State Estimation and Control of Dynamic Systems from High-Dimensional Image Data
作者: Ashik E Rasul, Hyung-Jin Yoon
分类: cs.CV
发布日期: 2025-05-30
💡 一句话要点
提出基于CNN-GRU的神经网络架构,用于高维图像数据的动态系统状态估计与控制
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 状态估计 强化学习 深度学习 卷积神经网络 循环神经网络 动态系统 图像数据
📋 核心要点
- 动态系统的精确状态估计对于最优策略设计至关重要,但直接获取真实状态通常不可行,这给策略学习带来挑战。
- 论文提出一种CNN-GRU融合的神经网络架构,从图像序列和动作中学习有效的状态表示,用于强化学习控制。
- 实验结果表明,该方法无需访问真实状态即可实现实时、准确的估计和控制,并提供了一种状态评估方法。
📝 摘要(中文)
本文提出了一种新颖的神经网络架构,该架构集成了卷积神经网络(CNN)的空间特征提取和门控循环单元(GRU)的时间建模,从而能够从图像序列和相应的动作中有效地表示状态。这些学习到的状态表示被用于训练具有深度Q网络(DQN)的强化学习智能体。实验结果表明,我们提出的方法能够实现实时、准确的估计和控制,而无需直接访问真实状态。此外,我们还提供了一种定量评估方法,用于评估学习到的状态的准确性,突出了它们对策略性能和控制稳定性的影响。
🔬 方法详解
问题定义:论文旨在解决动态系统中状态难以直接获取的问题,特别是在高维图像数据作为输入的情况下。现有方法要么依赖于可直接访问的状态信息,要么在处理高维图像数据时效率低下,难以进行精确的状态估计和控制。
核心思路:论文的核心思路是利用深度学习模型从图像序列和动作中学习状态的有效表示。通过结合CNN提取图像的空间特征和GRU建模时间序列的动态特性,模型能够捕获系统状态的关键信息,从而实现准确的状态估计和控制。
