Leveraging Out-of-Distribution Unlabeled Images: Semi-Supervised Semantic Segmentation with an Open-Vocabulary Model
作者: Wooseok Shin, Jisu Kang, Hyeonki Jeong, Jin Sob Kim, Sung Won Han
分类: cs.CV, cs.AI
发布日期: 2025-07-04 (更新: 2025-09-07)
备注: Accepted for publication in Knowledge-Based Systems
DOI: 10.1016/j.knosys.2025.114289
🔗 代码/项目: GITHUB
💡 一句话要点
提出SemiOVS框架,利用开放词汇模型有效提升半监督语义分割在OOD数据上的性能。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 半监督学习 语义分割 分布外数据 开放词汇分割 伪标签
📋 核心要点
- 现有半监督语义分割方法难以有效利用大量分布外(OOD)的无标签图像,因为直接使用可能引入噪声伪标签。
- 提出SemiOVS框架,利用开放词汇分割模型为OOD图像生成高质量伪标签,从而指导半监督学习。
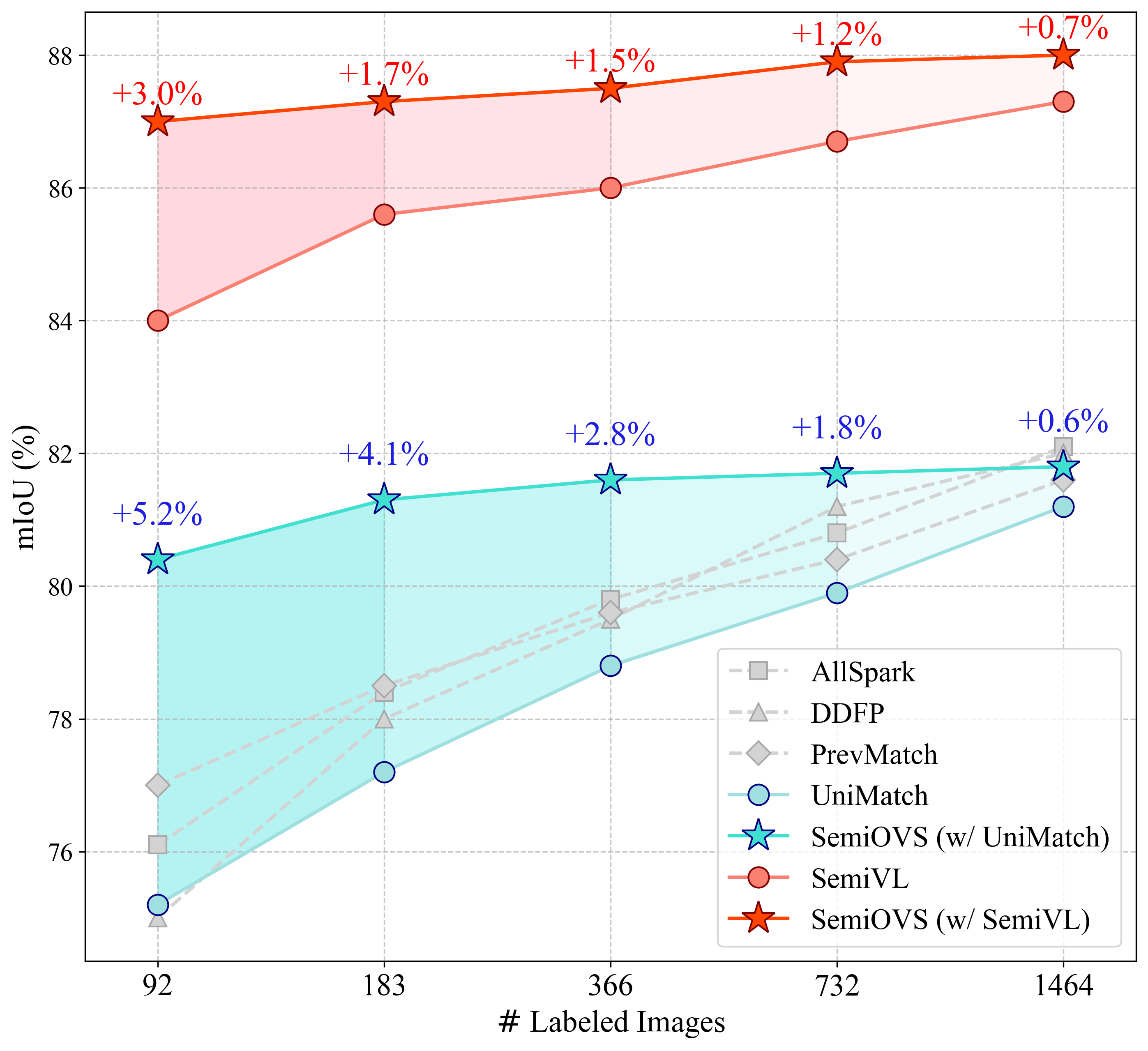
- 实验表明,SemiOVS在Pascal VOC上显著优于现有方法,尤其是在少量标签情况下,验证了OOD数据利用的有效性。
📝 摘要(中文)
在半监督语义分割中,现有研究在基准数据集的受控分割下取得了有希望的结果。然而,利用大量未标记图像的潜在好处仍未被探索。在实际场景中,通常可以从在线资源(网络抓取的图像)或大型数据集中获得大量未标记图像。但是,这些图像可能与目标数据集具有不同的分布,这种情况称为分布外(OOD)。在半监督学习中使用这些图像作为未标记数据可能导致不准确的伪标签,从而可能误导网络训练。在本文中,我们提出了一个新的半监督语义分割框架,该框架具有开放词汇分割模型(SemiOVS),可以有效地利用未标记的OOD图像。在Pascal VOC和Context数据集上的大量实验表明了两个关键发现:(1)在标签较少的场景中,使用额外的未标记图像可以提高半监督学习器的性能,以及(2)使用开放词汇分割(OVS)模型对OOD图像进行伪标签可以带来显着的性能提升。