LaCo: Efficient Layer-wise Compression of Visual Tokens for Multimodal Large Language Models
作者: Juntao Liu, Liqiang Niu, Wenchao Chen, Jie Zhou, Fandong Meng
分类: cs.CV
发布日期: 2025-07-03
💡 一句话要点
提出LaCo,实现多模态大语言模型视觉Token的层间高效压缩。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉Token压缩 层间压缩 像素重组 残差学习
📋 核心要点
- 现有视觉Token压缩方法作为后处理模块,限制了多模态大语言模型的效率提升。
- LaCo通过层间像素重组和残差学习,在视觉编码器中间层实现高效Token压缩。
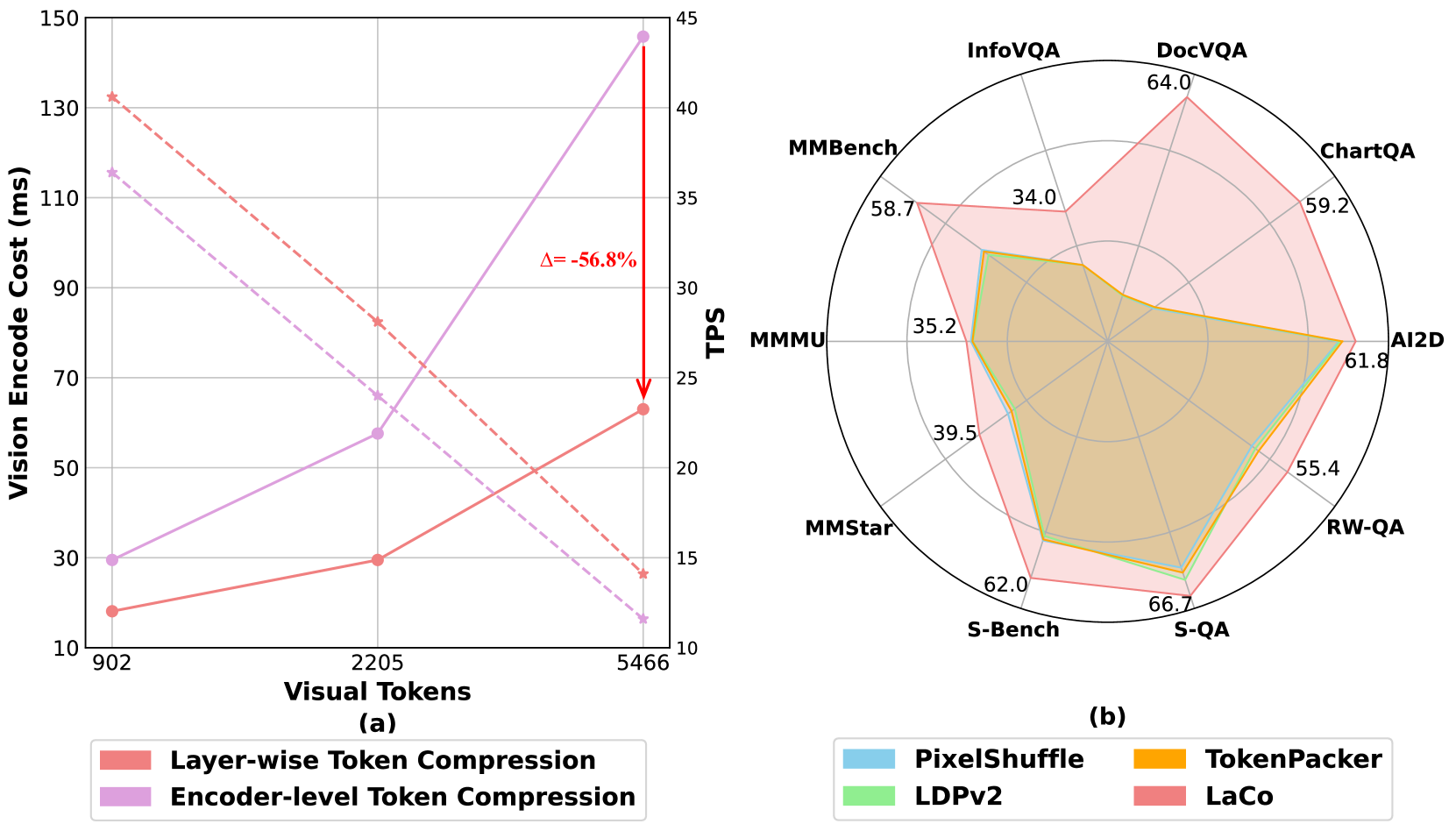
- 实验表明,LaCo在中间层压缩Token时优于现有方法,训练效率提升超20%,推理吞吐量提升超15%。
📝 摘要(中文)
现有的多模态大语言模型(MLLM)视觉Token压缩方法主要作为后编码器模块运行,限制了效率提升的潜力。为了解决这一局限性,我们提出了LaCo(层间视觉Token压缩),这是一个新颖的框架,能够在视觉编码器的中间层实现有效的Token压缩。LaCo引入了两个核心组件:1)层间像素重组机制,通过空间到通道的转换系统地合并相邻Token;2)具有非参数捷径的残差学习架构,可在压缩过程中保留关键的视觉信息。大量的实验表明,在视觉编码器的中间层压缩Token时,我们的LaCo优于所有现有方法,展示了卓越的有效性。此外,与外部压缩相比,我们的方法在保持强大性能的同时,将训练效率提高了20%以上,推理吞吐量提高了15%以上。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型中视觉编码器计算量大的问题,特别是现有Token压缩方法主要集中在编码器之后,无法充分利用中间层的信息和计算资源。现有方法的痛点在于压缩位置的局限性,导致效率提升受限。
