Team RAS in 9th ABAW Competition: Multimodal Compound Expression Recognition Approach
作者: Elena Ryumina, Maxim Markitantov, Alexandr Axyonov, Dmitry Ryumin, Mikhail Dolgushin, Alexey Karpov
分类: cs.CV
发布日期: 2025-07-02 (更新: 2025-07-04)
备注: 7
💡 一句话要点
提出一种零样本多模态复合表情识别方法,无需目标数据训练即可实现高性能。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 复合表情识别 零样本学习 多模态融合 CLIP Qwen-VL 情感计算 人机交互
📋 核心要点
- 现有复合表情识别方法依赖于特定任务的训练数据,泛化能力受限,难以适应新的场景和数据集。
- 该论文提出一种零样本多模态融合方法,利用CLIP和Qwen-VL等预训练模型,结合多种模态信息进行复合表情识别。
- 实验结果表明,该方法在多个数据集上取得了与监督方法相当的性能,验证了其在零样本场景下的有效性。
📝 摘要(中文)
本研究提出了一种新颖的零样本多模态方法,用于复合表情识别(CER),旨在检测由基本情绪组合而成的复杂情绪状态。该方法将六种异构模态整合到一个统一的流程中,包括静态和动态面部表情、场景和标签匹配、场景上下文、音频和文本。与以往依赖于特定任务训练数据的方法不同,我们的方法采用零样本组件,包括基于对比语言-图像预训练(CLIP)的标签匹配和用于语义场景理解的Qwen-VL。此外,我们引入了一个多头概率融合(MHPF)模块,该模块动态地加权特定模态的预测,然后是一个复合表情(CE)转换模块,该模块使用成对概率聚合(PPA)和成对特征相似性聚合(PFSA)方法来产生可解释的复合情绪输出。在多语料库训练下评估,所提出的方法通过零样本测试在AffWild2上显示出46.95%的F1分数,在Acted Facial Expressions in The Wild (AFEW)上显示出49.02%的F1分数,在C-EXPR-DB上显示出34.85%的F1分数,这与在目标数据上训练的监督方法的结果相当。这证明了所提出的方法在无需领域自适应的情况下捕获CE的有效性。源代码已公开。
🔬 方法详解
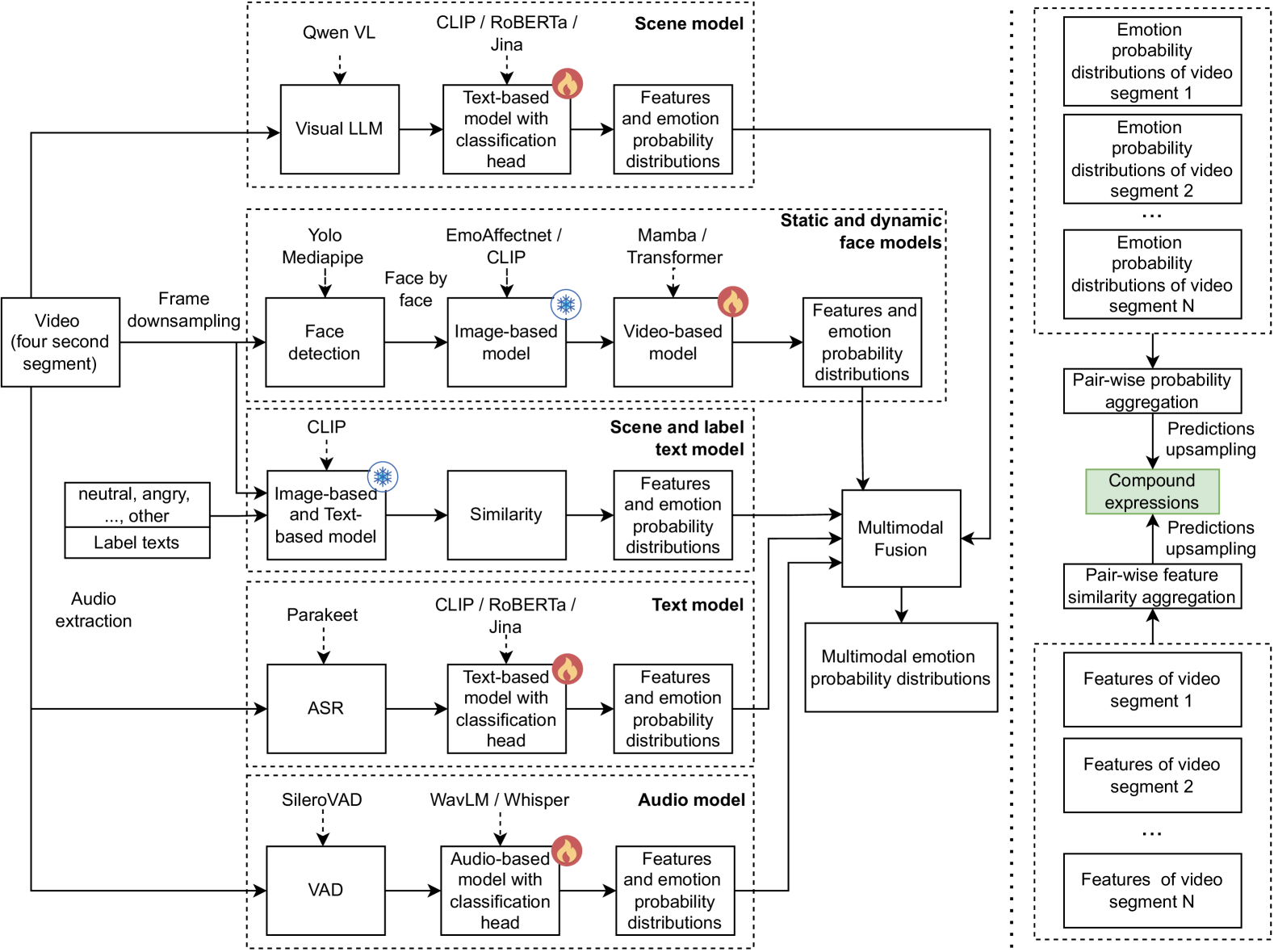
问题定义:复合表情识别旨在识别由多种基本情绪组合而成的复杂情绪状态。现有方法通常需要大量特定任务的标注数据进行训练,这限制了它们在实际应用中的泛化能力,尤其是在缺乏标注数据的新场景下表现不佳。
核心思路:该论文的核心思路是利用预训练的多模态模型,例如CLIP和Qwen-VL,以及多模态融合策略,构建一个零样本的复合表情识别系统。通过将不同模态的信息进行有效整合,并利用预训练模型强大的语义理解能力,从而在没有目标数据训练的情况下也能实现较好的识别效果。
技术框架:该方法包含以下主要模块:1) 多模态特征提取:分别从静态和动态面部表情、场景、音频和文本中提取特征。2) 零样本组件:利用CLIP进行标签匹配,利用Qwen-VL进行场景理解。3) 多头概率融合(MHPF):动态地加权不同模态的预测结果。4) 复合表情(CE)转换:使用成对概率聚合(PPA)和成对特征相似性聚合(PFSA)方法生成最终的复合表情输出。
关键创新:该方法最重要的创新点在于其零样本特性,即无需在目标数据集上进行训练即可实现高性能的复合表情识别。这得益于CLIP和Qwen-VL等预训练模型的强大泛化能力,以及多模态融合策略的有效性。与传统方法相比,该方法避免了对大量标注数据的依赖,大大降低了应用成本。
关键设计:MHPF模块通过学习不同模态的权重,动态地调整它们对最终预测结果的贡献。CE转换模块利用PPA和PFSA方法,将不同基本情绪的概率和特征进行聚合,从而生成复合表情的表示。具体的权重学习方法和聚合策略的选择是影响最终性能的关键因素。
