THU-Warwick Submission for EPIC-KITCHEN Challenge 2025: Semi-Supervised Video Object Segmentation
作者: Mingqi Gao, Haoran Duan, Tianlu Zhang, Jungong Han
分类: cs.CV
发布日期: 2025-06-07
💡 一句话要点
结合SAM预训练与深度信息的半监督视频目标分割方法,提升第一人称视角下的分割精度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 视频目标分割 第一人称视角 深度信息 SAM 半监督学习 视觉预训练 几何约束
📋 核心要点
- 现有方法在处理复杂场景和长时间跨度的第一人称视角视频目标分割任务时,面临挑战,分割精度有待提升。
- 该论文提出了一种结合SAM预训练和深度信息的半监督视频目标分割方法,旨在提升复杂场景下的分割性能。
- 实验结果表明,该方法在VISOR测试集上达到了90.1%的J&F分数,验证了其有效性。
📝 摘要(中文)
本报告描述了我们针对第一人称视角视频目标分割的方法。我们的方法结合了来自SAM的大规模视觉预训练和基于深度的几何线索,以处理复杂的场景和长期跟踪。通过在一个统一的框架中整合这些信号,我们实现了强大的分割性能。在VISOR测试集上,我们的方法达到了90.1%的J&F分数。
🔬 方法详解
问题定义:论文旨在解决第一人称视角视频中的目标分割问题,尤其是在复杂场景和需要长期跟踪的情况下。现有方法可能难以有效利用场景中的几何信息,并且在长时间跨度上保持分割一致性面临挑战。
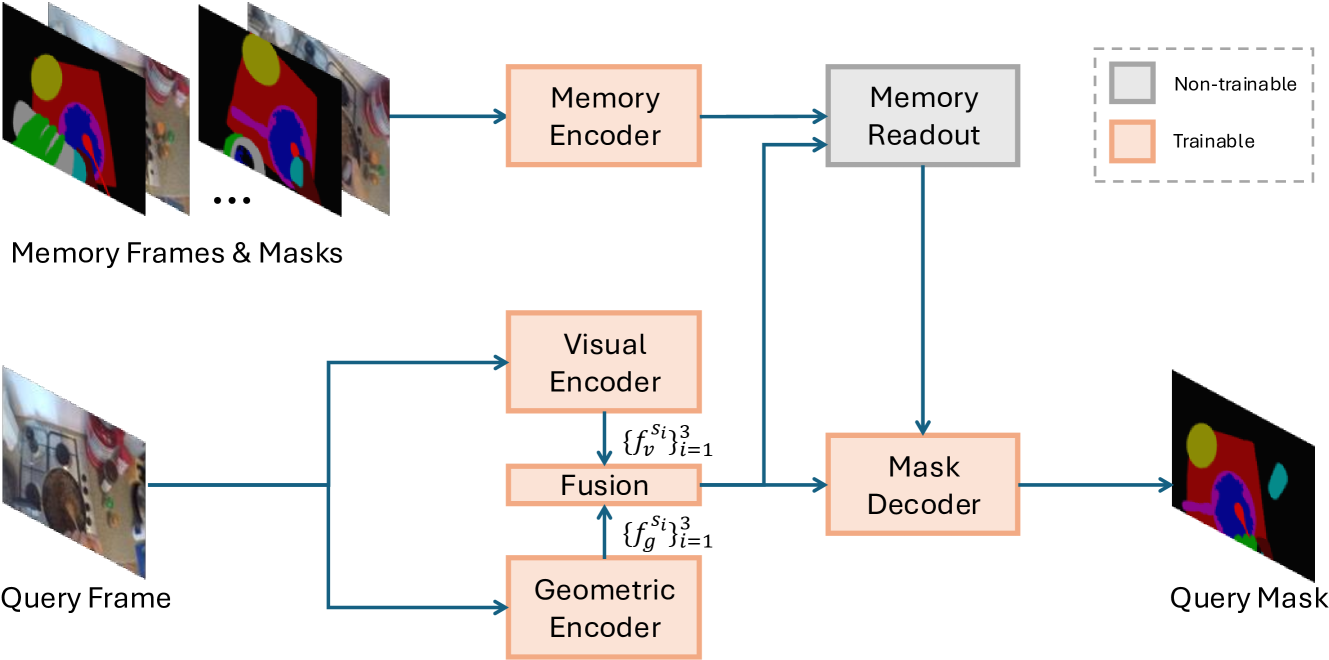
核心思路:论文的核心思路是将大规模视觉预训练模型(SAM)的强大视觉表征能力与基于深度的几何线索相结合。SAM提供了良好的初始分割,而深度信息则用于增强对场景几何结构的理解,从而提高分割的准确性和鲁棒性。
技术框架:该方法的技术框架包含两个主要组成部分:首先,利用SAM进行初步的目标分割,获得目标的视觉表征。其次,结合深度信息,例如深度图,来优化分割结果。具体流程可能包括:1) 使用SAM生成候选分割;2) 利用深度信息对候选分割进行过滤和修正,例如去除不符合几何约束的分割区域;3) 对分割结果进行时间上的平滑处理,以保证长期跟踪的一致性。
关键创新:该方法的关键创新在于将大规模预训练模型SAM与深度信息有效结合,用于视频目标分割。这种结合方式充分利用了SAM强大的视觉表征能力和深度信息提供的几何约束,从而提高了分割的准确性和鲁棒性。
关键设计:具体的关键设计细节未知,但可能包括:如何有效地将深度信息融入到SAM的分割结果中,例如通过设计特定的损失函数或网络结构;如何对深度信息进行预处理,以减少噪声的影响;以及如何对分割结果进行时间上的平滑处理,以保证长期跟踪的一致性。此外,半监督学习的具体策略也未知,例如如何利用少量标注数据来提升模型的泛化能力。
🖼️ 关键图片
📊 实验亮点
该方法在VISOR测试集上达到了90.1%的J&F分数,表明其在第一人称视角视频目标分割任务中具有很强的竞争力。该结果验证了结合大规模视觉预训练和深度信息的有效性,为未来的研究提供了有价值的参考。
🎯 应用场景
该研究成果可应用于机器人导航、增强现实、智能辅助驾驶等领域。在机器人导航中,准确的目标分割可以帮助机器人更好地理解周围环境,从而实现更精确的路径规划和目标抓取。在增强现实中,可以实现更逼真的虚拟物体与真实场景的融合。在智能辅助驾驶中,可以更准确地识别行人、车辆等目标,提高驾驶安全性。
📄 摘要(原文)
In this report, we describe our approach to egocentric video object segmentation. Our method combines large-scale visual pretraining from SAM2 with depth-based geometric cues to handle complex scenes and long-term tracking. By integrating these signals in a unified framework, we achieve strong segmentation performance. On the VISOR test set, our method reaches a J&F score of 90.1%.