Point3R: Streaming 3D Reconstruction with Explicit Spatial Pointer Memory
作者: Yuqi Wu, Wenzhao Zheng, Jie Zhou, Jiwen Lu
分类: cs.CV, cs.AI, cs.LG
发布日期: 2025-07-03 (更新: 2025-11-28)
备注: Code is available at: https://github.com/YkiWu/Point3R
🔗 代码/项目: GITHUB
💡 一句话要点
Point3R:利用显式空间指针记忆实现流式3D重建
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 3D重建 流式重建 空间指针记忆 显式记忆 深度学习
📋 核心要点
- 现有方法依赖隐式记忆进行密集3D重建,但存在容量限制和早期帧信息丢失的问题。
- Point3R通过维护显式空间指针记忆,直接关联场景3D结构,解决信息损失问题。
- Point3R在多个任务上取得了有竞争力的或最先进的性能,且训练成本较低。
📝 摘要(中文)
本文提出Point3R,一个面向密集流式3D重建的在线框架。与DUSt3R类似,该框架将图像对密集地统一到共享坐标系中。不同的是,Point3R维护一个与当前场景的3D结构直接相关的显式空间指针记忆。该记忆中的每个指针都被分配一个特定的3D位置,并将全局坐标系中附近的场景信息聚合到不断变化的空间特征中。从最新帧提取的信息与该指针记忆显式交互,从而能够将当前观测密集地集成到全局坐标系中。我们设计了一种3D分层位置嵌入来促进这种交互,并设计了一种简单而有效的融合机制,以确保我们的指针记忆是均匀且高效的。我们的方法以较低的训练成本在各种任务上实现了有竞争力的或最先进的性能。
🔬 方法详解
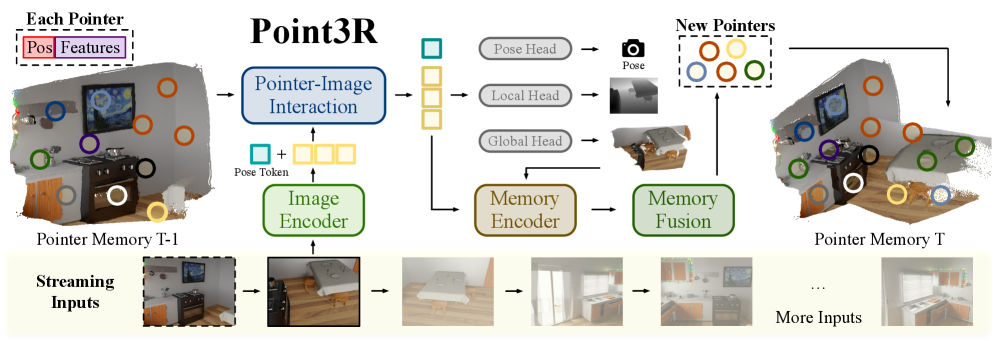
问题定义:论文旨在解决从有序序列或无序图像集合中进行密集3D场景重建的问题。现有方法,如DUSt3R,虽然统一了图像对到共享坐标系,但后续方法依赖隐式记忆来整合更多图像信息,这种隐式记忆容量有限,容易丢失早期帧的信息,导致重建质量下降。
核心思路:Point3R的核心思路是维护一个显式的空间指针记忆,该记忆直接与当前场景的3D结构相关联。每个指针对应一个特定的3D位置,并聚合该位置附近的场景信息。通过显式地与最新帧提取的信息交互,实现当前观测到全局坐标系的密集集成。这种显式记忆的设计旨在克服隐式记忆的容量限制和信息丢失问题。
技术框架:Point3R框架包含以下主要模块:1) 特征提取模块,从输入图像中提取特征;2) 空间指针记忆模块,维护一个显式的3D空间指针集合,每个指针包含一个3D位置和对应的特征向量;3) 信息交互模块,将最新帧的特征与空间指针记忆进行交互,更新指针的特征向量;4) 3D重建模块,利用更新后的空间指针记忆进行密集3D重建。整体流程是,输入图像经过特征提取后,与空间指针记忆进行交互,更新记忆中的特征,最后利用更新后的记忆进行3D重建。
关键创新:Point3R的关键创新在于引入了显式的空间指针记忆。与以往方法使用隐式记忆不同,Point3R直接维护一个与3D场景结构相关的指针集合,每个指针对应一个具体的3D位置。这种显式记忆的设计使得信息可以更有效地存储和更新,避免了隐式记忆的信息丢失问题。此外,3D分层位置嵌入的设计也促进了信息交互,提升了重建效果。
关键设计:Point3R的关键设计包括:1) 3D分层位置嵌入,用于编码指针的3D位置信息,促进信息交互;2) 一种简单而有效的融合机制,用于更新空间指针记忆中的特征向量,保证记忆的均匀性和高效性;3) 损失函数的设计,用于优化网络参数,提升重建质量。具体的参数设置和网络结构细节在论文中有详细描述。
🖼️ 关键图片


📊 实验亮点
Point3R在多个数据集上取得了有竞争力的或最先进的性能。实验结果表明,Point3R能够有效地利用显式空间指针记忆进行密集3D重建,尤其是在长序列和复杂场景下,相比于依赖隐式记忆的方法,Point3R能够更好地保持场景的细节信息,重建质量更高。同时,Point3R的训练成本较低,易于部署和应用。
🎯 应用场景
Point3R在机器人导航、自动驾驶、增强现实和虚拟现实等领域具有广泛的应用前景。它可以用于构建高精度的3D地图,为机器人提供环境感知能力。在自动驾驶中,可以用于实时重建周围环境,提高驾驶安全性。在AR/VR中,可以用于构建逼真的虚拟场景,提升用户体验。此外,该技术还可以应用于文物保护、城市建模等领域。
📄 摘要(原文)
Dense 3D scene reconstruction from an ordered sequence or unordered image collections is a critical step when bringing research in computer vision into practical scenarios. Following the paradigm introduced by DUSt3R, which unifies an image pair densely into a shared coordinate system, subsequent methods maintain an implicit memory to achieve dense 3D reconstruction from more images. However, such implicit memory is limited in capacity and may suffer from information loss of earlier frames. We propose Point3R, an online framework targeting dense streaming 3D reconstruction. To be specific, we maintain an explicit spatial pointer memory directly associated with the 3D structure of the current scene. Each pointer in this memory is assigned a specific 3D position and aggregates scene information nearby in the global coordinate system into a changing spatial feature. Information extracted from the latest frame interacts explicitly with this pointer memory, enabling dense integration of the current observation into the global coordinate system. We design a 3D hierarchical position embedding to promote this interaction and design a simple yet effective fusion mechanism to ensure that our pointer memory is uniform and efficient. Our method achieves competitive or state-of-the-art performance on various tasks with low training costs. Code: https://github.com/YkiWu/Point3R.