StreamDiT: Real-Time Streaming Text-to-Video Generation
作者: Akio Kodaira, Tingbo Hou, Ji Hou, Markos Georgopoulos, Felix Juefei-Xu, Masayoshi Tomizuka, Yue Zhao
分类: cs.CV, cs.AI, cs.LG, eess.IV
发布日期: 2025-07-04 (更新: 2025-11-14)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
StreamDiT:提出一种基于流式扩散模型的实时文本到视频生成方法,实现512p分辨率下的16 FPS。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 文本到视频生成 流式生成 扩散模型 实时视频 模型蒸馏
📋 核心要点
- 现有文本到视频生成模型通常只能离线生成短视频,限制了其在实时交互应用中的潜力。
- StreamDiT通过流匹配和移动缓冲区,结合混合训练策略,提升视频内容一致性和视觉质量。
- 通过多步蒸馏方法,显著降低模型推理所需的计算量,最终实现512p分辨率下16 FPS的实时生成。
📝 摘要(中文)
本文提出StreamDiT,一种流式视频生成模型,旨在解决现有文本到视频(T2V)生成模型只能离线生成短视频片段,限制了其在交互式和实时应用中的问题。StreamDiT的训练基于流匹配,通过添加移动缓冲区实现。设计了混合训练策略,采用不同的缓冲帧分割方案,以提高内容一致性和视觉质量。StreamDiT的建模基于adaLN DiT,具有可变的时间嵌入和窗口注意力。训练了一个具有40亿参数的StreamDiT模型。此外,提出了一种为StreamDiT量身定制的多步蒸馏方法,在选定的分割方案的每个片段中执行采样蒸馏。蒸馏后,函数评估总数(NFEs)减少到缓冲区中的块数。最终,蒸馏后的模型在单个GPU上达到16 FPS的实时性能,可以生成512p分辨率的视频流。通过定量指标和人工评估验证了该方法。该模型支持实时应用,例如流式生成、交互式生成和视频到视频。
🔬 方法详解
问题定义:现有文本到视频生成模型通常是离线的,只能生成短视频片段,无法满足实时交互应用的需求。这些模型计算量大,难以部署到资源受限的设备上,并且缺乏对视频流的持续生成能力。
核心思路:StreamDiT的核心思路是将视频生成过程视为一个流式过程,通过维护一个移动缓冲区来模拟视频流。模型在每个时间步只处理缓冲区中的一小部分帧,从而降低计算复杂度,实现实时生成。同时,通过蒸馏技术进一步压缩模型,提高推理速度。
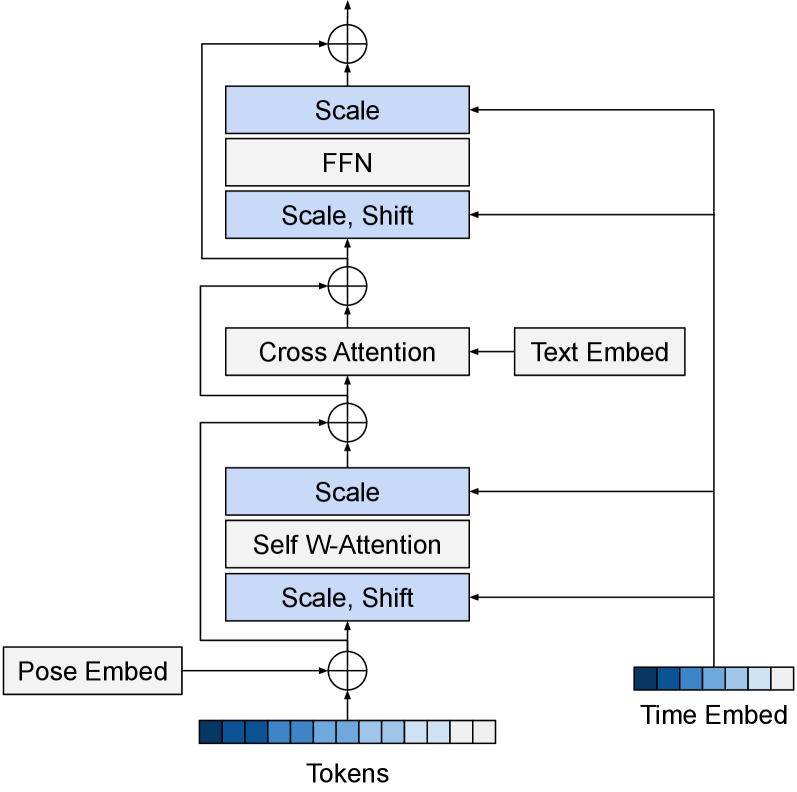
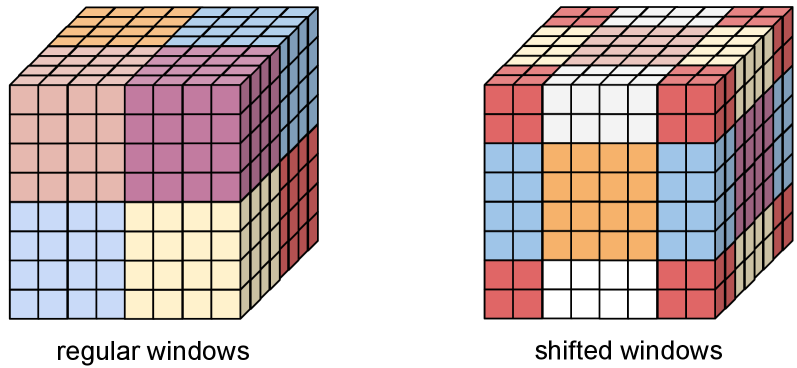
技术框架:StreamDiT的整体框架包括以下几个主要模块:1) 流匹配训练:使用流匹配目标函数训练模型,使其能够生成连续的视频流。2) 移动缓冲区:维护一个固定大小的缓冲区,存储最近生成的帧。3) 混合训练:采用不同的帧分割方案进行混合训练,以提高内容一致性和视觉质量。4) adaLN DiT建模:使用adaLN DiT作为基础模型,并引入可变的时间嵌入和窗口注意力机制。5) 多步蒸馏:通过多步蒸馏方法压缩模型,减少计算量。
关键创新:StreamDiT的关键创新在于其流式生成框架和多步蒸馏方法。流式生成框架允许模型在每个时间步只处理一小部分帧,从而降低计算复杂度。多步蒸馏方法通过逐步压缩模型,进一步提高推理速度,最终实现实时生成。与现有方法相比,StreamDiT能够生成更长的视频流,并且具有更高的生成速度。
关键设计:StreamDiT的关键设计包括:1) 移动缓冲区的大小:缓冲区大小的选择需要在计算复杂度和内容一致性之间进行权衡。2) 混合训练的分割方案:不同的分割方案会影响内容一致性和视觉质量。3) 多步蒸馏的蒸馏策略:蒸馏策略的选择会影响模型的压缩效果和生成质量。论文中具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
