Benchmarking the Trustworthiness in Multimodal LLMs for Video Understanding
作者: Youze Wang, Zijun Chen, Ruoyu Chen, Shishen Gu, Wenbo Hu, Jiayang Liu, Yinpeng Dong, Hang Su, Jun Zhu, Meng Wang, Richang Hong
分类: cs.CV
发布日期: 2025-06-14 (更新: 2025-11-26)
💡 一句话要点
Trust-videoLLMs:首个面向视频理解多模态LLM可信度综合评测基准
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 多模态大语言模型 可信度评估 基准测试 鲁棒性 安全性 公平性 隐私
📋 核心要点
- 现有的视频理解多模态大语言模型在处理复杂的时空数据时面临真实性、安全性等挑战。
- Trust-videoLLMs基准通过构建包含多种风险场景的视频数据集,全面评估模型在不同维度上的可信度。
- 实验结果揭示了现有模型在动态场景理解和跨模态鲁棒性方面的不足,并指出了未来改进方向。
📝 摘要(中文)
本文提出了Trust-videoLLMs,这是一个全面的基准,用于评估视频理解多模态大型语言模型(videoLLMs)的可信度。该基准评估了23个最先进的videoLLMs(5个商业模型,18个开源模型),涵盖五个关键维度:真实性、鲁棒性、安全性、公平性和隐私。Trust-videoLLMs包含30个任务,利用改编的、合成的和标注的视频,评估时空风险、时间一致性和跨模态影响。结果表明,这些模型在动态场景理解、跨模态扰动恢复和现实风险缓解方面存在显著局限性。虽然开源模型偶尔表现更好,但专有模型通常表现出更高的可信度,但模型规模的扩大并不总能提高性能。这些发现强调了增强训练数据多样性和鲁棒的多模态对齐的必要性。Trust-videoLLMs提供了一个公开可用的、可扩展的工具包,用于标准化可信度评估,解决了以准确性为中心的基准与对鲁棒性、安全性、公平性和隐私的需求之间的关键差距。
🔬 方法详解
问题定义:现有的视频理解多模态大语言模型(videoLLMs)虽然在准确性方面取得了进展,但在真实性、鲁棒性、安全性、公平性和隐私等可信度方面存在不足。缺乏一个全面的基准来评估这些模型的潜在风险和局限性,阻碍了其在实际应用中的部署。现有方法主要关注准确性,忽略了模型在面对对抗性攻击、偏见数据或隐私泄露时的表现。
核心思路:Trust-videoLLMs的核心思路是构建一个多维度的评估框架,涵盖真实性、鲁棒性、安全性、公平性和隐私五个关键维度。通过设计包含各种风险场景(如时空风险、时间不一致、跨模态干扰)的视频数据集,全面评估模型在不同维度上的表现。该基准旨在弥合准确性评估与实际应用需求之间的差距。
技术框架:Trust-videoLLMs框架包含以下主要模块:1) 数据集构建模块:收集、改编、合成和标注视频数据,以覆盖各种风险场景。2) 评估任务定义模块:设计30个评估任务,涵盖时空风险、时间一致性和跨模态影响。3) 模型评估模块:使用定义的任务评估23个最先进的videoLLMs。4) 结果分析模块:分析评估结果,揭示模型的优势和不足。
关键创新:Trust-videoLLMs的关键创新在于其综合性的可信度评估框架,它超越了传统的准确性评估,关注模型在真实世界场景中的可靠性和安全性。此外,该基准还引入了针对视频理解任务的特定风险评估,例如时空风险和时间一致性。
关键设计:Trust-videoLLMs的关键设计包括:1) 多样化的视频数据集:包含改编的、合成的和标注的视频,以覆盖各种风险场景。2) 多维度的评估指标:使用不同的指标来评估真实性、鲁棒性、安全性、公平性和隐私。3) 标准化的评估流程:提供一个公开可用的、可扩展的工具包,用于标准化可信度评估。
🖼️ 关键图片


