Can Generated Images Serve as a Viable Modality for Text-Centric Multimodal Learning?
作者: Yuesheng Huang, Peng Zhang, Riliang Liu, Jiaqi Liang
分类: cs.MM, cs.CV
发布日期: 2025-06-21
备注: 4 figures,7 tables
💡 一句话要点
研究利用文本生成图像增强文本分类任务,探索合成感知在多模态学习中的可行性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本分类 多模态学习 文本生成图像 合成感知 提示工程
📋 核心要点
- 现有方法缺乏有效利用文本以外模态信息的能力,限制了文本理解任务的性能。
- 论文提出利用文本生成图像(T2I)模型,为文本分类任务引入合成图像模态,增强模型对文本的理解。
- 实验表明,该方法在特定条件下可以显著提升文本分类性能,但效果受多种因素影响。
📝 摘要(中文)
本文系统性地研究了文本到图像(T2I)模型即时生成的图像,是否可以作为以文本为中心的多模态任务的有价值的补充模态。通过在文本分类上的综合评估框架,分析了关键变量的影响,包括T2I模型质量、提示工程策略和多模态融合架构。研究结果表明,即使在增强强大的大型语言模型基线时,这种“合成感知”也能产生显著的性能提升。然而,这种方法的有效性高度依赖于文本和生成图像之间的语义对齐、任务固有的“视觉可接地性”以及T2I模型的生成保真度。这项工作为这种范式建立了第一个严格的基准,清晰地分析了其潜力和当前局限性,并证明了其作为丰富传统单模态场景中语言理解的途径的可行性。
🔬 方法详解
问题定义:论文旨在解决文本分类任务中,由于缺乏视觉信息而导致的性能瓶颈问题。现有方法主要依赖于文本自身的信息,忽略了视觉信息可能提供的补充知识。这种信息缺失在某些需要一定“视觉可接地性”的任务中尤为明显。
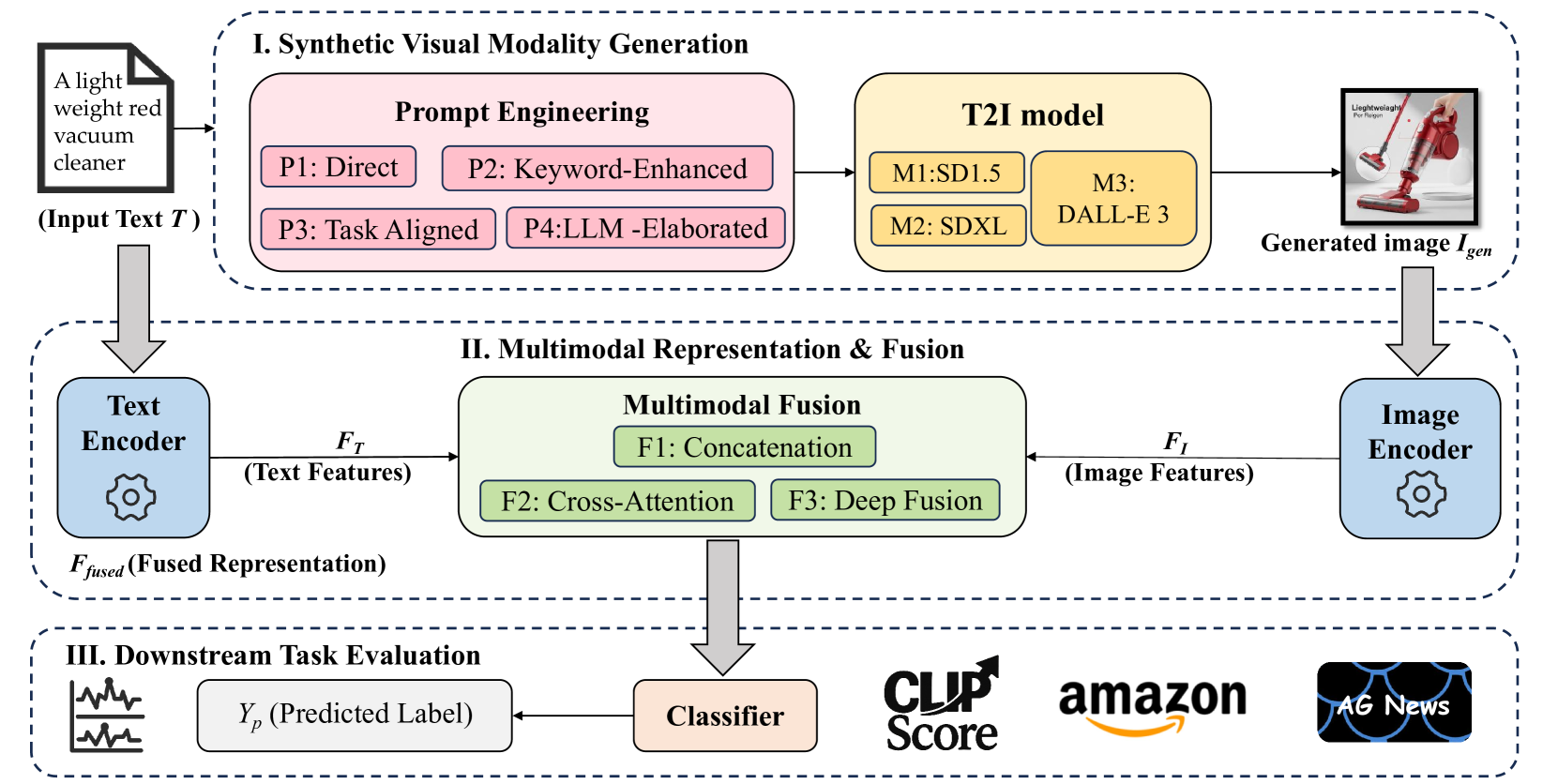
核心思路:论文的核心思路是利用文本生成图像(T2I)模型,根据文本描述生成对应的图像,从而为文本分类任务引入视觉模态的信息。通过将文本和生成的图像进行融合,模型可以学习到更丰富的特征表示,从而提升分类性能。这种方法的核心在于将单模态的文本分类问题转化为多模态的文本-图像分类问题。
