GaussianVLM: Scene-centric 3D Vision-Language Models using Language-aligned Gaussian Splats for Embodied Reasoning and Beyond
作者: Anna-Maria Halacheva, Jan-Nico Zaech, Xi Wang, Danda Pani Paudel, Luc Van Gool
分类: cs.CV, cs.RO
发布日期: 2025-07-01
💡 一句话要点
提出GaussianVLM,利用语言对齐的高斯溅射实现场景中心的三维视觉语言模型,用于具身推理等任务。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 三维视觉语言模型 高斯溅射 场景理解 具身推理 多模态学习
📋 核心要点
- 现有3D VLM严重依赖目标检测器,导致处理瓶颈和分类学灵活性受限。
- GaussianVLM通过将语言特征嵌入到高斯基元中,实现语言和任务感知的场景表示,从而进行早期模态对齐。
- 该模型在领域外设置中,相较于之前的3D VLM,性能提升了五倍,展示了强大的泛化能力。
📝 摘要(中文)
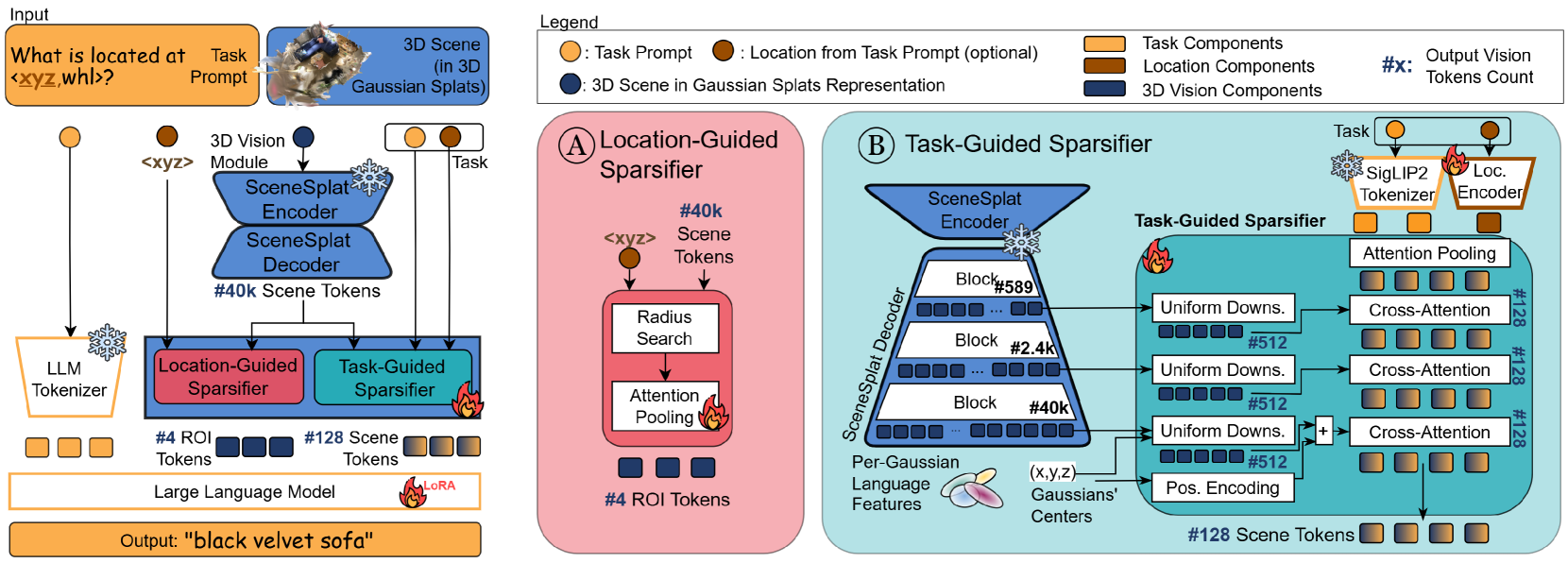
随着多模态语言模型的进步,其在三维场景理解中的应用正快速发展,推动了三维视觉语言模型(VLM)的发展。当前的方法严重依赖于目标检测器,这引入了处理瓶颈和分类学灵活性方面的限制。为了解决这些限制,我们提出了一种场景中心的三维VLM,用于三维高斯溅射场景,该模型采用语言和任务感知的场景表示。我们的方法通过将语言与每个高斯基元相关联,直接将丰富的语言特征嵌入到三维场景表示中,从而实现早期模态对齐。为了处理由此产生的密集表示,我们引入了一个双重稀疏器,通过任务引导和位置引导的路径将其提炼成紧凑的、任务相关的token,从而产生稀疏的、任务感知的全局和局部场景token。值得注意的是,我们提出了第一个基于高斯溅射的VLM,利用从标准RGB图像导出的逼真三维表示,展示了强大的泛化能力:在领域外设置中,它将先前三维VLM的性能提高了五倍。
🔬 方法详解
问题定义:现有3D视觉语言模型(VLM)严重依赖于2D目标检测器,这导致了两个主要问题。首先,目标检测器本身可能存在性能瓶颈,限制了整体系统的速度和准确性。其次,目标检测器的分类体系限制了VLM的灵活性,使其难以处理未在预定义类别中出现的对象或概念。因此,需要一种更灵活、更高效的3D VLM,能够直接从3D场景表示中提取信息,而无需依赖中间的目标检测步骤。
核心思路:GaussianVLM的核心思路是利用3D高斯溅射(Gaussian Splatting)作为场景的底层表示,并将语言信息直接嵌入到这些高斯基元中。通过将每个高斯基元与语言特征相关联,模型能够建立场景中每个位置的语义理解,从而实现更细粒度的场景理解和推理。这种方法避免了对目标检测器的依赖,提高了模型的灵活性和效率。
技术框架:GaussianVLM的整体框架包括以下几个主要模块:1) 高斯溅射场景表示:使用3D高斯溅射来表示3D场景,每个高斯基元包含位置、颜色、不透明度等属性。2) 语言嵌入模块:将输入的语言查询嵌入到高维向量空间中。3) 语言对齐模块:将语言嵌入与每个高斯基元相关联,从而将语言信息注入到3D场景表示中。4) 双重稀疏器:通过任务引导和位置引导的路径,将密集的场景表示提炼成稀疏的、任务相关的token。5) 推理模块:利用稀疏的token进行下游任务的推理,例如视觉问答、场景导航等。
关键创新:GaussianVLM的关键创新在于其场景中心的表示方法,以及将语言信息直接嵌入到高斯基元中的策略。与以往依赖目标检测器的VLM不同,GaussianVLM能够直接从3D场景表示中提取信息,从而避免了目标检测器的瓶颈和限制。此外,双重稀疏器的设计能够有效地处理高斯溅射产生的密集表示,提取出任务相关的关键信息。