🖼️ 关键图片
📊 实验亮点
该方法在AffWild2、AFEW和C-EXPR-DB三个数据集上进行了零样本测试,分别取得了46.95%、49.02%和34.85%的F1分数。这些结果与在目标数据上训练的监督方法的结果相当,证明了该方法在零样本场景下的有效性。尤其是在缺乏标注数据的场景下,该方法的优势更加明显。
🎯 应用场景
该研究成果可应用于人机交互、情感计算、心理健康评估等领域。例如,在智能客服中,可以利用该技术识别用户的情绪状态,从而提供更个性化的服务。在心理健康领域,可以辅助医生进行情绪评估和诊断。此外,该技术还可以应用于社交媒体分析、舆情监控等场景。
📄 摘要(原文)
Compound Expression Recognition (CER), a subfield of affective computing, aims to detect complex emotional states formed by combinations of basic emotions. In this work, we present a novel zero-shot multimodal approach for CER that combines six heterogeneous modalities into a single pipeline: static and dynamic facial expressions, scene and label matching, scene context, audio, and text. Unlike previous approaches relying on task-specific training data, our approach uses zero-shot components, including Contrastive Language-Image Pretraining (CLIP)-based label matching and Qwen-VL for semantic scene understanding. We further introduce a Multi-Head Probability Fusion (MHPF) module that dynamically weights modality-specific predictions, followed by a Compound Expressions (CE) transformation module that uses Pair-Wise Probability Aggregation (PPA) and Pair-Wise Feature Similarity Aggregation (PFSA) methods to produce interpretable compound emotion outputs. Evaluated under multi-corpus training, the proposed approach shows F1 scores of 46.95% on AffWild2, 49.02% on Acted Facial Expressions in The Wild (AFEW), and 34.85% on C-EXPR-DB via zero-shot testing, which is comparable to the results of supervised approaches trained on target data. This demonstrates the effectiveness of the proposed approach for capturing CE without domain adaptation. The source code is publicly available.