Not All Tokens and Heads Are Equally Important: Dual-Level Attention Intervention for Hallucination Mitigation
作者: Lexiang Tang, Xianwei Zhuang, Bang Yang, Zhiyuan Hu, Hongxiang Li, Lu Ma, Jinghan Ru, Yuexian Zou
分类: cs.CV
发布日期: 2025-06-14 (更新: 2025-08-18)
💡 一句话要点
提出VisFlow,通过双层注意力干预缓解大型视觉语言模型中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言模型 视觉幻觉 注意力机制 注意力干预 多模态融合
📋 核心要点
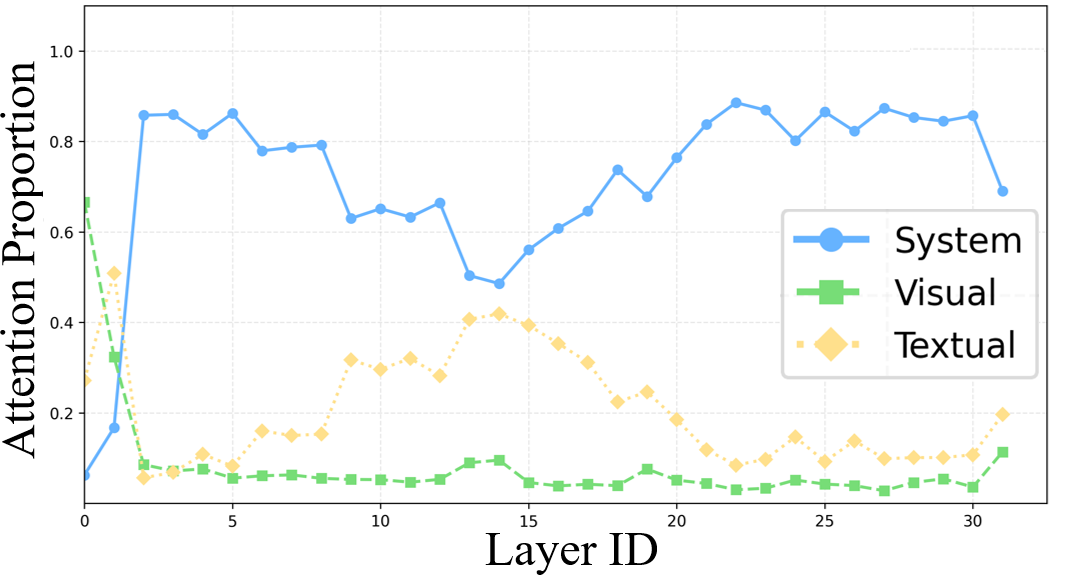
- 大型视觉语言模型易受视觉幻觉影响,产生不准确的视觉内容描述,现有方法难以有效缓解。
- VisFlow通过双层注意力干预,调节token和head的注意力模式,增强视觉对齐并减少语言偏差。
- 实验表明,VisFlow能有效缓解幻觉,且计算开销小,在多种模型和基准测试中均有提升。
📝 摘要(中文)
大型视觉语言模型(LVLMs)在各种多模态任务中表现出令人印象深刻的能力,但它们仍然极易产生视觉幻觉(VH),经常对视觉内容产生自信但不准确的描述。基于并非所有token和注意力头对缓解VH的贡献都相同的洞察,我们引入了VisFlow,这是一个轻量级且无需训练的框架,通过在推理过程中直接调节注意力模式来缓解幻觉。为了解决VH的两个主要挑战,即视觉注意力不足和语言先验的支配,我们识别出LVLMs中的三种有问题的注意力行为:(1)对无信息或尾随视觉token不成比例地分配注意力,(2)过度依赖先前生成的token,以及(3)过度关注阻碍多模态融合的系统提示。为了克服这些问题,VisFlow引入了一种双层注意力干预,包括token级注意力干预(TAI),它增强了对显著视觉区域的注意力,以及头级注意力干预(HAI),它抑制了对系统提示和相邻文本token的不当关注。这些干预共同加强了视觉对齐,同时减少了语言偏差。在各种模型和基准上的大量实验表明,VisFlow有效地缓解了幻觉,且计算开销极小。
🔬 方法详解
问题定义:论文旨在解决大型视觉语言模型(LVLMs)中存在的视觉幻觉(VH)问题,即模型对视觉内容产生自信但不准确的描述。现有方法通常难以有效缓解VH,因为它们没有充分考虑到不同token和attention head对VH的影响程度不同。模型容易过度关注无信息视觉token、先前生成的token以及系统提示,导致视觉信息利用不足和语言先验的过度影响。
核心思路:VisFlow的核心思路是通过直接干预LVLMs的注意力机制,在推理阶段动态调整token和head的注意力权重,从而缓解视觉幻觉。该方法的核心在于识别并纠正LVLMs中三种有问题的注意力行为:过度关注无信息视觉token、过度依赖先前生成的token以及过度关注系统提示。通过增强对显著视觉区域的关注,并抑制对语言先验的过度依赖,VisFlow旨在提升模型对视觉内容的理解和描述准确性。
技术框架:VisFlow采用双层注意力干预框架,包含Token-level Attention Intervention (TAI) 和 Head-level Attention Intervention (HAI)两个主要模块。TAI负责增强对显著视觉区域的注意力,通过重新分配token的注意力权重,突出重要视觉信息。HAI负责抑制对系统提示和相邻文本token的过度关注,通过调整head的注意力权重,减少语言先验的干扰。这两个模块协同工作,共同提升视觉对齐和描述准确性。整个框架无需训练,可以直接应用于现有的LVLMs。
关键创新:VisFlow的关键创新在于其双层注意力干预机制,能够精细化地调节token和head的注意力权重。与以往方法不同,VisFlow并非简单地对所有token或head进行统一处理,而是根据其对VH的影响程度进行差异化干预。这种双层干预机制能够更有效地增强视觉信息利用,减少语言先验干扰,从而显著缓解视觉幻觉。此外,VisFlow无需训练,可以直接应用于现有的LVLMs,具有良好的通用性和易用性。
