MOTOR: Multimodal Optimal Transport via Grounded Retrieval in Medical Visual Question Answering
作者: Mai A. Shaaban, Tausifa Jan Saleem, Vijay Ram Papineni, Mohammad Yaqub
分类: cs.CV, cs.CL
发布日期: 2025-06-28
DOI: 10.1007/978-3-032-04978-0_44
🔗 代码/项目: GITHUB
💡 一句话要点
提出MOTOR,一种基于多模态最优传输的医学视觉问答方法,提升临床相关性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学视觉问答 多模态融合 最优传输 检索增强生成 临床决策支持
📋 核心要点
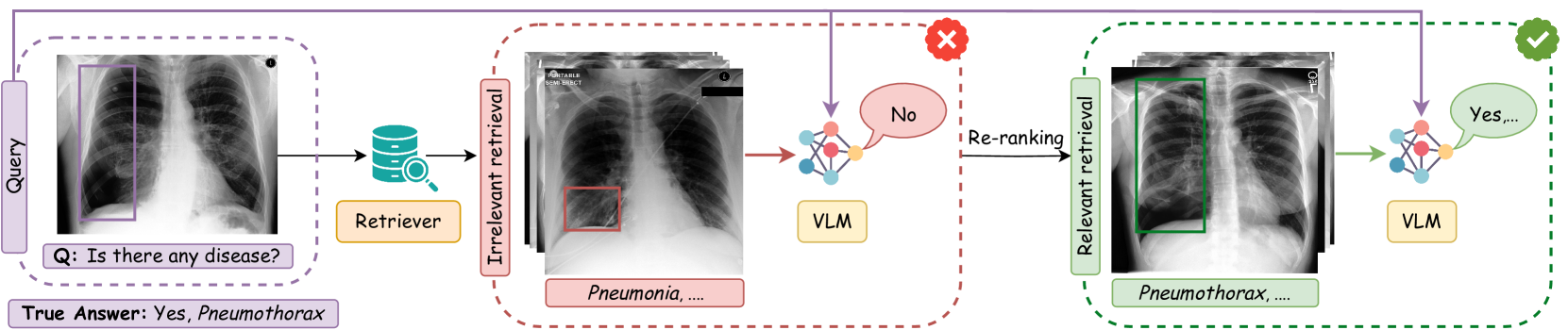
- 现有MedVQA方法依赖视觉-语言模型,但常产生不准确答案,检索增强方法易引入无关信息。
- MOTOR利用图像标题和最优传输,在多模态上下文中对检索结果进行重排序,提升临床相关性。
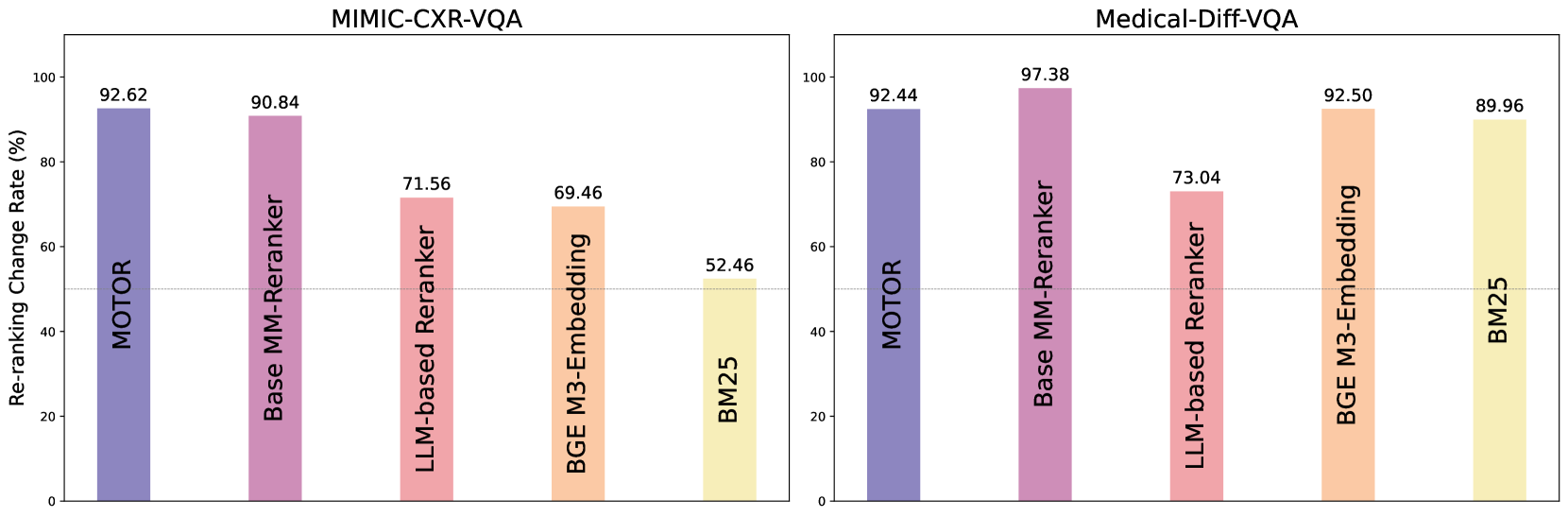
- 实验表明,MOTOR在MedVQA数据集上显著优于现有方法,平均准确率提升6.45%。
📝 摘要(中文)
医学视觉问答(MedVQA)通过为基于图像的查询提供上下文丰富的答案,在临床决策中起着至关重要的作用。尽管视觉-语言模型(VLM)被广泛用于此任务,但它们经常生成不符合事实的答案。检索增强生成通过提供来自外部来源的信息来解决这一挑战,但存在检索到不相关上下文的风险,这会降低VLM的推理能力。现有方法中引入的重排序检索通过关注查询-文本对齐来增强检索相关性。然而,这些方法忽略了视觉或多模态上下文,这对于医学诊断尤为重要。我们提出了一种新颖的多模态检索和重排序方法MOTOR,它利用了基于图像的标题和最优传输。它捕获了查询和检索到的上下文之间基于文本和视觉信息的潜在关系。因此,我们的方法识别出更多临床相关的上下文来增强VLM输入。实证分析和人类专家评估表明,MOTOR在MedVQA数据集上实现了更高的准确率,优于最先进的方法,平均提高了6.45%。
🔬 方法详解
问题定义:医学视觉问答(MedVQA)旨在根据医学图像回答相关问题。现有方法,特别是基于检索增强的VLM,容易受到检索到的上下文信息不相关的影响,导致模型产生错误的答案。现有的重排序方法主要关注文本层面的相关性,忽略了视觉信息的重要性,这在医学图像分析中至关重要。
