FastDINOv2: Frequency Based Curriculum Learning Improves Robustness and Training Speed
作者: Jiaqi Zhang, Juntuo Wang, Zhixin Sun, John Zou, Randall Balestriero
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-07-04 (更新: 2025-11-18)
备注: Accepted by 39th Conference on Neural Information Processing Systems (NeurIPS 2025)
🔗 代码/项目: GITHUB
💡 一句话要点
FastDINOv2:基于频率的课程学习加速DINOv2预训练并提升鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自监督学习 视觉基础模型 DINOv2 课程学习 频率滤波 鲁棒性 预训练加速
📋 核心要点
- 现有DINOv2等视觉基础模型预训练计算成本高昂,阻碍了其在资源受限场景下的应用和进一步研究。
- 该论文提出一种基于频率滤波课程学习和高斯噪声补丁增强的预训练策略,旨在加速收敛并提升模型鲁棒性。
- 实验表明,该方法在降低计算成本的同时,保持了与基线模型相当的鲁棒性和线性探测性能。
📝 摘要(中文)
大规模视觉基础模型,如DINOv2,通过利用庞大的架构和训练数据集展现了卓越的性能。然而,许多场景需要从业者复现这些预训练方案,例如在私有数据上、新的模态上,或者仅仅是为了科学探索——这目前在计算上要求极高。因此,我们提出了一种用于DINOv2的新的预训练策略,该策略同时加速了收敛——并且作为副产品,增强了对常见损坏的鲁棒性。我们的方法包括频率滤波课程学习(先看到低频信息)和高斯噪声补丁增强。应用于在ImageNet-1K上训练的ViT-B/16骨干网络,在预训练时间和FLOPs分别减少1.6倍和2.25倍的情况下,我们的方法仍然在损坏基准测试(ImageNet-C)中实现了匹配的鲁棒性,并保持了与基线相比具有竞争力的线性探测性能。效率和鲁棒性的这种双重优势使得大规模自监督基础建模更易于实现,同时为围绕数据课程和增强作为提高自监督学习模型鲁棒性的手段的新探索打开了大门。代码可在https://github.com/KevinZ0217/fast_dinov2 获取。
🔬 方法详解
问题定义:论文旨在解决大规模视觉基础模型(如DINOv2)预训练过程中计算资源消耗过大的问题。现有方法训练时间长、计算成本高,难以在资源有限的场景下复现和应用。
核心思路:论文的核心思路是通过频率滤波课程学习,让模型先学习图像的低频信息,再逐步学习高频信息,从而加速收敛。同时,结合高斯噪声补丁增强,提高模型对常见图像损坏的鲁棒性。这种课程学习的策略模拟了人类视觉系统由粗到精的学习过程。
技术框架:整体框架基于DINOv2的自监督学习流程。主要包括以下几个阶段:1)数据预处理:对输入图像进行频率滤波,并应用高斯噪声补丁增强;2)特征提取:使用ViT-B/16骨干网络提取图像特征;3)自监督学习:利用DINOv2的目标函数进行训练,包括teacher-student架构和对比学习损失。
关键创新:论文的关键创新在于将频率滤波课程学习引入到DINOv2的预训练过程中。与传统的随机采样或数据增强方法不同,该方法通过控制输入图像的频率成分,引导模型逐步学习图像的结构信息,从而加速收敛并提高鲁棒性。
关键设计:1)频率滤波:使用高斯滤波器对图像进行滤波,控制低频信息的保留程度。2)高斯噪声补丁增强:在图像上随机添加高斯噪声补丁,模拟图像损坏,提高模型鲁棒性。3)课程学习策略:逐渐降低高斯滤波器的标准差,使模型逐步学习高频信息。4)损失函数:采用DINOv2的对比学习损失函数,鼓励模型学习图像的语义信息。
