ChestGPT: Integrating Large Language Models and Vision Transformers for Disease Detection and Localization in Chest X-Rays
作者: Shehroz S. Khan, Petar Przulj, Ahmed Ashraf, Ali Abedi
分类: cs.CV
发布日期: 2025-07-04 (更新: 2025-11-10)
备注: 8 pages, 5 figures, 4 tables
💡 一句话要点
ChestGPT:融合LLM与ViT的胸部X光疾病检测与定位框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 胸部X光 疾病检测 病灶定位 视觉Transformer 大型语言模型 迁移学习 计算机辅助诊断
📋 核心要点
- 放射科医生短缺日益严重,医学影像需求不断增长,现有计算机辅助诊断系统仍有提升空间。
- ChestGPT融合ViT和LLM,利用ViT提取图像特征,LLM进行疾病分类和定位,实现联合诊断。
- 在VinDr-CXR数据集上,ChestGPT的全局疾病分类F1值达到0.76,并能有效定位病灶区域。
📝 摘要(中文)
由于对医学影像服务日益增长的依赖,全球对放射科医生的需求正在迅速增加,而放射科医生的供应却未能跟上。计算机视觉和图像处理技术的进步为解决这一差距提供了巨大的潜力,可以增强放射科医生的能力并提高诊断准确性。大型语言模型(LLM),特别是生成式预训练Transformer(GPT),已成为理解和生成文本数据的主要方法。同时,视觉Transformer(ViT)已被证明能有效地将视觉数据转换为LLM可以有效处理的格式。本文提出ChestGPT,一个深度学习框架,它集成了EVA ViT和Llama 2 LLM,用于分类疾病并定位胸部X光图像中的感兴趣区域。ViT将X光图像转换为tokens,然后将这些tokens与设计的提示一起输入到LLM中,从而实现疾病的联合分类和定位。该方法结合了迁移学习技术,以增强可解释性和性能。所提出的方法在VinDr-CXR数据集上实现了强大的全局疾病分类性能,F1得分为0.76,并通过在感兴趣区域周围生成边界框成功地定位了病灶。我们还概述了放射科医生可能遇到的场景的几个特定任务提示,以及通用提示。总的来说,该框架提供了一种辅助工具,可以通过提供初步发现和感兴趣区域来简化放射科医生的工作量,以促进他们的诊断过程。
🔬 方法详解
问题定义:论文旨在解决胸部X光片中疾病的自动检测和定位问题。现有方法可能在准确性、可解释性或效率方面存在不足,无法充分满足日益增长的医学影像诊断需求。放射科医生工作负担重,需要更高效的辅助诊断工具。
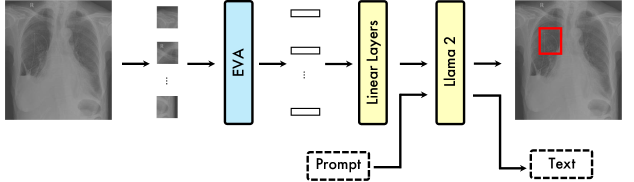
核心思路:论文的核心思路是将视觉信息(X光片)和语言模型结合,利用ViT提取图像特征,然后将这些特征作为LLM的输入,结合设计的提示(prompts),让LLM执行疾病分类和病灶定位任务。这种设计利用了LLM强大的语言理解和生成能力,以及ViT在视觉特征提取方面的优势。
技术框架:ChestGPT框架主要包含两个核心模块:EVA ViT和Llama 2 LLM。首先,EVA ViT将胸部X光图像转换为tokens。然后,这些tokens与精心设计的提示(prompts)一起输入到Llama 2 LLM中。LLM基于这些输入,执行疾病分类和病灶定位任务,最终输出疾病类别和病灶的边界框。整个过程利用了迁移学习技术来提升性能和可解释性。
关键创新:该论文的关键创新在于将ViT和LLM有效结合,用于胸部X光片的疾病检测和定位。与传统方法相比,ChestGPT能够利用LLM的语言理解能力,结合图像特征,实现更准确和可解释的诊断结果。此外,通过设计特定的提示(prompts),可以引导LLM执行不同的诊断任务。
关键设计:论文中关键的设计包括:1) 使用EVA ViT作为视觉特征提取器,因为它在视觉任务中表现出色。2) 选择Llama 2 LLM作为语言模型,因为它具有强大的语言理解和生成能力。3) 精心设计了针对不同诊断任务的提示(prompts),以引导LLM执行特定的任务。4) 使用迁移学习技术来提升模型的性能和泛化能力。具体的参数设置和损失函数等细节可能在论文正文中进一步阐述(未知)。
🖼️ 关键图片

📊 实验亮点
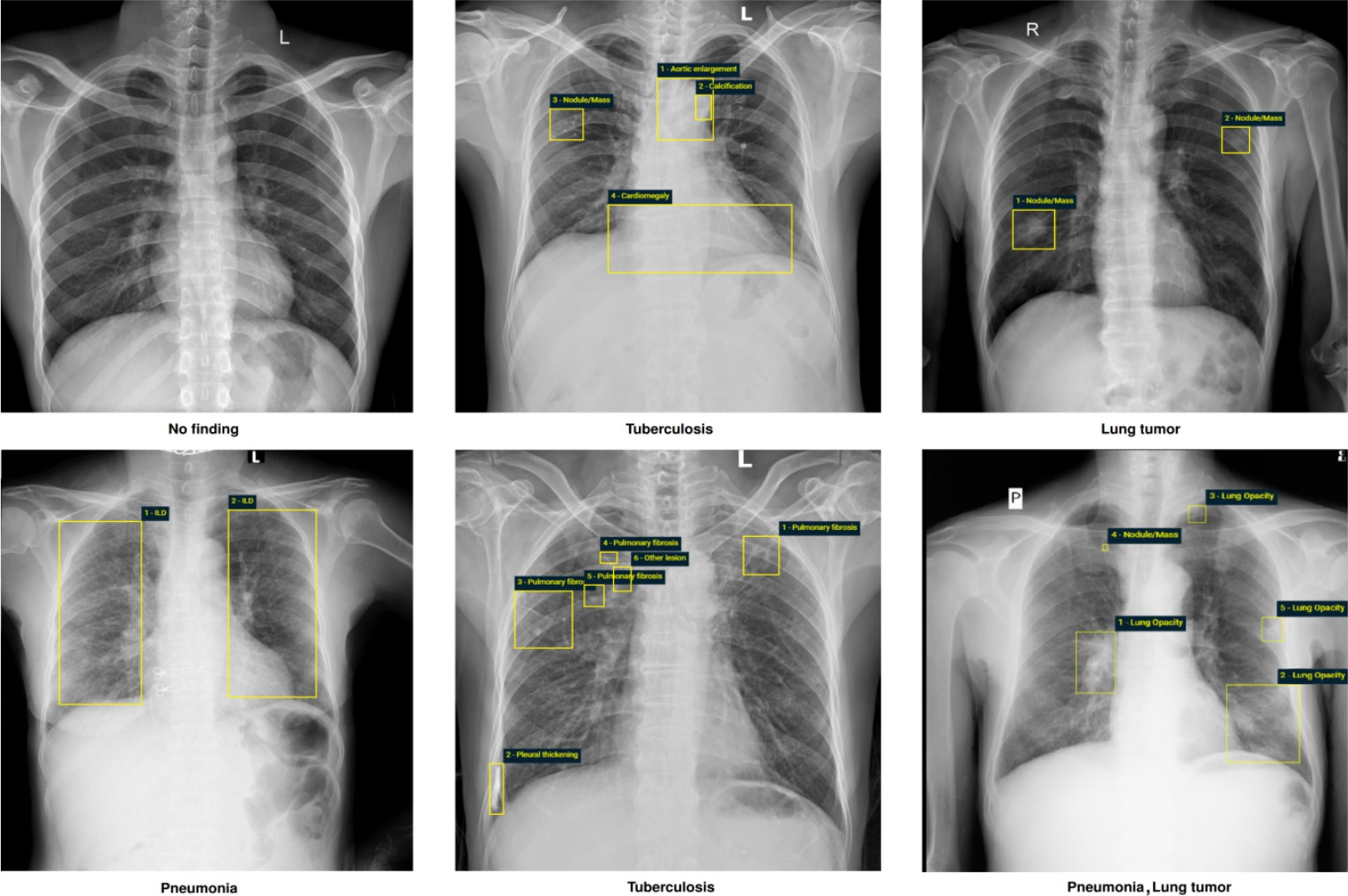