核心思路:论文的核心思路是在视觉编码器的中间层进行Token压缩,从而更早地减少计算量,提升整体效率。通过设计特定的压缩机制,在保证视觉信息不丢失的前提下,减少Token数量。这样可以使得后续的计算都在更少的Token上进行,从而加速训练和推理。
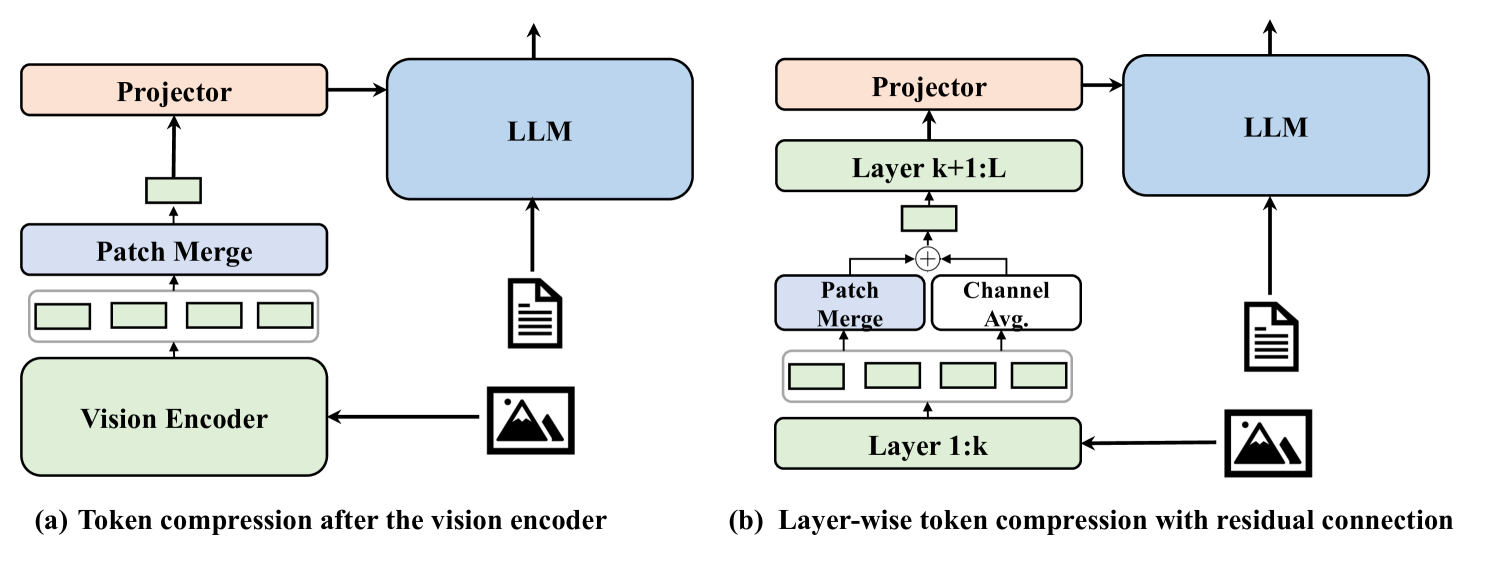
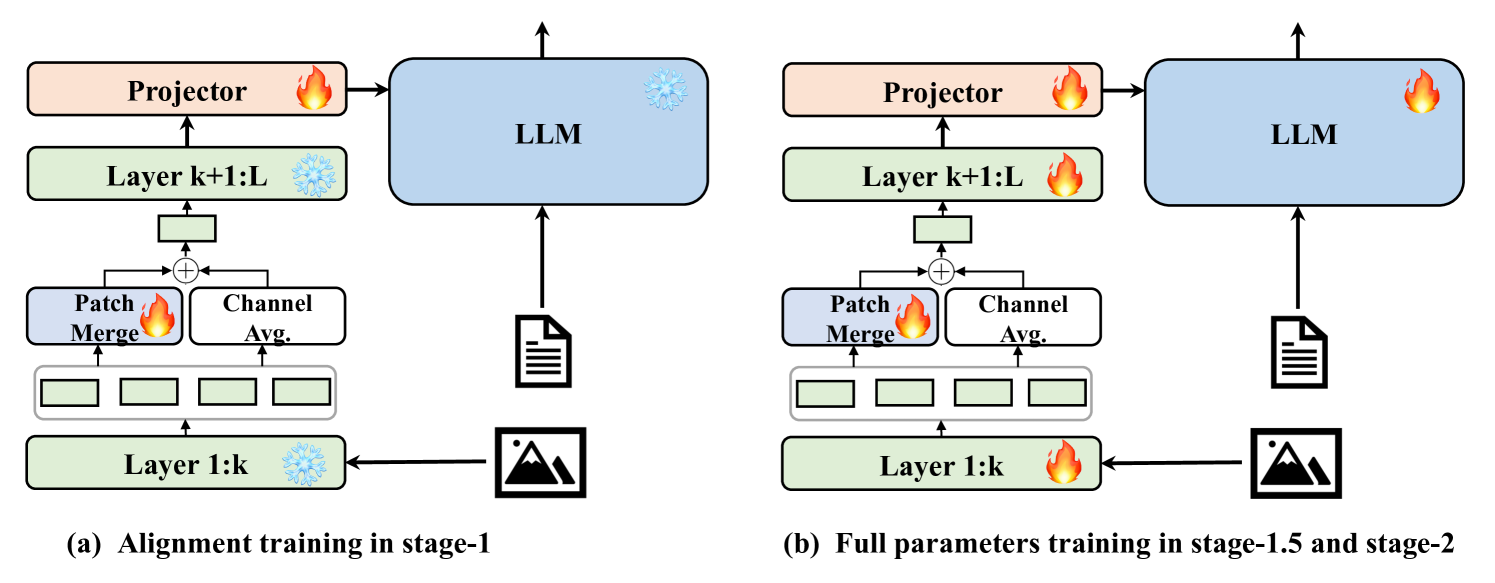
技术框架:LaCo框架主要包含两个核心模块:层间像素重组(Layer-wise Pixel-Shuffle)和残差学习架构。层间像素重组负责在每一层将相邻的Token合并,减少Token数量。残差学习架构则通过非参数捷径,保留压缩过程中可能丢失的关键视觉信息。整体流程是在视觉编码器的每一层,先进行像素重组压缩Token,然后通过残差学习进行信息补偿,最后将压缩后的Token传递到下一层。
关键创新:LaCo的关键创新在于将Token压缩操作融入到视觉编码器的中间层,而不是仅仅作为后处理步骤。这种层间压缩的方式可以更早地减少计算量,从而带来更大的效率提升。此外,像素重组和残差学习的结合,保证了压缩过程中的信息损失最小化。
关键设计:层间像素重组采用空间到通道的转换,将相邻的Token在空间维度上合并,并在通道维度上扩展。残差学习架构使用非参数捷径,直接将原始的Token信息添加到压缩后的Token信息中,避免引入额外的参数。具体的压缩比例和残差连接的权重等参数需要根据具体的任务和数据集进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LaCo在视觉编码器的中间层压缩Token时,性能优于所有现有方法。与外部压缩相比,LaCo将训练效率提高了20%以上,推理吞吐量提高了15%以上,同时保持了强大的性能。这些结果证明了LaCo在多模态大语言模型Token压缩方面的有效性和优越性。
🎯 应用场景
LaCo可应用于各种多模态大语言模型,尤其是在资源受限的场景下,如移动设备或边缘计算平台。通过高效的Token压缩,LaCo可以降低计算成本,提高推理速度,从而使得多模态大语言模型能够在更广泛的场景中部署和应用。未来,LaCo还可以与其他模型压缩技术相结合,进一步提升效率。
📄 摘要(原文)
Existing visual token compression methods for Multimodal Large Language Models (MLLMs) predominantly operate as post-encoder modules, limiting their potential for efficiency gains. To address this limitation, we propose LaCo (Layer-wise Visual Token Compression), a novel framework that enables effective token compression within the intermediate layers of the vision encoder. LaCo introduces two core components: 1) a layer-wise pixel-shuffle mechanism that systematically merges adjacent tokens through space-to-channel transformations, and 2) a residual learning architecture with non-parametric shortcuts that preserves critical visual information during compression. Extensive experiments indicate that our LaCo outperforms all existing methods when compressing tokens in the intermediate layers of the vision encoder, demonstrating superior effectiveness. In addition, compared to external compression, our method improves training efficiency beyond 20% and inference throughput over 15% while maintaining strong performance.