技术框架:整体框架包含以下几个主要步骤:1) 输入文本;2) 使用T2I模型根据文本生成对应的图像;3) 使用文本编码器(如BERT)提取文本特征;4) 使用图像编码器(如ResNet)提取图像特征;5) 使用多模态融合模块将文本特征和图像特征进行融合;6) 使用分类器根据融合后的特征进行分类。
关键创新:论文的关键创新在于系统性地研究了利用T2I模型生成的图像作为文本分类任务的辅助模态的可行性。与以往主要关注真实图像的多模态学习不同,该研究探索了“合成感知”在文本理解中的潜力。此外,论文还对影响该方法性能的关键因素进行了深入分析,例如T2I模型质量、提示工程策略和多模态融合架构。
关键设计:论文的关键设计包括:1) 针对不同的文本分类任务,设计了合适的提示工程策略,以提高T2I模型生成图像的质量和语义相关性;2) 探索了不同的多模态融合架构,例如简单的拼接、注意力机制等,以有效地融合文本和图像特征;3) 对T2I模型的选择进行了实验,比较了不同模型的生成质量对最终分类性能的影响。
🖼️ 关键图片

📊 实验亮点
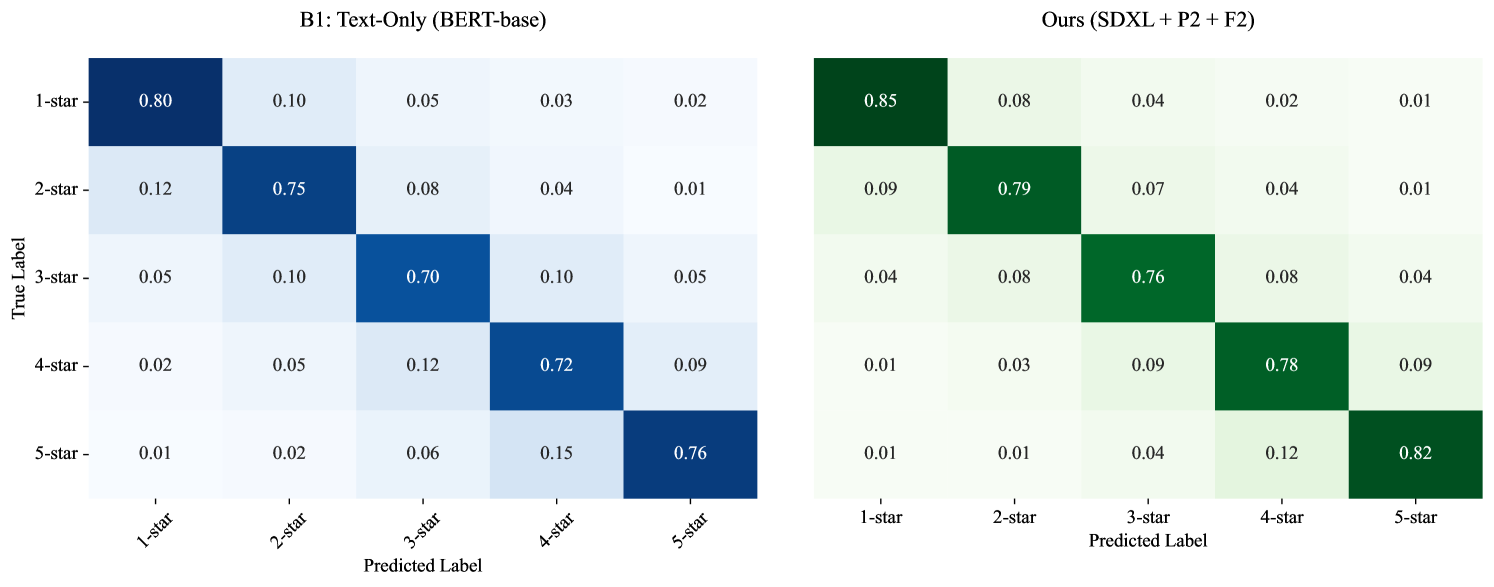
实验结果表明,在某些文本分类任务中,利用T2I模型生成的图像可以显著提升分类性能,甚至超过了强大的大型语言模型基线。例如,在具有较高“视觉可接地性”的任务中,性能提升尤为明显。此外,研究还发现,T2I模型的质量和提示工程策略对最终性能有重要影响。
🎯 应用场景
该研究成果可应用于多种文本理解场景,例如情感分析、主题分类、新闻分类等。通过引入合成图像模态,可以提升模型在缺乏视觉信息的场景下的性能。此外,该研究也为利用生成模型增强其他模态学习任务提供了新的思路,例如利用文本生成音频、视频等。
📄 摘要(原文)
A significant
modality gap" exists between the abundance of text-only data and the increasing power of multimodal models. This work systematically investigates whether images generated on-the-fly by Text-to-Image (T2I) models can serve as a valuable complementary modality for text-centric tasks. Through a comprehensive evaluation framework on text classification, we analyze the impact of critical variables, including T2I model quality, prompt engineering strategies, and multimodal fusion architectures. Our findings demonstrate that thissynthetic perception" can yield significant performance gains, even when augmenting strong large language model baselines. However, we find the effectiveness of this approach is highly conditional, depending critically on the semantic alignment between text and the generated image, the inherent ``visual groundability" of the task, and the generative fidelity of the T2I model. Our work establishes the first rigorous benchmark for this paradigm, providing a clear analysis of its potential and current limitations, and demonstrating its viability as a pathway to enrich language understanding in traditionally unimodal scenarios.