Multi-Modal Graph Convolutional Network with Sinusoidal Encoding for Robust Human Action Segmentation
作者: Hao Xing, Kai Zhe Boey, Yuankai Wu, Darius Burschka, Gordon Cheng
分类: cs.CV, cs.RO
发布日期: 2025-07-01 (更新: 2025-12-11)
备注: 8 pages, 5 figures, accepted in IROS25, Hangzhou, China
DOI: 10.1109/IROS60139.2025.11245867
💡 一句话要点
提出基于正弦编码的多模态图卷积网络,提升人机协作中动作分割的鲁棒性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱五:交互与反应 (Interaction & Reaction)
关键词: 多模态融合 图卷积网络 动作分割 人机协作 正弦编码 数据增强 时间建模
📋 核心要点
- 现有方法易受姿态估计和物体检测噪声影响,导致动作序列过度分割,影响人机协作。
- 提出MMGCN,利用正弦编码增强骨骼空间表征,时间图融合对齐多模态数据,SmoothLabelMix增强时间一致性。
- 在Bimanual Actions Dataset上,该方法显著提升了动作分割精度,F1@10达到94.5%,F1@25达到92.8%。
📝 摘要(中文)
本文提出了一种多模态图卷积网络(MMGCN),用于解决人机协作场景中精确的人类动作时序分割问题。该方法融合了低帧率的视觉数据(例如1fps)和高帧率的运动数据(例如30fps,包括骨骼和物体检测),以减轻动作序列的过度分割问题。主要贡献包括:正弦编码策略,将3D骨骼坐标映射到连续的sin-cos空间,增强空间表征的鲁棒性;时间图融合模块,通过分层特征聚合对齐不同分辨率的多模态输入;SmoothLabelMix数据增强技术,通过混合输入序列和标签生成具有平滑动作过渡的合成训练样本,增强预测的时间一致性,减少过度分割。在Bimanual Actions Dataset上的实验表明,该方法优于现有技术,尤其是在动作分割精度方面,F1@10达到94.5%,F1@25达到92.8%。
🔬 方法详解
问题定义:论文旨在解决人机协作场景中,由于人体姿态估计和物体检测的噪声,导致动作序列过度分割的问题。现有的动作分割方法容易受到这些噪声的影响,从而降低了动作分割的准确性和鲁棒性。
核心思路:论文的核心思路是融合低帧率的视觉信息和高帧率的运动信息,并利用图卷积网络学习动作的时序关系。通过正弦编码增强骨骼数据的空间表征,并设计时间图融合模块来对齐不同模态的数据。此外,SmoothLabelMix数据增强技术用于提高模型的时间一致性。
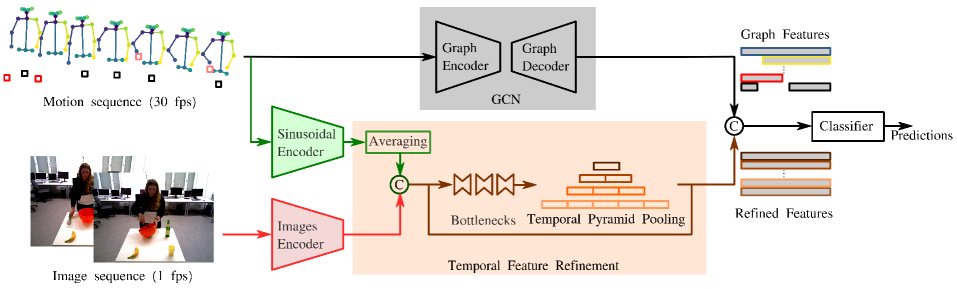
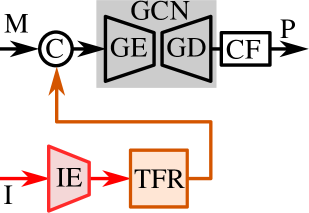
技术框架:MMGCN框架包含以下几个主要模块:1) 特征提取模块:分别提取视觉数据、骨骼数据和物体检测数据的特征。2) 正弦编码模块:将3D骨骼坐标编码到正弦空间。3) 时间图融合模块:将不同模态的特征进行对齐和融合。4) 图卷积网络:学习动作的时序关系。5) 分类器:预测每个时间步的动作标签。
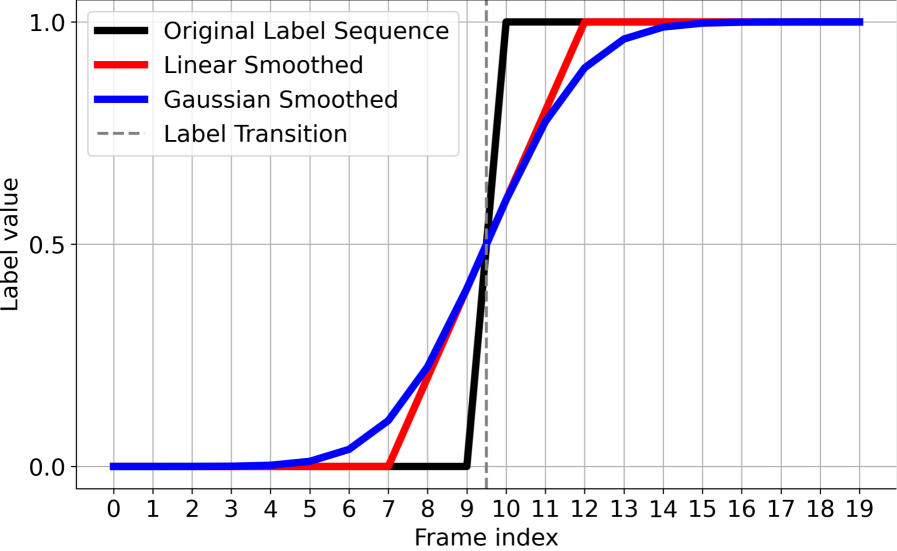
关键创新:论文的关键创新在于:1) 提出了正弦编码策略,增强了骨骼数据的空间表征鲁棒性。2) 设计了时间图融合模块,能够有效地对齐和融合不同分辨率的多模态数据。3) 提出了SmoothLabelMix数据增强技术,提高了模型的时间一致性,减少了过度分割。
关键设计:正弦编码将每个3D骨骼坐标x映射为(sin(ωx), cos(ωx)),其中ω是频率参数。时间图融合模块采用分层特征聚合的方式,逐步融合不同模态的特征。SmoothLabelMix通过线性插值的方式混合输入序列和标签,生成新的训练样本。损失函数采用交叉熵损失。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MMGCN在Bimanual Actions Dataset上取得了显著的性能提升。在F1@10指标上,MMGCN达到了94.5%,在F1@25指标上达到了92.8%,显著优于现有的state-of-the-art方法。消融实验验证了正弦编码、时间图融合和SmoothLabelMix等模块的有效性。
