Agent-X: Evaluating Deep Multimodal Reasoning in Vision-Centric Agentic Tasks
作者: Tajamul Ashraf, Amal Saqib, Hanan Ghani, Muhra AlMahri, Yuhao Li, Noor Ahsan, Umair Nawaz, Jean Lahoud, Hisham Cholakkal, Mubarak Shah, Philip Torr, Fahad Shahbaz Khan, Rao Muhammad Anwer, Salman Khan
分类: cs.CV, cs.CL
发布日期: 2025-05-30
🔗 代码/项目: GITHUB
💡 一句话要点
Agent-X:用于评估视觉中心Agent多模态推理能力的大规模基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉Agent 多模态推理 基准测试 深度学习 工具使用 步骤级评估 真实世界数据 Agent-X
📋 核心要点
- 现有Agent基准测试通常依赖合成数据和单轮查询,无法充分评估真实场景下多步骤推理能力。
- Agent-X基准包含828个真实视觉任务,涵盖图像、视频等多种模态,并要求Agent进行逐步决策和工具使用。
- 实验结果表明,即使是GPT、Gemini等先进模型在Agent-X上的表现也远未达到理想水平,凸显了现有模型的局限性。
📝 摘要(中文)
深度推理是解决复杂任务的基础,尤其是在需要连续、多模态理解的视觉中心场景中。然而,现有的基准通常使用完全合成的、单轮查询来评估Agent,视觉模态有限,并且缺乏评估真实世界环境中所需的多步骤推理质量的框架。为了解决这个问题,我们引入了Agent-X,这是一个大规模基准,用于评估视觉中心Agent在真实世界、多模态环境中的多步骤和深度推理能力。Agent-X包含828个Agent任务,具有真实的视觉上下文,包括图像、多图像比较、视频和指导文本。这些任务涵盖六个主要的Agent环境:通用视觉推理、网页浏览、安全和监控、自动驾驶、体育和数学推理。我们的基准要求Agent在这些不同的环境中将工具使用与显式的、逐步的决策相结合。此外,我们提出了一个细粒度的、步骤级别的评估框架,该框架评估每个推理步骤的正确性和逻辑连贯性,以及整个任务中工具使用的有效性。我们的结果表明,即使是性能最佳的模型,包括GPT、Gemini和Qwen系列,也难以解决多步骤视觉任务,完整链条的成功率低于50%。这些发现突出了当前LMM推理和工具使用能力的关键瓶颈,并确定了视觉中心Agent推理模型未来的研究方向。我们的数据和代码可在https://github.com/mbzuai-oryx/Agent-X公开获取。
🔬 方法详解
问题定义:现有视觉Agent基准测试无法充分评估真实场景下的多步骤推理能力,尤其是在需要多模态信息融合和工具使用的复杂任务中。现有方法通常依赖于合成数据和单轮查询,缺乏对Agent逐步决策过程的细粒度评估。
