Ctrl-Crash: Controllable Diffusion for Realistic Car Crashes
作者: Anthony Gosselin, Ge Ya Luo, Luis Lara, Florian Golemo, Derek Nowrouzezahrai, Liam Paull, Alexia Jolicoeur-Martineau, Christopher Pal
分类: cs.CV, cs.AI, cs.RO
发布日期: 2025-05-30 (更新: 2025-12-13)
备注: Under review at Pattern Recognition Letters
💡 一句话要点
Ctrl-Crash:可控扩散模型生成逼真车辆碰撞视频,助力交通安全研究
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 可控视频生成 扩散模型 车辆碰撞模拟 交通安全 反事实推理
📋 核心要点
- 现有视频扩散模型在生成逼真车辆碰撞视频方面存在困难,主要原因是相关事故数据稀缺。
- Ctrl-Crash提出了一种可控的车辆碰撞视频生成模型,通过条件信号(如边界框、碰撞类型和初始帧)实现对生成过程的精确控制。
- 实验结果表明,Ctrl-Crash在视频质量和物理真实感方面均优于现有扩散模型,为交通安全研究提供有力工具。
📝 摘要(中文)
近年来,视频扩散技术取得了显著进展。然而,由于大多数驾驶数据集中事故事件的稀缺性,它们难以生成逼真的车辆碰撞图像。改进交通安全需要逼真且可控的事故模拟。为了解决这个问题,我们提出了Ctrl-Crash,一个可控的车辆碰撞视频生成模型,它以边界框、碰撞类型和初始图像帧等信号为条件。我们的方法能够生成反事实场景,其中输入的微小变化可能导致截然不同的碰撞结果。为了支持推理时的细粒度控制,我们利用无分类器引导,并为每个条件信号独立调整尺度。与之前的基于扩散的方法相比,Ctrl-Crash在定量视频质量指标(例如,FVD和JEDi)和基于人类评估的物理真实感和视频质量的定性测量方面,都实现了最先进的性能。
🔬 方法详解
问题定义:论文旨在解决现有视频扩散模型难以生成逼真且可控的车辆碰撞视频的问题。现有方法受限于事故数据的稀缺性,无法有效模拟各种碰撞场景,阻碍了交通安全研究的进展。
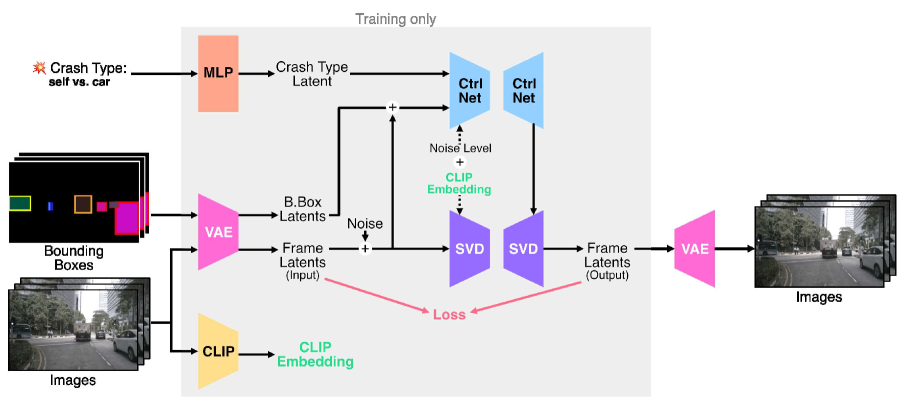
核心思路:论文的核心思路是利用可控扩散模型,通过引入额外的条件信号(如车辆边界框、碰撞类型和初始图像帧)来指导视频生成过程。这种方法允许用户在推理时对碰撞场景进行细粒度控制,从而生成各种逼真的反事实事故场景。
技术框架:Ctrl-Crash的整体框架基于扩散模型,并引入了条件控制机制。该模型主要包含以下几个模块:1) 扩散过程:将视频帧逐步加入噪声,直至完全噪声化;2) 逆扩散过程:从噪声中逐步恢复视频帧,并根据条件信号进行引导;3) 条件编码器:将边界框、碰撞类型和初始帧等条件信号编码成模型可用的特征向量;4) 无分类器引导:利用独立的尺度参数调整每个条件信号对生成过程的影响。
关键创新:该论文的关键创新在于将可控扩散模型应用于车辆碰撞视频生成,并提出了有效的条件控制方法。通过无分类器引导,用户可以独立调整每个条件信号的权重,从而实现对碰撞场景的细粒度控制。此外,该方法能够生成反事实事故场景,为交通安全研究提供了新的可能性。
关键设计:论文采用了classifier-free guidance,允许独立调整每个条件信号的尺度。具体来说,模型训练时同时学习条件模型和无条件模型,推理时通过调整两者的权重来实现对条件信号的控制。此外,论文可能还涉及特定的网络结构设计,例如用于提取车辆特征的卷积神经网络,以及用于融合不同条件信号的注意力机制(具体细节未知)。损失函数方面,除了标准的扩散模型损失外,可能还引入了额外的正则化项,以保证生成视频的物理真实性(具体细节未知)。
🖼️ 关键图片


📊 实验亮点
Ctrl-Crash在定量和定性评估中均取得了显著成果。在定量评估方面,Ctrl-Crash在FVD和JEDi等视频质量指标上优于现有扩散模型。在定性评估方面,通过人类评估,Ctrl-Crash生成的视频在物理真实感和视频质量方面均获得了更高的评分。这些结果表明,Ctrl-Crash能够生成更逼真、更可控的车辆碰撞视频。
🎯 应用场景
Ctrl-Crash具有广泛的应用前景,可用于交通安全研究、自动驾驶系统测试和驾驶员培训等领域。通过生成各种逼真的碰撞场景,研究人员可以更好地理解事故发生的原因和过程,从而制定更有效的安全策略。自动驾驶系统开发人员可以利用该模型生成大量测试用例,评估和改进系统的鲁棒性。驾驶员培训机构可以使用该模型模拟各种危险场景,提高驾驶员的安全意识和应对能力。
📄 摘要(原文)
Video diffusion techniques have advanced significantly in recent years; however, they struggle to generate realistic imagery of car crashes due to the scarcity of accident events in most driving datasets. Improving traffic safety requires realistic and controllable accident simulations. To tackle the problem, we propose Ctrl-Crash, a controllable car crash video generation model that conditions on signals such as bounding boxes, crash types, and an initial image frame. Our approach enables counterfactual scenario generation where minor variations in input can lead to dramatically different crash outcomes. To support fine-grained control at inference time, we leverage classifier-free guidance with independently tunable scales for each conditioning signal. Ctrl-Crash achieves state-of-the-art performance across quantitative video quality metrics (e.g., FVD and JEDi) and qualitative measurements based on a human-evaluation of physical realism and video quality compared to prior diffusion-based methods.