技术框架:整体架构包含两个主要模块:状态估计模块和控制模块。状态估计模块由CNN和GRU组成,CNN负责从图像中提取空间特征,GRU负责建模时间序列的动态特性,输出状态表示。控制模块使用DQN,基于学习到的状态表示进行策略学习和控制。整个流程是:图像序列和动作输入状态估计模块,输出状态表示,然后DQN基于状态表示学习控制策略。
关键创新:关键创新在于将CNN和GRU有效结合,用于从高维图像数据中学习状态表示。这种结合能够同时捕获图像的空间信息和时间序列的动态信息,从而实现更准确的状态估计。此外,论文还提出了一种定量评估学习到的状态准确性的方法。
关键设计:CNN的具体结构(层数、卷积核大小、激活函数等)和GRU的隐藏层大小是需要设计的关键参数。损失函数的设计也至关重要,可能包括状态预测误差、控制性能指标等。DQN的超参数(学习率、折扣因子、探索率等)也需要仔细调整。论文中具体参数设置未知。
🖼️ 关键图片
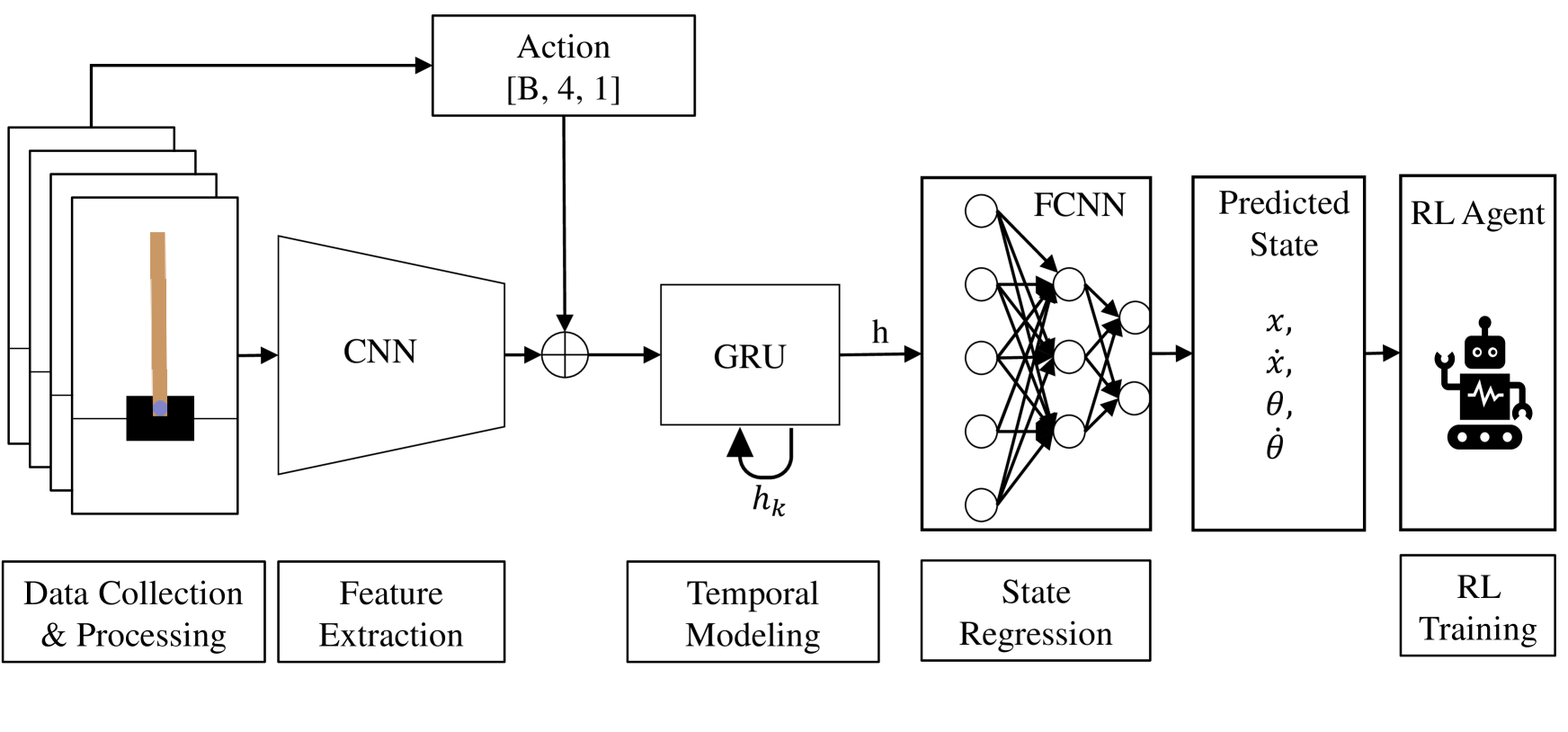

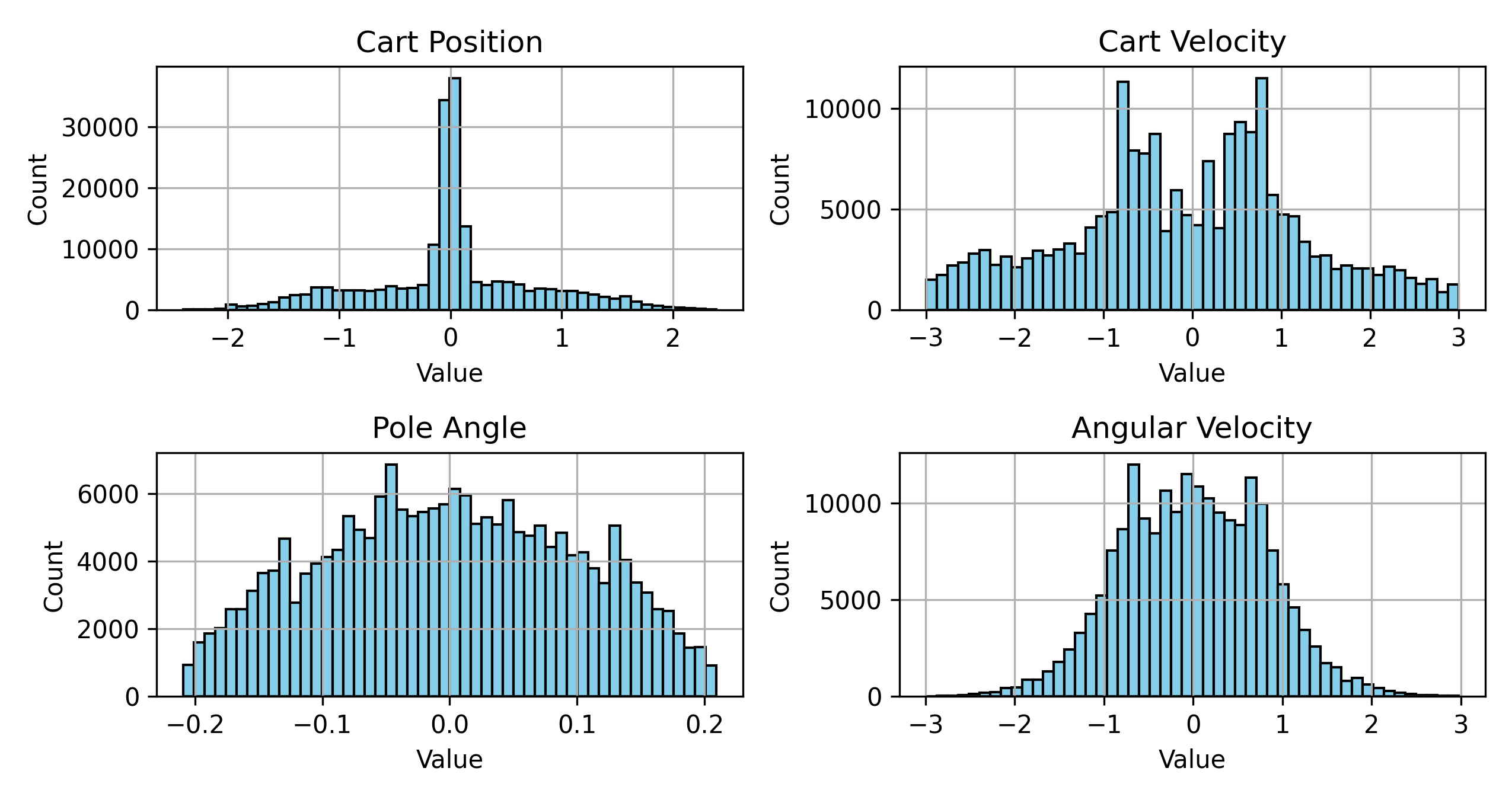
📊 实验亮点
实验结果表明,该方法能够在没有真实状态信息的情况下,实现对动态系统的实时、准确估计和控制。论文提供了一种定量评估学习到的状态准确性的方法,并验证了学习到的状态对策略性能和控制稳定性的积极影响。具体的性能提升数据未知。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、游戏AI等领域。在这些场景中,系统状态难以直接获取,但可以通过摄像头等传感器获取图像数据。该方法能够从图像数据中学习状态表示,从而实现智能体的自主控制,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Accurate state estimation is critical for optimal policy design in dynamic systems. However, obtaining true system states is often impractical or infeasible, complicating the policy learning process. This paper introduces a novel neural architecture that integrates spatial feature extraction using convolutional neural networks (CNNs) and temporal modeling through gated recurrent units (GRUs), enabling effective state representation from sequences of images and corresponding actions. These learned state representations are used to train a reinforcement learning agent with a Deep Q-Network (DQN). Experimental results demonstrate that our proposed approach enables real-time, accurate estimation and control without direct access to ground-truth states. Additionally, we provide a quantitative evaluation methodology for assessing the accuracy of the learned states, highlighting their impact on policy performance and control stability.