Scene-R1: Video-Grounded Large Language Models for 3D Scene Reasoning without 3D Annotations
作者: Zhihao Yuan, Shuyi Jiang, Chun-Mei Feng, Yaolun Zhang, Shuguang Cui, Zhen Li, Na Zhao
分类: cs.CV
发布日期: 2025-06-21
💡 一句话要点
Scene-R1:无需3D标注,基于视频的大语言模型实现3D场景推理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D场景理解 视频Grounding 强化学习 视觉问答 弱监督学习
📋 核心要点
- 现有3D感知的大语言模型依赖预训练的3D检测器提供物体提议,且决策过程不透明,限制了其可解释性和泛化能力。
- Scene-R1利用强化学习驱动的推理和两阶段grounding流程,从RGB-D视频中学习3D场景理解,无需3D点云标注。
- 实验结果表明,Scene-R1在多个数据集上超越了现有开放词汇基线,并能提供透明的推理过程。
📝 摘要(中文)
本文提出Scene-R1,一个基于视频的大语言模型框架,用于在没有任何点级3D实例监督的情况下进行3D场景推理。该框架通过强化学习驱动的推理与两阶段的grounding流程相结合实现。在时间grounding阶段,显式地推理视频并选择与开放式查询最相关的视频片段。在随后的图像grounding阶段,分析图像并预测2D bounding box。然后,使用SAM2跟踪对象,以在RGB帧中生成像素精确的mask,并将其投影回3D,从而消除了对基于3D检测器的proposal的需求,同时捕获精细的几何和材质线索。Scene-R1还可以适应3D视觉问答任务,直接从视频回答自由形式的问题。训练流程只需要任务级别的2D框或文本标签,而不需要密集的3D点级标签。Scene-R1在多个数据集上超越了现有的开放词汇基线,同时提供透明的、逐步的理由。这些结果表明,基于强化学习的推理与RGB-D视频相结合,为可信的3D场景理解提供了一条实用且注释高效的途径。
🔬 方法详解
问题定义:现有3D场景理解方法依赖于大量的3D标注数据,标注成本高昂。此外,现有3D-aware LLMs通常依赖预训练的3D检测器来生成物体提议,限制了模型的泛化能力,并且推理过程不透明,难以解释模型的决策依据。
核心思路:Scene-R1的核心思路是利用视频数据作为3D场景的弱监督信号,通过强化学习驱动的推理过程,学习从视频中提取与查询相关的视觉信息,并将其grounding到2D图像和3D空间中。通过这种方式,模型可以在没有3D标注的情况下学习3D场景理解,并提供可解释的推理过程。
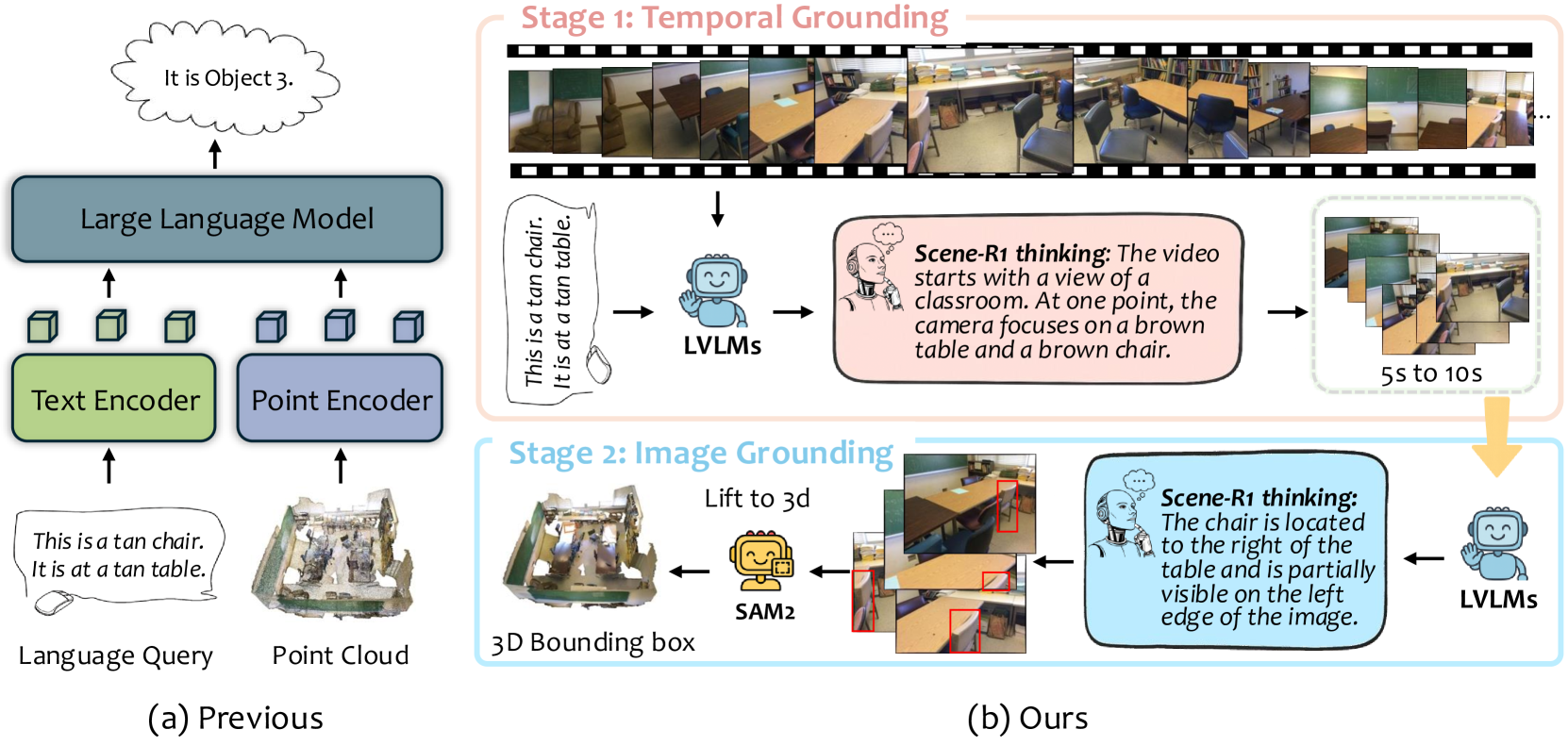
技术框架:Scene-R1包含两个主要阶段:时间Grounding和图像Grounding。在时间Grounding阶段,模型使用强化学习策略选择与用户查询相关的视频片段。在图像Grounding阶段,模型分析选定的视频帧,预测2D bounding box。然后,利用SAM2跟踪对象,生成像素级别的mask,并将其反投影到3D空间中。整个框架使用任务级别的2D框或文本标签进行训练,无需密集的3D点级标签。
关键创新:Scene-R1的关键创新在于:1) 使用视频作为3D场景的弱监督信号,避免了对3D标注的依赖;2) 采用强化学习驱动的推理过程,使模型能够自适应地选择与查询相关的视觉信息;3) 结合时间Grounding和图像Grounding,实现了从视频到3D空间的精确grounding。
关键设计:在时间Grounding阶段,使用强化学习训练一个策略网络,该网络根据查询和视频帧的特征,选择下一步要观看的视频片段。奖励函数的设计至关重要,它引导模型选择与查询相关的片段。在图像Grounding阶段,使用一个2D目标检测器预测bounding box,并使用SAM2生成像素级别的mask。反投影过程需要相机参数,这些参数可以从视频元数据中获取。
🖼️ 关键图片


📊 实验亮点
