From Long Videos to Engaging Clips: A Human-Inspired Video Editing Framework with Multimodal Narrative Understanding
作者: Xiangfeng Wang, Xiao Li, Yadong Wei, Xueyu Song, Yang Song, Xiaoqiang Xia, Fangrui Zeng, Zaiyi Chen, Liu Liu, Gu Xu, Tong Xu
分类: cs.CV, cs.CL
发布日期: 2025-07-03 (更新: 2025-10-03)
备注: Accepted by EMNLP 2025 Industry Track
💡 一句话要点
提出HIVE框架,利用多模态叙事理解实现长视频到精彩短视频的自动剪辑
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动视频编辑 多模态叙事理解 长视频摘要 短视频生成 大型语言模型 视频内容分析 视频剪辑 DramaAD数据集
📋 核心要点
- 现有自动视频编辑方法忽略视觉信息,依赖文本线索,导致剪辑后的视频缺乏连贯性。
- HIVE框架通过多模态大型语言模型进行角色提取、对话分析和叙事总结,实现对视频内容的全面理解。
- 实验结果表明,HIVE框架在通用和广告视频编辑任务中均优于现有方法,显著提升了编辑质量。
📝 摘要(中文)
在线视频内容的快速增长,特别是短视频平台,对高效的视频编辑技术提出了更高的需求,以便将长视频浓缩成简洁而引人入胜的短片。现有的自动编辑方法主要依赖于ASR转录的文本线索和端到端片段选择,常常忽略了丰富的视觉上下文,导致输出不连贯。本文提出了一种受人类启发式的自动视频编辑框架(HIVE),该框架利用多模态叙事理解来解决这些局限性。我们的方法通过多模态大型语言模型整合了角色提取、对话分析和叙事总结,从而实现对视频内容的整体理解。为了进一步提高连贯性,我们应用场景级分割,并将编辑过程分解为三个子任务:高光检测、开头/结尾选择以及不相关内容的修剪。为了促进该领域的研究,我们引入了DramaAD,这是一个包含800多个短剧集和500个专业编辑的广告片段的新基准数据集。实验结果表明,我们的框架在通用和面向广告的编辑任务中始终优于现有的基线方法,显著缩小了自动编辑视频和人工编辑视频之间的质量差距。
🔬 方法详解
问题定义:现有自动视频编辑方法主要依赖ASR转录文本,忽略了视频中的视觉信息,导致剪辑后的短视频缺乏连贯性和吸引力。此外,端到端的片段选择方法难以捕捉视频的整体叙事结构,使得编辑结果往往不尽人意。因此,如何充分利用视频中的多模态信息,并结合叙事理解,生成高质量的短视频是本文要解决的核心问题。
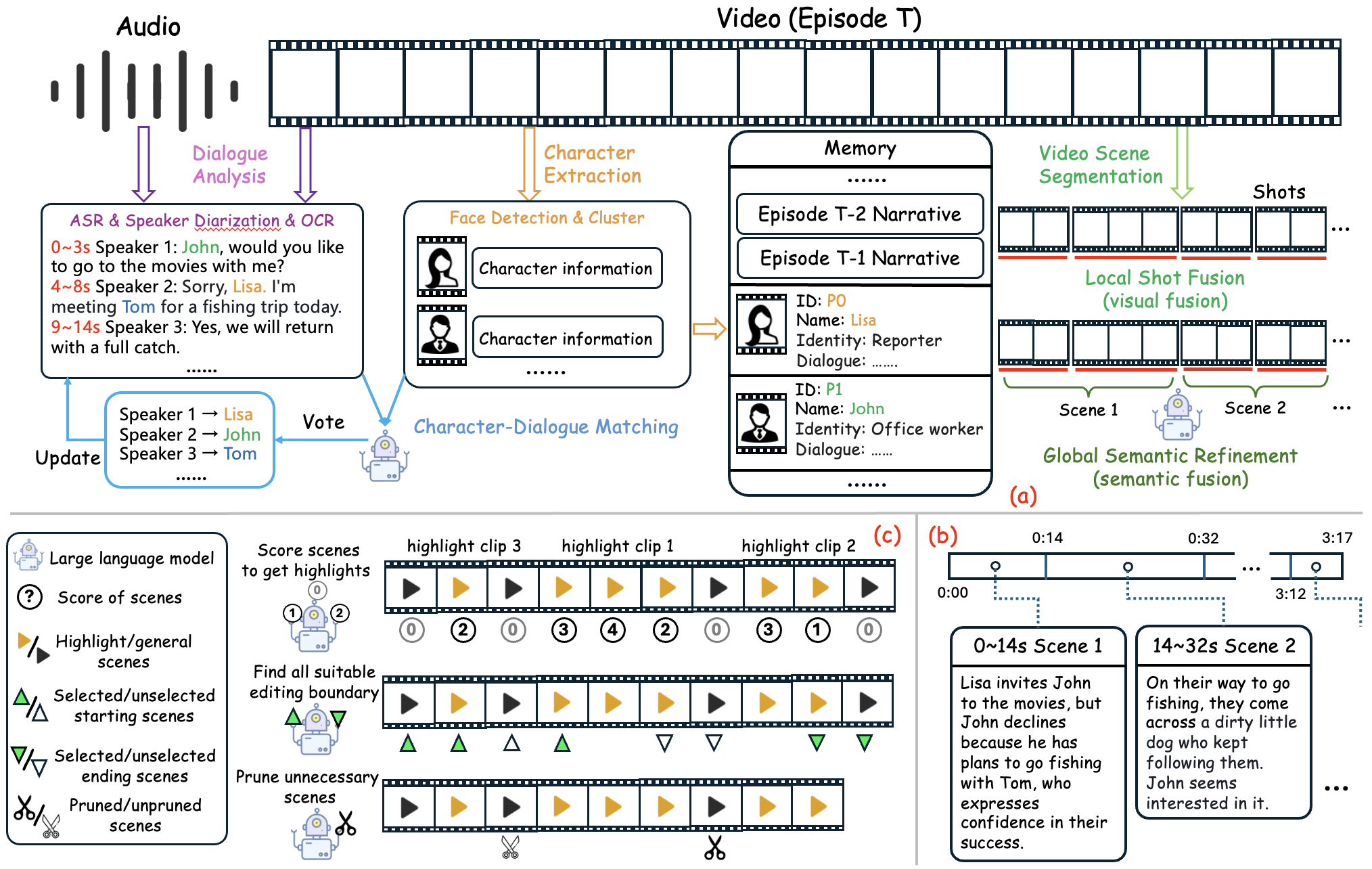
核心思路:本文的核心思路是模仿人类编辑视频的方式,通过理解视频的叙事结构和关键信息,有选择性地提取和组合视频片段。具体来说,就是利用多模态大型语言模型来提取视频中的角色、分析对话,并进行叙事总结,从而获得对视频内容的全面理解。然后,根据这些理解,进行高光检测、开头/结尾选择和不相关内容修剪,最终生成高质量的短视频。
技术框架:HIVE框架主要包含以下几个模块:1) 多模态叙事理解模块:利用多模态大型语言模型提取视频中的角色、分析对话,并进行叙事总结。2) 场景分割模块:将视频分割成不同的场景,以便更好地进行片段选择。3) 编辑子任务模块:将编辑过程分解为三个子任务:高光检测、开头/结尾选择和不相关内容修剪。4) 片段组合模块:根据编辑子任务的结果,将选定的片段组合成最终的短视频。
关键创新:本文最重要的技术创新点在于将多模态叙事理解引入到自动视频编辑中。通过利用多模态大型语言模型,HIVE框架能够更好地理解视频的内容和叙事结构,从而生成更具吸引力和连贯性的短视频。与现有方法相比,HIVE框架不仅考虑了视频中的文本信息,还充分利用了视觉信息,从而实现了更全面的视频理解。
