ActAlign: Zero-Shot Fine-Grained Video Classification via Language-Guided Sequence Alignment
作者: Amir Aghdam, Vincent Tao Hu, Björn Ommer
分类: cs.CV, cs.LG, cs.MM
发布日期: 2025-06-28 (更新: 2025-10-19)
备注: Accepted to TMLR 2025 - Project page: https://amir-aghdam.github.io/act-align/
💡 一句话要点
ActAlign:通过语言引导的序列对齐实现零样本细粒度视频分类
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 视频分类 细粒度动作识别 序列对齐 动态时间规整
📋 核心要点
- 现有方法在细粒度视频分类中缺乏对时序信息的有效建模,限制了其在零样本场景下的泛化能力。
- ActAlign利用大型语言模型生成子动作序列,并通过动态时间规整与视频帧对齐,实现零样本分类。
- 实验表明,ActAlign在ActionAtlas数据集上显著优于现有方法,且参数量更少,展现了其优越性。
📝 摘要(中文)
本文提出了一种针对极细粒度动作(例如篮球中的风车灌篮)的零样本视频分类方法,其中对于未见过的类别,没有可用的视频示例或时间注释。虽然图像-语言模型(例如CLIP,SigLIP)显示出强大的开放集识别能力,但它们缺乏视频理解所需的时间建模能力。我们提出了ActAlign,这是一种真正的零样本、免训练方法,它将视频分类公式化为一个序列对齐问题,保留了预训练图像-语言模型的泛化能力。对于每个类别,大型语言模型(LLM)生成一个有序的子动作序列,我们使用动态时间规整(DTW)在共享嵌入空间中将其与视频帧对齐。在没有任何视频-文本监督或微调的情况下,ActAlign在ActionAtlas(跨多个体育项目的最多样化的细粒度动作基准)上实现了30.5%的准确率,而人类的表现仅为61.6%。ActAlign优于数十亿参数的视频-语言模型,同时使用的参数减少了8倍。我们的方法是模型无关且领域通用的,证明了结构化语言先验与经典对齐方法相结合可以释放图像-语言模型在细粒度视频理解中的开放集识别潜力。
🔬 方法详解
问题定义:论文旨在解决极细粒度动作的零样本视频分类问题。现有方法,特别是图像-语言模型,虽然在开放集识别方面表现出色,但缺乏对视频时序信息的有效建模,导致在细粒度动作识别上性能受限。此外,现有方法通常需要大量的视频-文本监督或微调,难以适应零样本场景。
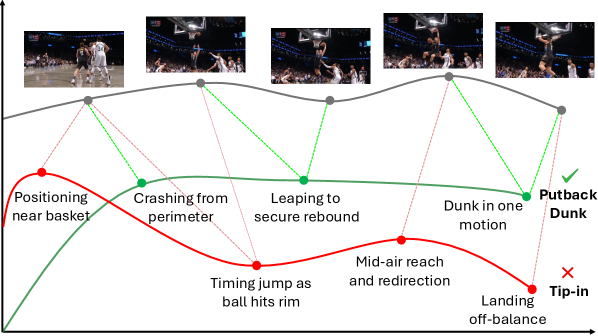
核心思路:ActAlign的核心思路是将视频分类问题转化为一个序列对齐问题。它利用大型语言模型(LLM)生成每个类别动作的子动作序列,然后使用动态时间规整(DTW)算法将这些子动作序列与视频帧进行对齐。通过在共享嵌入空间中寻找最佳对齐方式,实现对视频动作的分类。这种方法充分利用了LLM的语言理解能力和DTW的时序对齐能力,从而在零样本场景下实现了有效的细粒度视频分类。
技术框架:ActAlign的整体框架包括以下几个主要模块:1) LLM子动作生成器:使用大型语言模型为每个动作类别生成一个有序的子动作序列。2) 视频帧特征提取器:使用预训练的图像-语言模型(如CLIP或SigLIP)提取视频帧的视觉特征。3) 共享嵌入空间:将LLM生成的子动作序列和视频帧的视觉特征投影到同一个嵌入空间中。4) 动态时间规整(DTW)对齐:使用DTW算法在共享嵌入空间中将子动作序列与视频帧进行对齐,计算对齐得分。5) 分类器:根据DTW对齐得分,将视频分类到得分最高的动作类别。
关键创新:ActAlign的关键创新在于其将视频分类问题转化为序列对齐问题,并利用LLM生成结构化的语言先验信息。与传统的视频分类方法相比,ActAlign无需视频-文本监督或微调,即可在零样本场景下实现细粒度动作识别。此外,ActAlign的方法是模型无关的,可以与不同的图像-语言模型和LLM结合使用。
关键设计:ActAlign的关键设计包括:1) 使用LLM生成子动作序列,为视频分类提供结构化的语言先验信息。2) 使用动态时间规整(DTW)算法进行序列对齐,有效处理视频中的时间变化和噪声。3) 在共享嵌入空间中进行对齐,使得视觉特征和语言特征可以进行有效的比较和匹配。4) 使用预训练的图像-语言模型提取视频帧特征,充分利用了预训练模型的泛化能力。
🖼️ 关键图片


📊 实验亮点
ActAlign在ActionAtlas数据集上取得了30.5%的准确率,显著优于现有的零样本视频分类方法。值得注意的是,ActAlign在没有任何视频-文本监督或微调的情况下,超越了参数量更大的视频-语言模型,并且使用了8倍更少的参数。这表明ActAlign在零样本细粒度视频分类方面具有很强的竞争力。
🎯 应用场景
ActAlign在体育分析、视频监控、机器人动作识别等领域具有广泛的应用前景。例如,可以用于自动识别体育赛事中的特定动作,帮助教练员进行战术分析;也可以用于监控视频中的异常行为检测,提高安全性;还可以用于机器人学习,使机器人能够理解和执行复杂的动作。
📄 摘要(原文)
We address the task of zero-shot video classification for extremely fine-grained actions (e.g., Windmill Dunk in basketball), where no video examples or temporal annotations are available for unseen classes. While image-language models (e.g., CLIP, SigLIP) show strong open-set recognition, they lack temporal modeling needed for video understanding. We propose ActAlign, a truly zero-shot, training-free method that formulates video classification as a sequence alignment problem, preserving the generalization strength of pretrained image-language models. For each class, a large language model (LLM) generates an ordered sequence of sub-actions, which we align with video frames using Dynamic Time Warping (DTW) in a shared embedding space. Without any video-text supervision or fine-tuning, ActAlign achieves 30.5% accuracy on ActionAtlas--the most diverse benchmark of fine-grained actions across multiple sports--where human performance is only 61.6%. ActAlign outperforms billion-parameter video-language models while using 8x fewer parameters. Our approach is model-agnostic and domain-general, demonstrating that structured language priors combined with classical alignment methods can unlock the open-set recognition potential of image-language models for fine-grained video understanding.