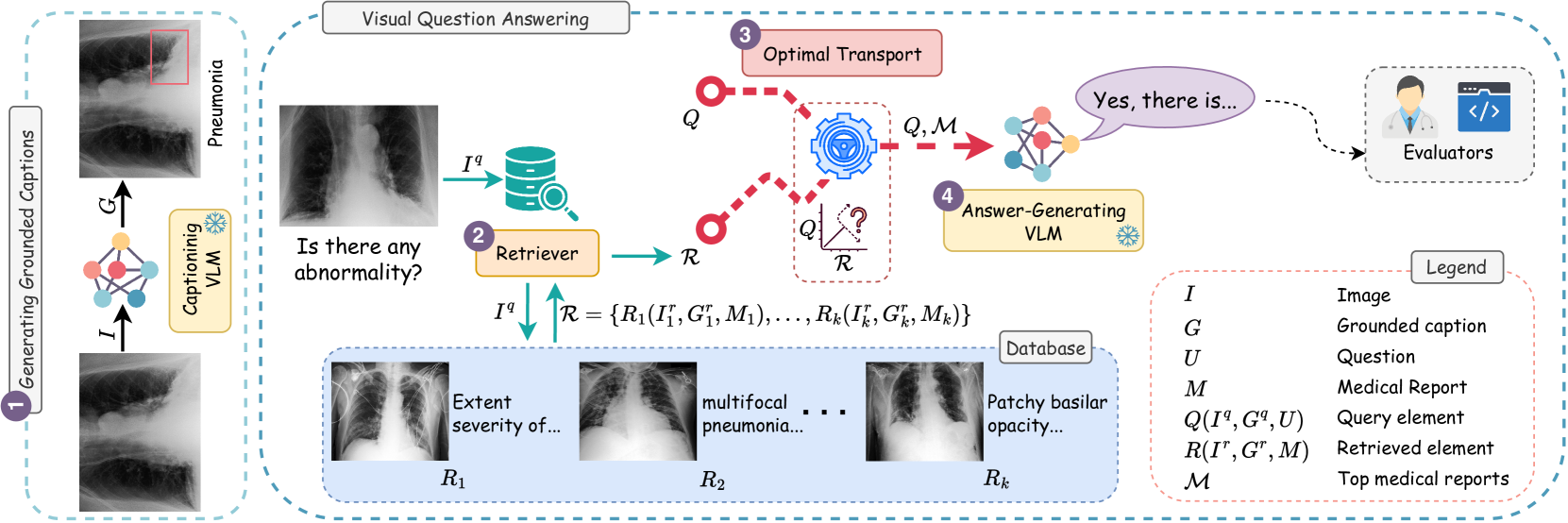
核心思路:MOTOR的核心思路是利用多模态信息(文本和视觉)来更准确地评估检索到的上下文与问题的相关性。通过引入基于图像的标题,并使用最优传输来建模查询和检索上下文之间的关系,从而选择更具临床意义的上下文来增强VLM的输入。
技术框架:MOTOR的整体框架包括以下几个主要模块:1) 初始检索:使用传统的文本检索方法从外部知识库中检索候选上下文。2) 图像标题生成:为医学图像生成描述性标题,以提供视觉信息。3) 多模态对齐:利用最优传输算法,将查询、检索到的文本上下文和图像标题进行对齐,计算它们之间的相似度。4) 重排序:根据多模态对齐的结果,对检索到的上下文进行重排序,选择最相关的上下文。5) VLM集成:将重排序后的上下文输入到VLM中,生成最终答案。
关键创新:MOTOR的关键创新在于其多模态检索和重排序方法。它不仅考虑了查询和文本上下文之间的相关性,还考虑了视觉信息,从而更准确地评估了检索到的上下文的临床相关性。此外,使用最优传输来建模多模态信息之间的关系,能够有效地捕捉它们之间的复杂依赖关系。
关键设计:在多模态对齐阶段,使用预训练的视觉模型(如ResNet或ViT)提取图像特征,并使用预训练的语言模型(如BERT或RoBERTa)提取文本特征。最优传输的代价矩阵可以根据文本和视觉特征之间的余弦相似度来构建。损失函数的设计目标是最小化查询、检索到的上下文和图像标题之间的距离,同时最大化它们之间的互信息。
🖼️ 关键图片
📊 实验亮点
MOTOR在多个MedVQA数据集上取得了显著的性能提升,平均超过现有最先进方法6.45%。人类专家评估也表明,MOTOR选择的上下文信息更具临床相关性,生成的答案更准确。这些结果表明,MOTOR在医学视觉问答领域具有很强的竞争力。
🎯 应用场景
MOTOR在医学视觉问答领域具有广泛的应用前景,可以辅助医生进行诊断和治疗决策。通过提供更准确、更相关的上下文信息,可以提高VLM的推理能力,减少错误诊断的风险。此外,该方法还可以应用于其他需要多模态信息融合的场景,如智能客服、教育等。
📄 摘要(原文)
Medical visual question answering (MedVQA) plays a vital role in clinical decision-making by providing contextually rich answers to image-based queries. Although vision-language models (VLMs) are widely used for this task, they often generate factually incorrect answers. Retrieval-augmented generation addresses this challenge by providing information from external sources, but risks retrieving irrelevant context, which can degrade the reasoning capabilities of VLMs. Re-ranking retrievals, as introduced in existing approaches, enhances retrieval relevance by focusing on query-text alignment. However, these approaches neglect the visual or multimodal context, which is particularly crucial for medical diagnosis. We propose MOTOR, a novel multimodal retrieval and re-ranking approach that leverages grounded captions and optimal transport. It captures the underlying relationships between the query and the retrieved context based on textual and visual information. Consequently, our approach identifies more clinically relevant contexts to augment the VLM input. Empirical analysis and human expert evaluation demonstrate that MOTOR achieves higher accuracy on MedVQA datasets, outperforming state-of-the-art methods by an average of 6.45%. Code is available at https://github.com/BioMedIA-MBZUAI/MOTOR.