DRAMA-X: A Fine-grained Intent Prediction and Risk Reasoning Benchmark For Driving
作者: Mihir Godbole, Xiangbo Gao, Zhengzhong Tu
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-06-21 (更新: 2025-08-09)
备注: 19 pages, 5 figures, Preprint under review. Code available at: https://github.com/taco-group/DRAMA-X
💡 一句话要点
DRAMA-X:提出用于驾驶场景的细粒度意图预测与风险推理基准
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 意图预测 风险评估 场景图 视觉-语言模型
📋 核心要点
- 现有方法在安全关键场景下,缺乏对弱势道路使用者细粒度意图预测的有效基准测试。
- 提出DRAMA-X基准,通过自动标注流程,提供细粒度的意图、风险和行动建议标注,用于评估模型。
- SGG-Intent框架利用场景图和大型语言模型进行组合推理,提升了意图预测和风险评估的性能。
📝 摘要(中文)
为了安全地实现自动驾驶,尤其是在城市环境中,理解行人、骑自行车者等弱势道路使用者(VRU)的短期运动至关重要。尽管视觉-语言模型(VLM)已经实现了开放词汇感知,但它们在细粒度意图推理方面的效用仍有待探索。目前还没有基准能够评估安全关键场景中的多类别意图预测。为了解决这个问题,我们引入了DRAMA-X,这是一个通过自动标注流程从DRAMA数据集构建的细粒度基准。DRAMA-X包含5686个易发生事故的帧,标注了对象边界框、九类方向意图分类、二元风险评分、专家为自车生成的行动建议以及描述性运动摘要。这些标注支持对自动驾驶决策至关重要的四个相互关联的任务进行结构化评估:对象检测、意图预测、风险评估和行动建议。作为参考基线,我们提出了SGG-Intent,这是一个轻量级的、无需训练的框架,它模拟了自车的推理流程。它使用VLM支持的检测器从视觉输入中顺序生成场景图,推断意图,评估风险,并使用大型语言模型驱动的组合推理阶段推荐行动。我们评估了一系列最新的VLM,比较了所有四个DRAMA-X任务的性能。实验表明,基于场景图的推理增强了意图预测和风险评估,尤其是在显式建模上下文线索时。
🔬 方法详解
问题定义:论文旨在解决自动驾驶场景中,尤其是城市复杂环境中,对弱势道路使用者(VRU)的细粒度意图预测和风险评估问题。现有方法缺乏针对此类场景的专用基准,难以有效评估和提升模型性能。此外,现有方法在利用上下文信息进行推理方面存在不足,导致意图预测和风险评估的准确性受限。
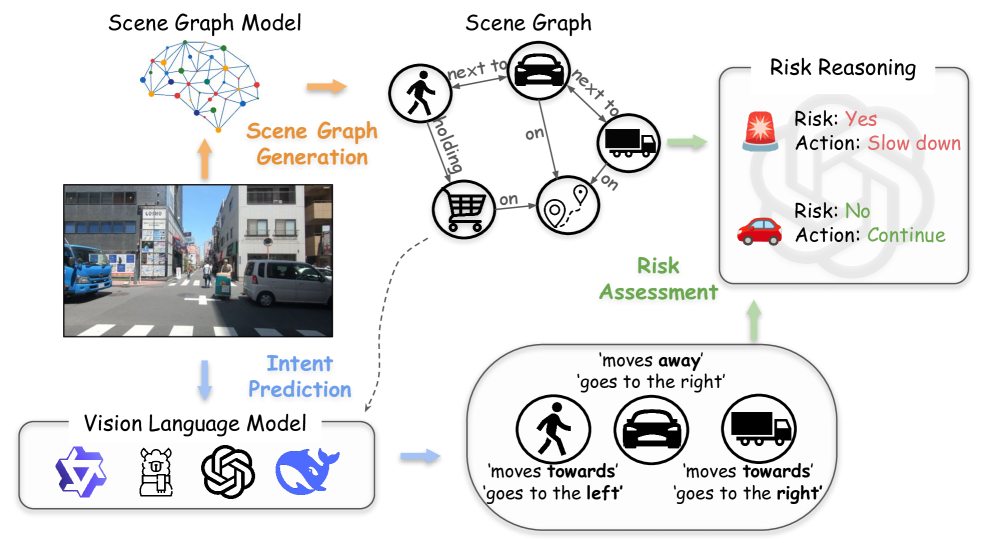