🎯 应用场景
该研究成果可应用于多种人机协作场景,例如:智能制造、康复机器人、辅助生活等。通过准确分割人类动作,机器人能够更好地理解人类意图,从而实现更安全、高效的协作。该技术还有潜力应用于视频监控、行为分析等领域。
📄 摘要(原文)
Accurate temporal segmentation of human actions is critical for intelligent robots in collaborative settings, where a precise understanding of sub-activity labels and their temporal structure is essential. However, the inherent noise in both human pose estimation and object detection often leads to over-segmentation errors, disrupting the coherence of action sequences. To address this, we propose a Multi-Modal Graph Convolutional Network (MMGCN) that integrates low-frame-rate (e.g., 1 fps) visual data with high-frame-rate (e.g., 30 fps) motion data (skeleton and object detections) to mitigate fragmentation. Our framework introduces three key contributions. First, a sinusoidal encoding strategy that maps 3D skeleton coordinates into a continuous sin-cos space to enhance spatial representation robustness. Second, a temporal graph fusion module that aligns multi-modal inputs with differing resolutions via hierarchical feature aggregation, Third, inspired by the smooth transitions inherent to human actions, we design SmoothLabelMix, a data augmentation technique that mixes input sequences and labels to generate synthetic training examples with gradual action transitions, enhancing temporal consistency in predictions and reducing over-segmentation artifacts. Extensive experiments on the Bimanual Actions Dataset, a public benchmark for human-object interaction understanding, demonstrate that our approach outperforms state-of-the-art methods, especially in action segmentation accuracy, achieving F1@10: 94.5% and F1@25: 92.8%.