StreamDiT模型在单个GPU上实现了16 FPS的实时性能,可以生成512p分辨率的视频流。通过多步蒸馏方法,显著降低了模型推理所需的计算量。实验结果表明,StreamDiT在内容一致性和视觉质量方面都取得了良好的效果。具体的量化指标和对比基线未知。
🎯 应用场景
StreamDiT的潜在应用领域包括:实时视频生成、交互式视频编辑、虚拟现实、游戏、视频会议等。该技术可以用于创建个性化的视频内容,增强用户体验,并为各种应用提供更强大的视频生成能力。未来,StreamDiT可以进一步扩展到更高分辨率的视频生成,并支持更多模态的输入,例如音频和图像。
📄 摘要(原文)
Recently, great progress has been achieved in text-to-video (T2V) generation by scaling transformer-based diffusion models to billions of parameters, which can generate high-quality videos. However, existing models typically produce only short clips offline, restricting their use cases in interactive and real-time applications. This paper addresses these challenges by proposing StreamDiT, a streaming video generation model. StreamDiT training is based on flow matching by adding a moving buffer. We design mixed training with different partitioning schemes of buffered frames to boost both content consistency and visual quality. StreamDiT modeling is based on adaLN DiT with varying time embedding and window attention. To practice the proposed method, we train a StreamDiT model with 4B parameters. In addition, we propose a multistep distillation method tailored for StreamDiT. Sampling distillation is performed in each segment of a chosen partitioning scheme. After distillation, the total number of function evaluations (NFEs) is reduced to the number of chunks in a buffer. Finally, our distilled model reaches real-time performance at 16 FPS on one GPU, which can generate video streams at 512p resolution. We evaluate our method through both quantitative metrics and human evaluation. Our model enables real-time applications, e.g. streaming generation, interactive generation, and video-to-video. We provide video results and more examples in our project website: https://cumulo-autumn.github.io/StreamDiT/