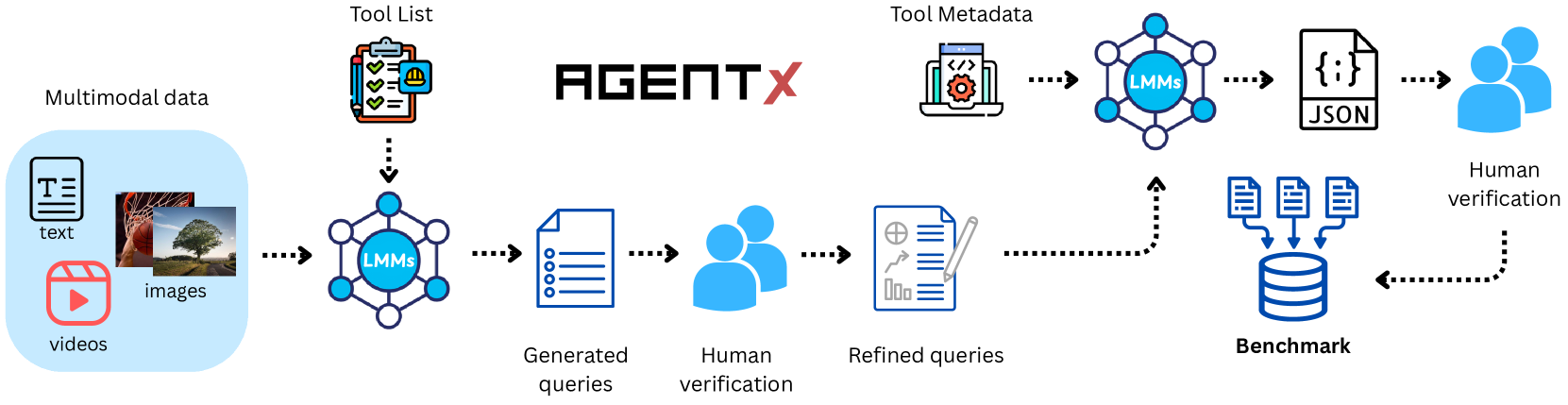
核心思路:Agent-X的核心思路是构建一个大规模、真实世界的视觉Agent基准,包含多种模态的输入(图像、视频、文本),并要求Agent在多个步骤中进行推理、决策和工具使用。通过细粒度的步骤级评估,可以更全面地了解Agent的推理能力和工具使用效果。
技术框架:Agent-X基准包含以下几个主要组成部分:1) 多样化的Agent任务:涵盖通用视觉推理、网页浏览、安全监控、自动驾驶、体育和数学推理等六个领域。2) 真实世界的视觉数据:包括图像、多图像比较、视频和指导文本,避免了合成数据的局限性。3) 逐步决策和工具使用:要求Agent在每个步骤中进行决策,并使用相应的工具来完成任务。4) 细粒度的评估框架:评估每个推理步骤的正确性和逻辑连贯性,以及工具使用的有效性。
关键创新:Agent-X的关键创新在于其大规模、真实世界的数据集,以及细粒度的步骤级评估框架。与现有基准相比,Agent-X更能够反映真实场景下Agent所面临的挑战,并提供更全面的评估结果。此外,Agent-X强调了工具使用的重要性,鼓励研究人员开发能够有效利用工具的Agent模型。
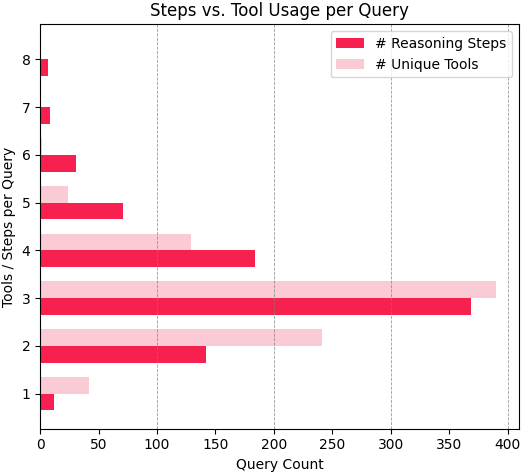
关键设计:Agent-X的数据集包含828个Agent任务,每个任务都包含多个步骤。每个步骤都包含输入(视觉数据和文本指令)、Agent的动作和输出。评估框架采用细粒度的指标,例如步骤正确率、逻辑连贯性得分和工具使用效率。具体参数设置和网络结构取决于所使用的Agent模型,但Agent-X提供了一个统一的评估平台,可以比较不同模型的性能。
🖼️ 关键图片
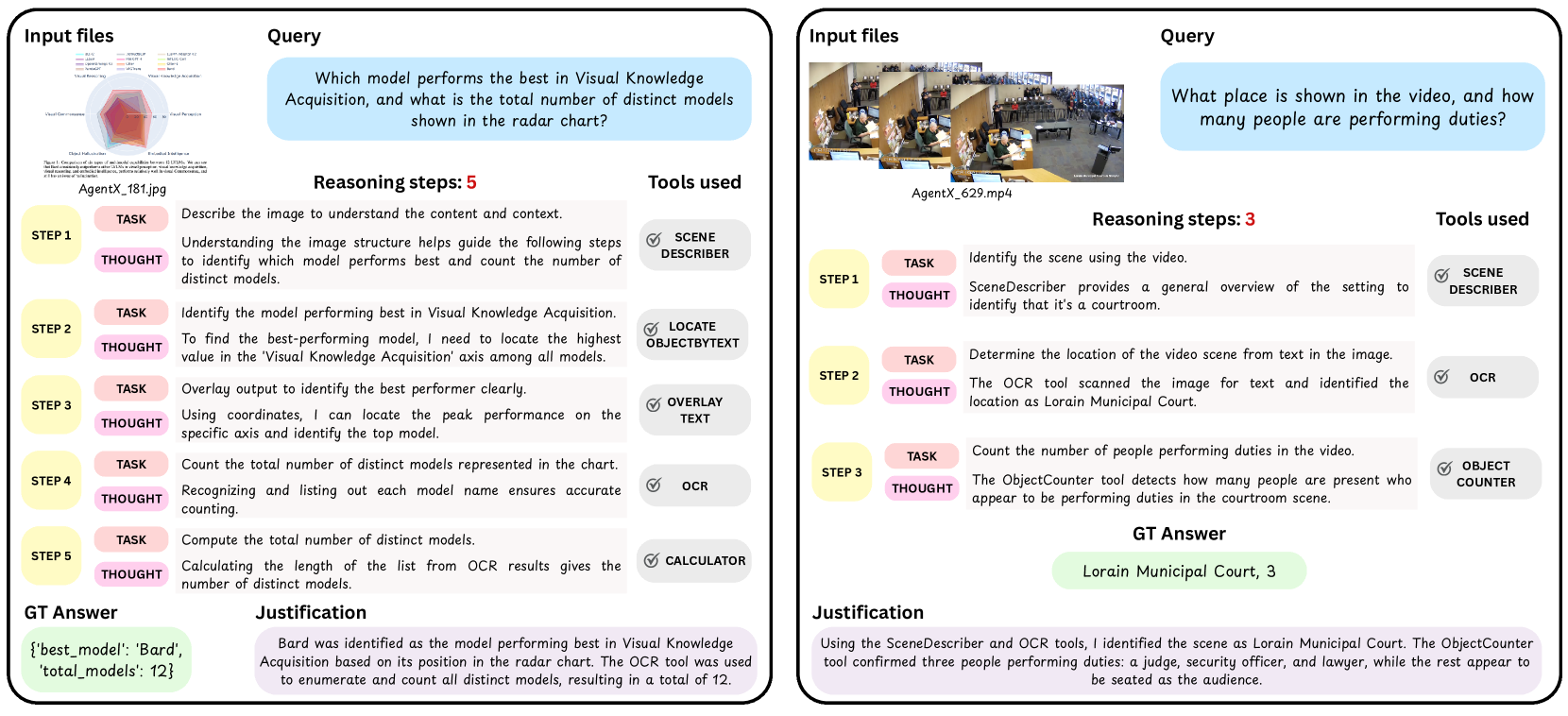
📊 实验亮点
实验结果表明,即使是GPT、Gemini和Qwen等先进模型在Agent-X上的完整链条成功率也低于50%,表明现有模型在多步骤视觉推理和工具使用方面存在显著瓶颈。该研究揭示了现有LMM在处理复杂视觉任务时的局限性,并为未来的研究方向提供了重要参考。
🎯 应用场景
Agent-X的研究成果可应用于开发更智能、更可靠的视觉Agent,例如自动驾驶系统、智能监控系统、网页浏览助手和智能客服。通过提高Agent的多模态推理能力和工具使用效率,可以实现更高级别的自动化和智能化,从而提高生产效率和改善用户体验。
📄 摘要(原文)
Deep reasoning is fundamental for solving complex tasks, especially in vision-centric scenarios that demand sequential, multimodal understanding. However, existing benchmarks typically evaluate agents with fully synthetic, single-turn queries, limited visual modalities, and lack a framework to assess reasoning quality over multiple steps as required in real-world settings. To address this, we introduce Agent-X, a large-scale benchmark for evaluating vision-centric agents multi-step and deep reasoning capabilities in real-world, multimodal settings. Agent- X features 828 agentic tasks with authentic visual contexts, including images, multi-image comparisons, videos, and instructional text. These tasks span six major agentic environments: general visual reasoning, web browsing, security and surveillance, autonomous driving, sports, and math reasoning. Our benchmark requires agents to integrate tool use with explicit, stepwise decision-making in these diverse settings. In addition, we propose a fine-grained, step-level evaluation framework that assesses the correctness and logical coherence of each reasoning step and the effectiveness of tool usage throughout the task. Our results reveal that even the best-performing models, including GPT, Gemini, and Qwen families, struggle to solve multi-step vision tasks, achieving less than 50% full-chain success. These findings highlight key bottlenecks in current LMM reasoning and tool-use capabilities and identify future research directions in vision-centric agentic reasoning models. Our data and code are publicly available at https://github.com/mbzuai-oryx/Agent-X