关键设计:在多模态叙事理解模块中,使用了预训练的多模态大型语言模型,并针对视频编辑任务进行了微调。在编辑子任务模块中,使用了不同的算法来分别实现高光检测、开头/结尾选择和不相关内容修剪。例如,在高光检测中,使用了基于注意力的机制来识别视频中的关键帧。在开头/结尾选择中,使用了基于叙事结构的算法来选择合适的开头和结尾。在不相关内容修剪中,使用了基于内容相似度的算法来删除不相关的片段。
🖼️ 关键图片
📊 实验亮点
实验结果表明,HIVE框架在DramaAD数据集上显著优于现有基线方法。在通用视频编辑任务中,HIVE框架的性能提升了约10%。在广告视频编辑任务中,HIVE框架的性能提升了约15%。此外,用户研究表明,HIVE框架生成的短视频在吸引力、连贯性和信息量方面均接近人工编辑的视频。
🎯 应用场景
该研究成果可广泛应用于短视频自动生成、广告视频编辑、电影预告片制作等领域。通过自动将长视频剪辑成精彩短片,可以有效降低视频制作成本,提高内容生产效率,并为用户提供更优质的观看体验。未来,该技术有望进一步应用于个性化视频推荐、智能视频搜索等领域。
📄 摘要(原文)
The rapid growth of online video content, especially on short video platforms, has created a growing demand for efficient video editing techniques that can condense long-form videos into concise and engaging clips. Existing automatic editing methods predominantly rely on textual cues from ASR transcripts and end-to-end segment selection, often neglecting the rich visual context and leading to incoherent outputs. In this paper, we propose a human-inspired automatic video editing framework (HIVE) that leverages multimodal narrative understanding to address these limitations. Our approach incorporates character extraction, dialogue analysis, and narrative summarization through multimodal large language models, enabling a holistic understanding of the video content. To further enhance coherence, we apply scene-level segmentation and decompose the editing process into three subtasks: highlight detection, opening/ending selection, and pruning of irrelevant content. To facilitate research in this area, we introduce DramaAD, a novel benchmark dataset comprising over 800 short drama episodes and 500 professionally edited advertisement clips. Experimental results demonstrate that our framework consistently outperforms existing baselines across both general and advertisement-oriented editing tasks, significantly narrowing the quality gap between automatic and human-edited videos.