🖼️ 关键图片

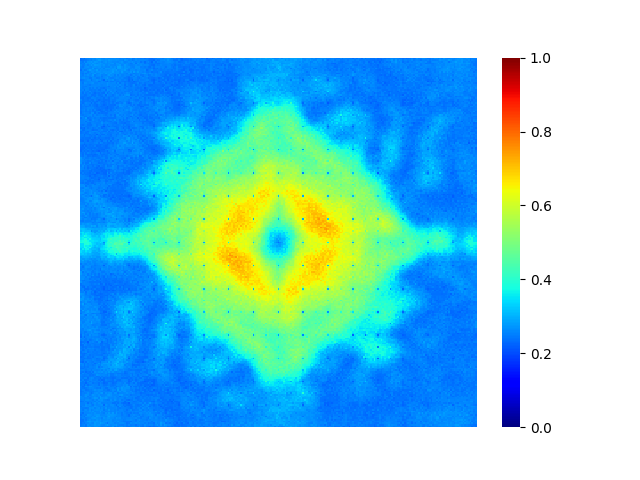
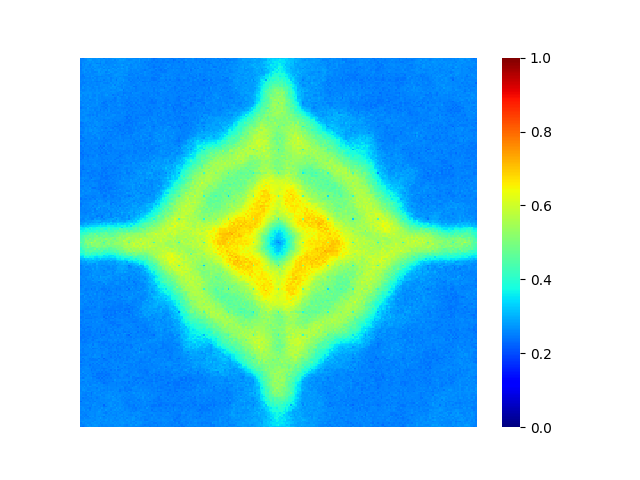
📊 实验亮点
在ImageNet-1K数据集上,使用ViT-B/16骨干网络进行实验,与基线DINOv2相比,该方法在预训练时间和FLOPs分别减少了1.6倍和2.25倍的情况下,在ImageNet-C损坏基准测试中实现了匹配的鲁棒性,并保持了具有竞争力的线性探测性能。这表明该方法在降低计算成本的同时,有效地提升了模型的性能。
🎯 应用场景
该研究成果可应用于各种需要大规模视觉基础模型的场景,例如图像识别、目标检测、图像分割等。尤其适用于计算资源有限的环境,例如移动设备、嵌入式系统等。通过降低预训练成本,该方法有望促进视觉基础模型在更多领域的应用和发展,例如自动驾驶、医疗影像分析等。
📄 摘要(原文)
Large-scale vision foundation models such as DINOv2 boast impressive performances by leveraging massive architectures and training datasets. But numerous scenarios require practitioners to reproduce those pre-training solutions, such as on private data, new modalities, or simply for scientific questioning--which is currently extremely demanding computation-wise. We thus propose a novel pre-training strategy for DINOv2 that simultaneously accelerates convergence--and strengthens robustness to common corruptions as a by-product. Our approach involves a frequency filtering curriculum--low-frequency being seen first--and the Gaussian noise patching augmentation. Applied to a ViT-B/16 backbone trained on ImageNet-1K, while pre-training time and FLOPs are reduced by 1.6x and 2.25x, our method still achieves matching robustness in corruption benchmarks (ImageNet-C) and maintains competitive linear probing performance compared with baseline. This dual benefit of efficiency and robustness makes large-scale self-supervised foundation modeling more attainable, while opening the door to novel exploration around data curriculum and augmentation as means to improve self-supervised learning models robustness. The code is available at https://github.com/KevinZ0217/fast_dinov2