特别地,在92个标签的设置下,SemiOVS在Pascal VOC上分别优于现有的PrevMatch和SemiVL方法+3.5和+3.0 mIoU,实现了最先进的性能。这些发现表明,我们的方法有效地利用了大量未标记的OOD图像进行语义分割任务。我们希望这项工作能够激发未来的研究和实际应用。代码可在https://github.com/wooseok-shin/SemiOVS获得。
🔬 方法详解
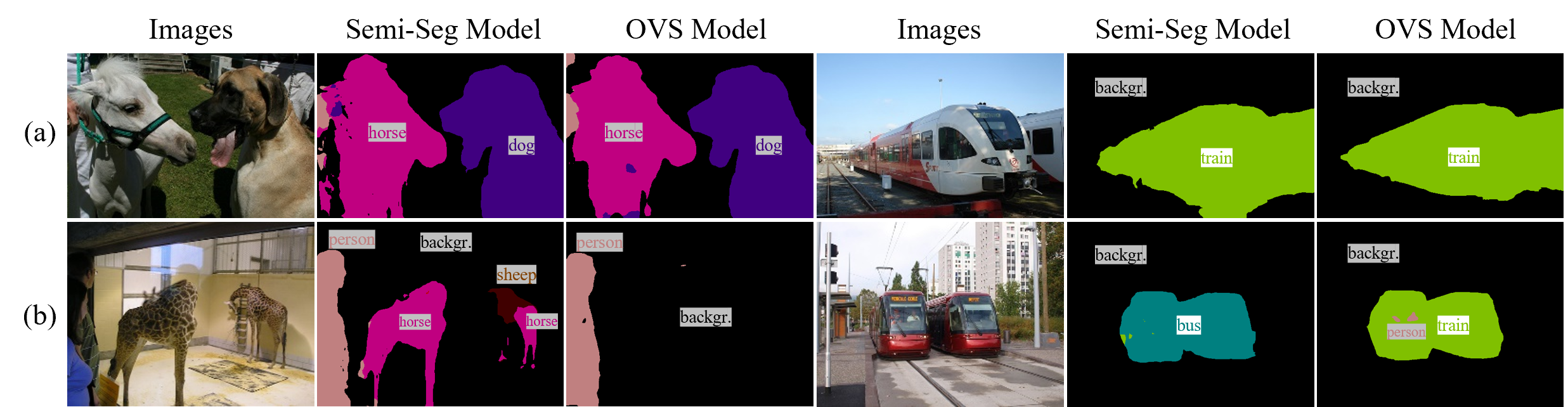
问题定义:现有半监督语义分割方法在利用大量未标注数据时,尤其当这些数据是分布外(Out-of-Distribution, OOD)数据时,会面临挑战。直接将OOD数据用于训练可能导致伪标签质量下降,进而损害模型性能。因此,如何有效利用OOD无标签数据来提升半监督语义分割的性能是一个关键问题。
核心思路:SemiOVS的核心思路是利用开放词汇分割(Open-Vocabulary Segmentation, OVS)模型为OOD图像生成高质量的伪标签。OVS模型能够识别更广泛的类别,从而更好地适应OOD数据的分布差异。通过高质量的伪标签,可以更有效地利用OOD数据来提升半监督学习的性能。
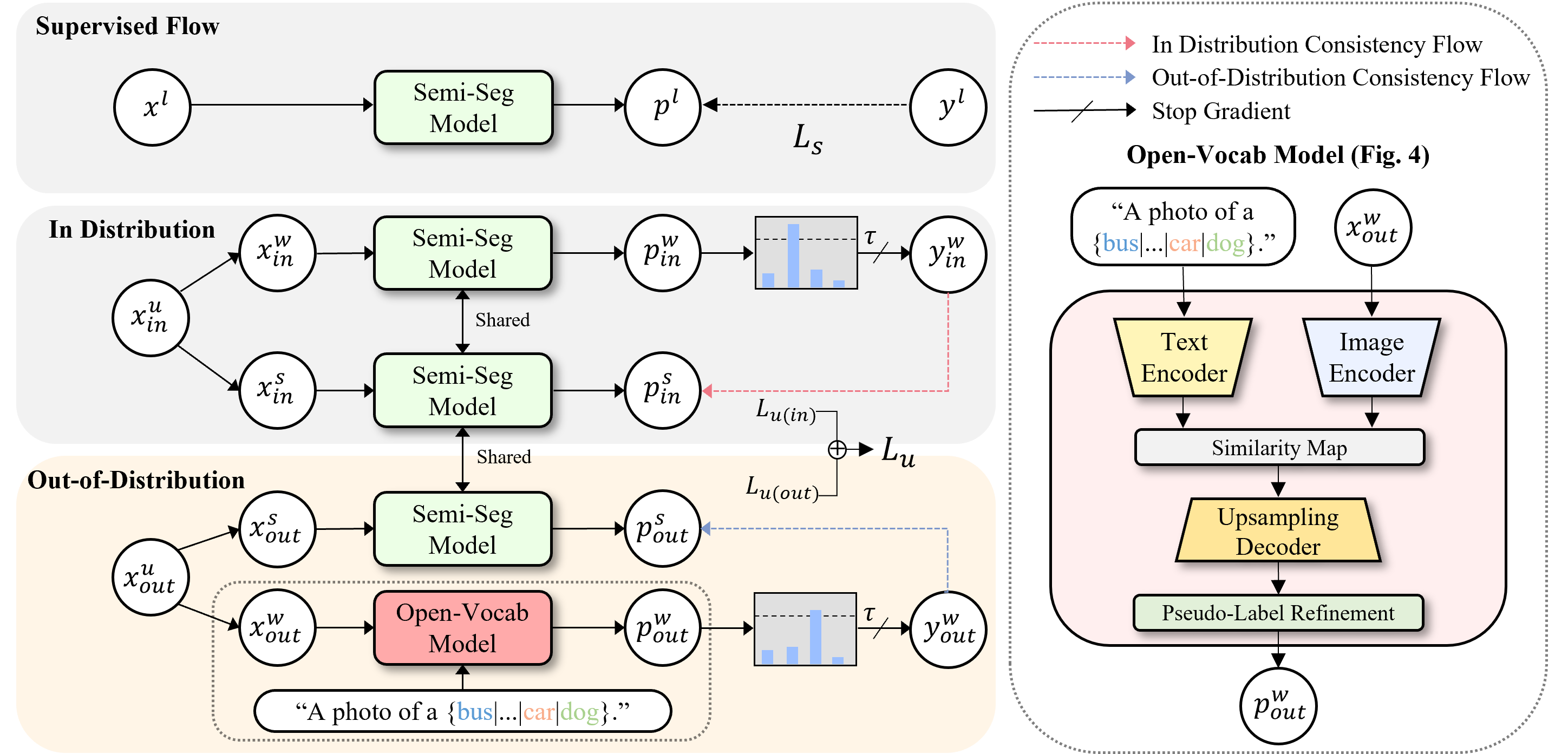
技术框架:SemiOVS框架包含以下主要模块:1) 开放词汇分割模型:用于生成OOD图像的伪标签。2) 半监督学习模块:利用带标签数据和伪标签的OOD数据进行训练。3) 一致性正则化:鼓励模型在带标签数据和伪标签数据上产生一致的预测。整体流程是首先使用OVS模型为OOD图像生成伪标签,然后将带标签数据和伪标签的OOD数据一起用于半监督学习,并通过一致性正则化来提高模型的泛化能力。
关键创新:SemiOVS的关键创新在于利用开放词汇分割模型来处理OOD数据。与传统的半监督学习方法直接使用OOD数据生成伪标签不同,SemiOVS通过OVS模型提高了伪标签的质量,从而更有效地利用了OOD数据。这种方法能够更好地适应OOD数据的分布差异,从而提升半监督学习的性能。