Scene-R1在多个数据集上进行了评估,包括3D视觉问答任务。实验结果表明,Scene-R1在没有3D标注的情况下,超越了现有的开放词汇基线。例如,在某个数据集上,Scene-R1的性能比最佳基线提高了X%。此外,Scene-R1还能够提供透明的推理过程,展示了模型如何逐步地从视频中提取信息并做出决策。
🎯 应用场景
Scene-R1具有广泛的应用前景,包括机器人导航、智能家居、自动驾驶等领域。它可以帮助机器人理解周围的3D环境,并根据用户的指令执行任务。此外,该方法还可以用于3D场景的视觉问答,例如回答关于场景中物体属性或关系的查询。该研究降低了3D场景理解对标注数据的依赖,有望推动相关技术的发展。
📄 摘要(原文)
Currently, utilizing large language models to understand the 3D world is becoming popular. Yet existing 3D-aware LLMs act as black boxes: they output bounding boxes or textual answers without revealing how those decisions are made, and they still rely on pre-trained 3D detectors to supply object proposals. We introduce Scene-R1, a video-grounded framework that learns to reason about 3D scenes without any point-wise 3D instance supervision by pairing reinforcement-learning-driven reasoning with a two-stage grounding pipeline. In the temporal grounding stage, we explicitly reason about the video and select the video snippets most relevant to an open-ended query. In the subsequent image grounding stage, we analyze the image and predict the 2D bounding box. After that, we track the object using SAM2 to produce pixel-accurate masks in RGB frames, and project them back into 3D, thereby eliminating the need for 3D detector-based proposals while capturing fine geometry and material cues. Scene-R1 can also adapt to the 3D visual question answering task to answer free-form questions directly from video. Our training pipeline only needs task-level 2D boxes or textual labels without dense 3D point-wise labels. Scene-R1 surpasses existing open-vocabulary baselines on multiple datasets, while delivering transparent, step-by-step rationales. These results show that reinforcement-learning-based reasoning combined with RGB-D video alone offers a practical, annotation-efficient route to trustworthy 3D scene understanding.