关键设计:TAI的关键设计在于如何识别并增强对显著视觉区域的注意力。具体实现方式未知,可能涉及视觉显著性检测或其他注意力机制。HAI的关键设计在于如何抑制对系统提示和相邻文本token的过度关注。具体实现方式未知,可能涉及对特定head的注意力权重进行抑制或重新分配。论文中可能还涉及一些关键的参数设置,例如注意力权重调整的比例、阈值等,但具体细节未知。
🖼️ 关键图片


📊 实验亮点
论文通过大量实验验证了VisFlow的有效性,在多个基准测试中均取得了显著的性能提升。具体的性能数据和对比基线未知,但摘要中提到VisFlow在缓解幻觉的同时,计算开销极小。实验结果表明,VisFlow能够有效增强视觉对齐,减少语言偏差,从而提升视觉语言模型的描述准确性。
🎯 应用场景
VisFlow可广泛应用于各种需要视觉内容描述的场景,例如图像字幕生成、视觉问答、机器人导航等。该研究有助于提升视觉语言模型的可靠性和准确性,减少错误信息的传播,具有重要的实际应用价值。未来,该方法可以进一步扩展到视频理解、3D场景理解等更复杂的任务中。
📄 摘要(原文)
Large vision-language models (LVLMs) have demonstrated impressive capabilities across diverse multimodal tasks, yet they remain highly susceptible to visual hallucinations (VH), often producing confident but inaccurate descriptions of visual content. Building on the insight that not all tokens and attention heads contribute equally to VH mitigation, we introduce VisFlow, a lightweight and training-free framework that alleviates hallucinations by directly modulating attention patterns during inference. To address two primary challenges of VH, namely insufficient visual attention and the dominance of language priors, we identify three problematic attention behaviors in LVLMs: (1) disproportionate allocation of attention to uninformative or trailing visual tokens, (2) over-dependence on the previously generated token, and (3) excessive fixation on system prompts that hinders multimodal integration. To overcome these issues, VisFlow introduces a dual-level Attention Intervention, consisting of Token-level Attention Intervention (TAI), which reinforces attention to salient visual regions, and Head-level Attention Intervention (HAI), which suppresses undue focus on system prompts and adjacent text tokens. Together, these interventions strengthen visual alignment while reducing linguistic bias. Extensive experiments across diverse models and benchmarks demonstrate that VisFlow effectively mitigates hallucinations with minimal computational overhead.