关键设计:在语言对齐模块中,可以使用注意力机制来确定每个高斯基元与语言查询的相关性,从而实现更精确的语言嵌入。双重稀疏器可以采用Transformer架构,利用自注意力机制来提取全局和局部场景token。损失函数可以包括对比损失,以鼓励相似的场景和语言嵌入具有更接近的表示,以及任务相关的损失函数,以优化下游任务的性能。
🖼️ 关键图片


📊 实验亮点
GaussianVLM在领域外设置中,相较于之前的3D VLM,性能提升了五倍。这一显著的提升表明了GaussianVLM具有强大的泛化能力,能够有效地处理各种不同的3D场景和语言查询。该模型在视觉问答、场景导航等任务上均取得了优异的性能,证明了其在3D场景理解方面的有效性。
🎯 应用场景
GaussianVLM在具身智能、机器人导航、虚拟现实和增强现实等领域具有广泛的应用前景。它可以用于开发更智能的机器人,使其能够理解人类的指令,并在复杂的3D环境中进行导航和交互。此外,GaussianVLM还可以用于创建更逼真的虚拟现实和增强现实体验,使用户能够与虚拟环境进行更自然的交互。
📄 摘要(原文)
As multimodal language models advance, their application to 3D scene understanding is a fast-growing frontier, driving the development of 3D Vision-Language Models (VLMs). Current methods show strong dependence on object detectors, introducing processing bottlenecks and limitations in taxonomic flexibility. To address these limitations, we propose a scene-centric 3D VLM for 3D Gaussian splat scenes that employs language- and task-aware scene representations. Our approach directly embeds rich linguistic features into the 3D scene representation by associating language with each Gaussian primitive, achieving early modality alignment. To process the resulting dense representations, we introduce a dual sparsifier that distills them into compact, task-relevant tokens via task-guided and location-guided pathways, producing sparse, task-aware global and local scene tokens. Notably, we present the first Gaussian splatting-based VLM, leveraging photorealistic 3D representations derived from standard RGB images, demonstrating strong generalization: it improves performance of prior 3D VLM five folds, in out-of-the-domain settings.