ChestGPT在VinDr-CXR数据集上取得了显著的成果,全局疾病分类的F1得分为0.76。此外,该模型能够成功地定位病灶区域,通过生成边界框来指示病灶的位置。这些结果表明,ChestGPT在胸部X光片疾病检测和定位方面具有很强的竞争力,并优于某些基线方法(具体对比基线和提升幅度未知)。
🎯 应用场景
ChestGPT可作为放射科医生的辅助诊断工具,减轻其工作负担,提高诊断效率和准确性。该技术可应用于远程医疗、基层医疗等场景,尤其是在放射科医生资源匮乏的地区。未来,该技术有望扩展到其他医学影像类型和疾病的诊断,为精准医疗提供更强大的支持。
📄 摘要(原文)
The global demand for radiologists is increasing rapidly due to a growing reliance on medical imaging services, while the supply of radiologists is not keeping pace. Advances in computer vision and image processing technologies present significant potential to address this gap by enhancing radiologists' capabilities and improving diagnostic accuracy. Large language models (LLMs), particularly generative pre-trained transformers (GPTs), have become the primary approach for understanding and generating textual data. In parallel, vision transformers (ViTs) have proven effective at converting visual data into a format that LLMs can process efficiently. In this paper, we present ChestGPT, a deep-learning framework that integrates the EVA ViT with the Llama 2 LLM to classify diseases and localize regions of interest in chest X-ray images. The ViT converts X-ray images into tokens, which are then fed, together with engineered prompts, into the LLM, enabling joint classification and localization of diseases. This approach incorporates transfer learning techniques to enhance both explainability and performance. The proposed method achieved strong global disease classification performance on the VinDr-CXR dataset, with an F1 score of 0.76, and successfully localized pathologies by generating bounding boxes around the regions of interest. We also outline several task-specific prompts, in addition to general-purpose prompts, for scenarios radiologists might encounter. Overall, this framework offers an assistive tool that can lighten radiologists' workload by providing preliminary findings and regions of interest to facilitate their diagnostic process.