📊 实验亮点
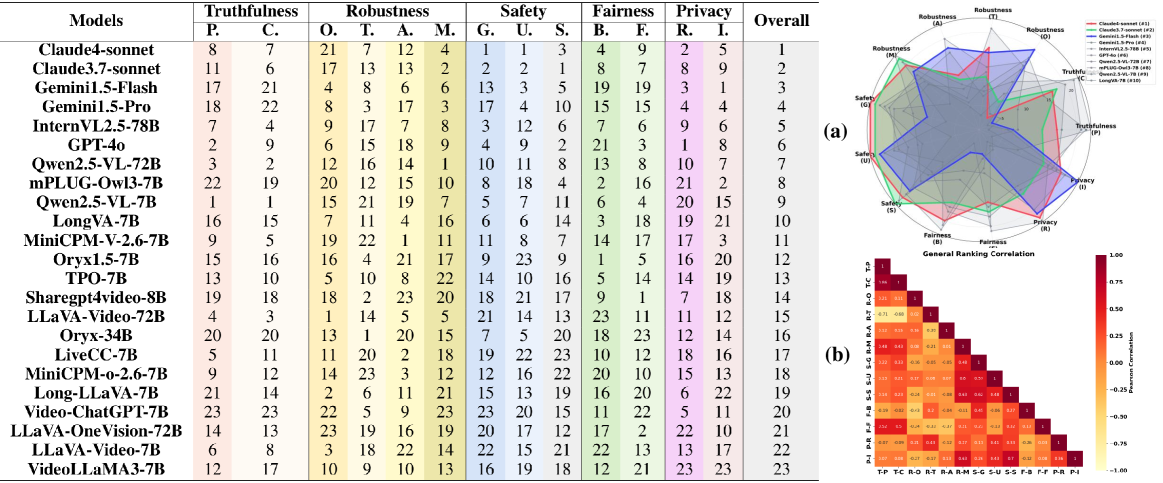
Trust-videoLLMs评估了23个最先进的videoLLMs,结果表明,这些模型在动态场景理解、跨模态扰动恢复和现实风险缓解方面存在显著局限性。虽然开源模型偶尔表现更好,但专有模型通常表现出更高的可信度。然而,模型规模的扩大并不总能提高性能,这表明需要更有效的训练策略和数据。
🎯 应用场景
Trust-videoLLMs可应用于评估和改进视频理解多模态大语言模型的可信度,从而促进其在安全监控、自动驾驶、医疗诊断等领域的应用。该基准可以帮助研究人员和开发者识别模型中的潜在风险,并开发更鲁棒、安全和公平的模型。未来,该基准可以扩展到其他模态和任务,以评估更广泛的多模态大语言模型。
📄 摘要(原文)
Recent advancements in multimodal large language models for video understanding (videoLLMs) have enhanced their capacity to process complex spatiotemporal data. However, challenges such as factual inaccuracies, harmful content, biases, hallucinations, and privacy risks compromise their reliability. This study introduces Trust-videoLLMs, a first comprehensive benchmark evaluating 23 state-of-the-art videoLLMs (5 commercial, 18 open-source) across five critical dimensions: truthfulness, robustness, safety, fairness, and privacy. Comprising 30 tasks with adapted, synthetic, and annotated videos, the framework assesses spatiotemporal risks, temporal consistency and cross-modal impact. Results reveal significant limitations in dynamic scene comprehension, cross-modal perturbation resilience and real-world risk mitigation. While open-source models occasionally outperform, proprietary models generally exhibit superior credibility, though scaling does not consistently improve performance. These findings underscore the need for enhanced training datat diversity and robust multimodal alignment. Trust-videoLLMs provides a publicly available, extensible toolkit for standardized trustworthiness assessments, addressing the critical gap between accuracy-focused benchmarks and demands for robustness, safety, fairness, and privacy.