入模态进行导航。这些发现突出了桥接视觉定位和探索对于具身智能的重要性。
🔬 方法详解
问题定义:现有3D视觉-语言模型主要关注于在静态的3D重建结果(如网格和点云)中定位物体,而忽略了智能体主动感知和探索环境的能力。这些方法无法让智能体自主决定下一步应该探索哪里,从而限制了其在复杂环境中的应用。
核心思路:MTU3D的核心思路是将视觉定位(Visual Grounding)和主动探索(Active Exploration)结合起来,通过让智能体在探索过程中不断学习和理解环境,从而实现更高效和通用的具身导航。该方法将未探索区域视为需要定位的“前沿(Frontier)”,并联合优化物体定位和前沿选择,从而引导智能体进行有效的探索。
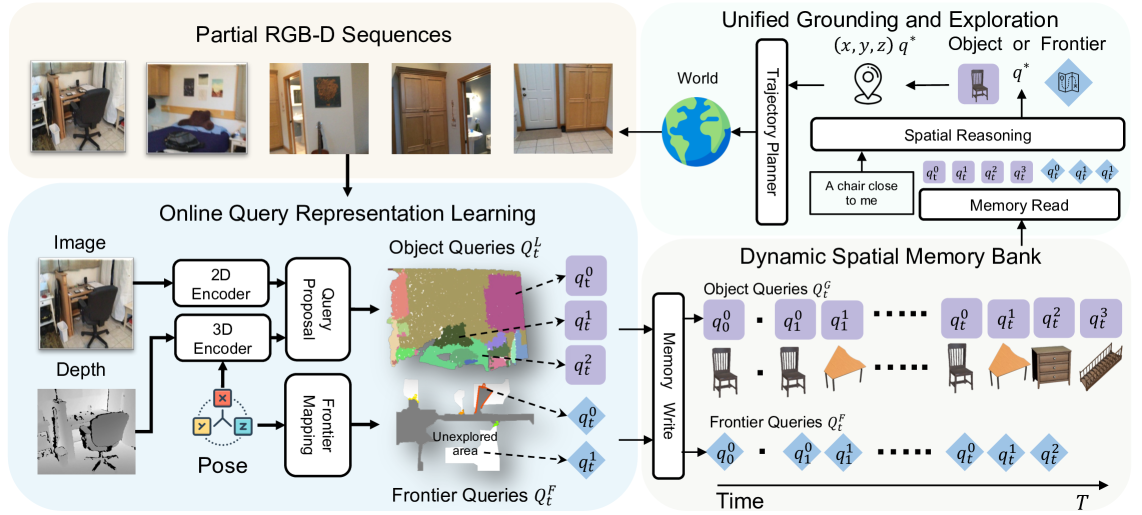
技术框架:MTU3D框架主要包含三个关键模块:1) 在线查询式表征学习:直接从RGB-D帧构建空间记忆,避免了耗时的3D重建过程。2) 统一的定位与探索目标:将未探索区域表示为前沿查询,并联合优化物体定位和前沿选择。3) 端到端轨迹学习:通过视觉-语言-探索预训练,学习智能体的导航策略。整体流程是,智能体接收RGB-D图像和语言指令,通过在线查询式表征学习构建环境记忆,然后根据统一的定位与探索目标选择下一步的行动,最终通过端到端轨迹学习优化导航策略。
关键创新:MTU3D最重要的创新在于将视觉定位和主动探索统一到一个框架中。与传统的先重建再定位的方法不同,MTU3D直接从RGB-D帧中学习空间表征,并利用前沿查询引导智能体进行探索。这种方法不仅提高了效率,还增强了智能体的适应性。
关键设计:在在线查询式表征学习中,使用了Transformer网络来处理RGB-D图像和语言指令,并生成空间表征。在统一的定位与探索目标中,使用了交叉熵损失函数来优化物体定位和前沿选择。在端到端轨迹学习中,使用了强化学习算法(未知)来优化导航策略。预训练数据包含一百万条来自模拟和真实环境的RGB-D轨迹。
🖼️ 关键图片
📊 实验亮点
MTU3D在多个具身导航和问答基准测试中取得了显著的性能提升。在HM3D-OVON上,成功率比现有方法高出14%;在GOAT-Bench上,成功率提升了23%;在SG3D和A-EQA上,分别提升了9%和2%。这些结果表明,MTU3D在各种复杂环境中都具有很强的泛化能力。
🎯 应用场景
MTU3D框架可应用于各种需要具身智能的场景,例如家庭服务机器人、仓库物流机器人、以及灾难救援机器人。该框架能够使机器人在未知环境中自主探索、定位物体、并完成各种任务,具有很高的实际应用价值和商业潜力。未来,该技术有望进一步扩展到虚拟现实、增强现实等领域。
📄 摘要(原文)
Embodied scene understanding requires not only comprehending visual-spatial information that has been observed but also determining where to explore next in the 3D physical world. Existing 3D Vision-Language (3D-VL) models primarily focus on grounding objects in static observations from 3D reconstruction, such as meshes and point clouds, but lack the ability to actively perceive and explore their environment. To address this limitation, we introduce \underline{\textbf{M}}ove \underline{\textbf{t}}o \underline{\textbf{U}}nderstand (\textbf{\model}), a unified framework that integrates active perception with \underline{\textbf{3D}} vision-language learning, enabling embodied agents to effectively explore and understand their environment. This is achieved by three key innovations: 1) Online query-based representation learning, enabling direct spatial memory construction from RGB-D frames, eliminating the need for explicit 3D reconstruction. 2) A unified objective for grounding and exploring, which represents unexplored locations as frontier queries and jointly optimizes object grounding and frontier selection. 3) End-to-end trajectory learning that combines \textbf{V}ision-\textbf{L}anguage-\textbf{E}xploration pre-training over a million diverse trajectories collected from both simulated and real-world RGB-D sequences. Extensive evaluations across various embodied navigation and question-answering benchmarks show that MTU3D outperforms state-of-the-art reinforcement learning and modular navigation approaches by 14\%, 23\%, 9\%, and 2\% in success rate on HM3D-OVON, GOAT-Bench, SG3D, and A-EQA, respectively. \model's versatility enables navigation using diverse input modalities, including categories, language descriptions, and reference images. These findings highlight the importance of bridging visual grounding and exploration for embodied intelligence.