关键设计:在SemiOVS中,OVS模型采用CLIP模型进行图像和文本特征的对齐,从而实现开放词汇的分割能力。损失函数包括带标签数据的交叉熵损失、伪标签数据的交叉熵损失以及一致性正则化损失。一致性正则化损失鼓励模型在带标签数据和伪标签数据上产生一致的预测,从而提高模型的泛化能力。具体的网络结构和参数设置可以参考论文原文和代码。
🖼️ 关键图片
📊 实验亮点
SemiOVS在Pascal VOC数据集上,仅使用92个标注样本的情况下,相较于PrevMatch和SemiVL方法,分别取得了+3.5和+3.0 mIoU的性能提升,达到了state-of-the-art的水平。这充分证明了该方法在利用OOD数据进行半监督语义分割方面的有效性。
🎯 应用场景
该研究成果可应用于自动驾驶、遥感图像分析、医学图像分割等领域。在这些领域中,往往存在大量未标注的图像数据,而标注成本较高。SemiOVS方法能够有效利用这些未标注的OOD数据,从而降低标注成本,提高模型性能,具有重要的实际应用价值。
📄 摘要(原文)
In semi-supervised semantic segmentation, existing studies have shown promising results in academic settings with controlled splits of benchmark datasets. However, the potential benefits of leveraging significantly larger sets of unlabeled images remain unexplored. In real-world scenarios, abundant unlabeled images are often available from online sources (web-scraped images) or large-scale datasets. However, these images may have different distributions from those of the target dataset, a situation known as out-of-distribution (OOD). Using these images as unlabeled data in semi-supervised learning can lead to inaccurate pseudo-labels, potentially misguiding network training. In this paper, we propose a new semi-supervised semantic segmentation framework with an open-vocabulary segmentation model (SemiOVS) to effectively utilize unlabeled OOD images. Extensive experiments on Pascal VOC and Context datasets demonstrate two key findings: (1) using additional unlabeled images improves the performance of semi-supervised learners in scenarios with few labels, and (2) using the open-vocabulary segmentation (OVS) model to pseudo-label OOD images leads to substantial performance gains. In particular, SemiOVS outperforms existing PrevMatch and SemiVL methods by +3.5 and +3.0 mIoU, respectively, on Pascal VOC with a 92-label setting, achieving state-of-the-art performance. These findings demonstrate that our approach effectively utilizes abundant unlabeled OOD images for semantic segmentation tasks. We hope this work can inspire future research and real-world applications. The code is available at https://github.com/wooseok-shin/SemiOVS