核心思路:论文的核心思路是构建一个包含丰富标注的细粒度基准DRAMA-X,并提出一个基于场景图和大型语言模型的推理框架SGG-Intent。DRAMA-X提供细粒度的意图、风险和行动建议标注,为模型训练和评估提供了高质量的数据。SGG-Intent通过场景图显式建模上下文信息,利用大型语言模型进行组合推理,从而提升意图预测和风险评估的准确性。
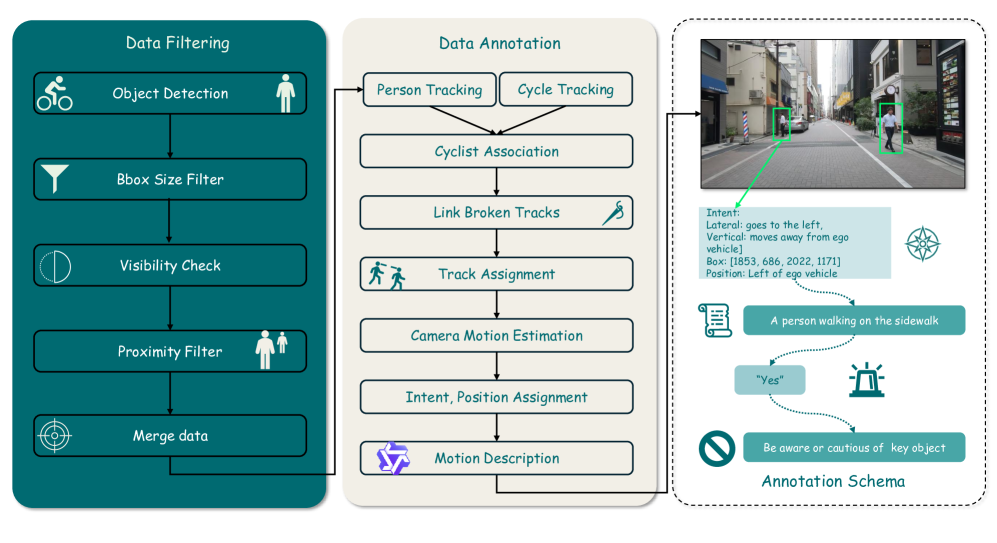
技术框架:SGG-Intent框架包含以下主要模块:1) 使用VLM支持的检测器从视觉输入中提取对象及其属性;2) 构建场景图,表示对象之间的关系;3) 利用场景图进行意图预测;4) 基于意图预测结果进行风险评估;5) 使用大型语言模型生成行动建议。整个流程模拟了自车的推理过程,实现了端到端的意图预测、风险评估和行动建议。
关键创新:论文的关键创新在于:1) 构建了DRAMA-X基准,填补了现有研究在细粒度意图预测和风险推理基准方面的空白;2) 提出了SGG-Intent框架,通过场景图显式建模上下文信息,并利用大型语言模型进行组合推理,从而提升了意图预测和风险评估的准确性。与现有方法相比,SGG-Intent能够更好地利用上下文信息,进行更准确的意图预测和风险评估。
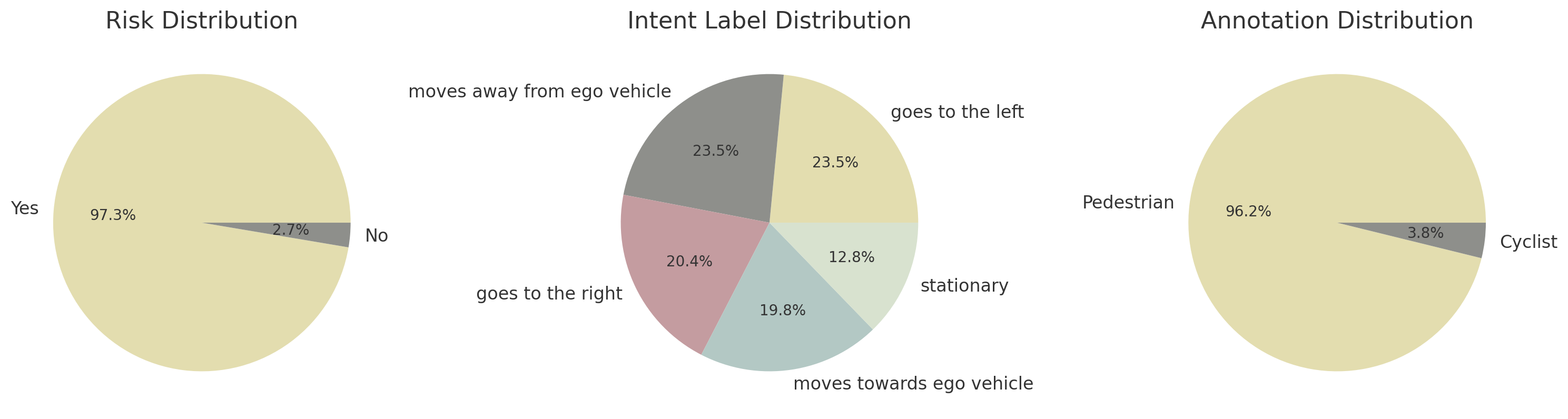
关键设计:DRAMA-X基准包含5686个事故易发帧,标注了对象边界框、九类方向意图分类、二元风险评分、专家为自车生成的行动建议以及描述性运动摘要。SGG-Intent框架使用VLM支持的检测器提取对象及其属性,并使用关系预测模型构建场景图。大型语言模型用于生成行动建议,其具体参数设置和训练细节未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SGG-Intent框架在DRAMA-X基准上取得了显著的性能提升。通过显式建模上下文信息和利用大型语言模型进行组合推理,SGG-Intent在意图预测和风险评估方面优于其他基线方法。具体的性能数据和提升幅度未知,但实验结果表明基于场景图的推理能够有效增强意图预测和风险评估。
🎯 应用场景
该研究成果可应用于自动驾驶系统,提升其在复杂城市环境中对弱势道路使用者意图的理解和风险的评估能力,从而提高自动驾驶的安全性。此外,DRAMA-X基准可以促进相关领域的研究,推动自动驾驶技术的进步。该研究还可能应用于智能交通系统,用于交通流量优化和事故预防。
📄 摘要(原文)
Understanding the short-term motion of vulnerable road users (VRUs) like pedestrians and cyclists is critical for safe autonomous driving, especially in urban scenarios with ambiguous or high-risk behaviors. While vision-language models (VLMs) have enabled open-vocabulary perception, their utility for fine-grained intent reasoning remains underexplored. Notably, no existing benchmark evaluates multi-class intent prediction in safety-critical situations, To address this gap, we introduce DRAMA-X, a fine-grained benchmark constructed from the DRAMA dataset via an automated annotation pipeline. DRAMA-X contains 5,686 accident-prone frames labeled with object bounding boxes, a nine-class directional intent taxonomy, binary risk scores, expert-generated action suggestions for the ego vehicle, and descriptive motion summaries. These annotations enable a structured evaluation of four interrelated tasks central to autonomous decision-making: object detection, intent prediction, risk assessment, and action suggestion. As a reference baseline, we propose SGG-Intent, a lightweight, training-free framework that mirrors the ego vehicle's reasoning pipeline. It sequentially generates a scene graph from visual input using VLM-backed detectors, infers intent, assesses risk, and recommends an action using a compositional reasoning stage powered by a large language model. We evaluate a range of recent VLMs, comparing performance across all four DRAMA-X tasks. Our experiments demonstrate that scene-graph-based reasoning enhances intent prediction and risk assessment, especially when contextual cues are explicitly modeled.